Real-Time Memory Management: Building Bulletproof Buffer Systems for Edge AI
Modern edge AI systems demand sophisticated memory management strategies that balance performance, reliability, and real-time constraints. When dealing with continuous thermal imaging streams, compressed visual data, and high-speed communication protocols, traditional memory allocation approaches often fall short. This deep dive explores advanced techniques for building bulletproof buffer systems that never compromise on timing guarantees.
The Memory Hierarchy Challenge in Edge AI
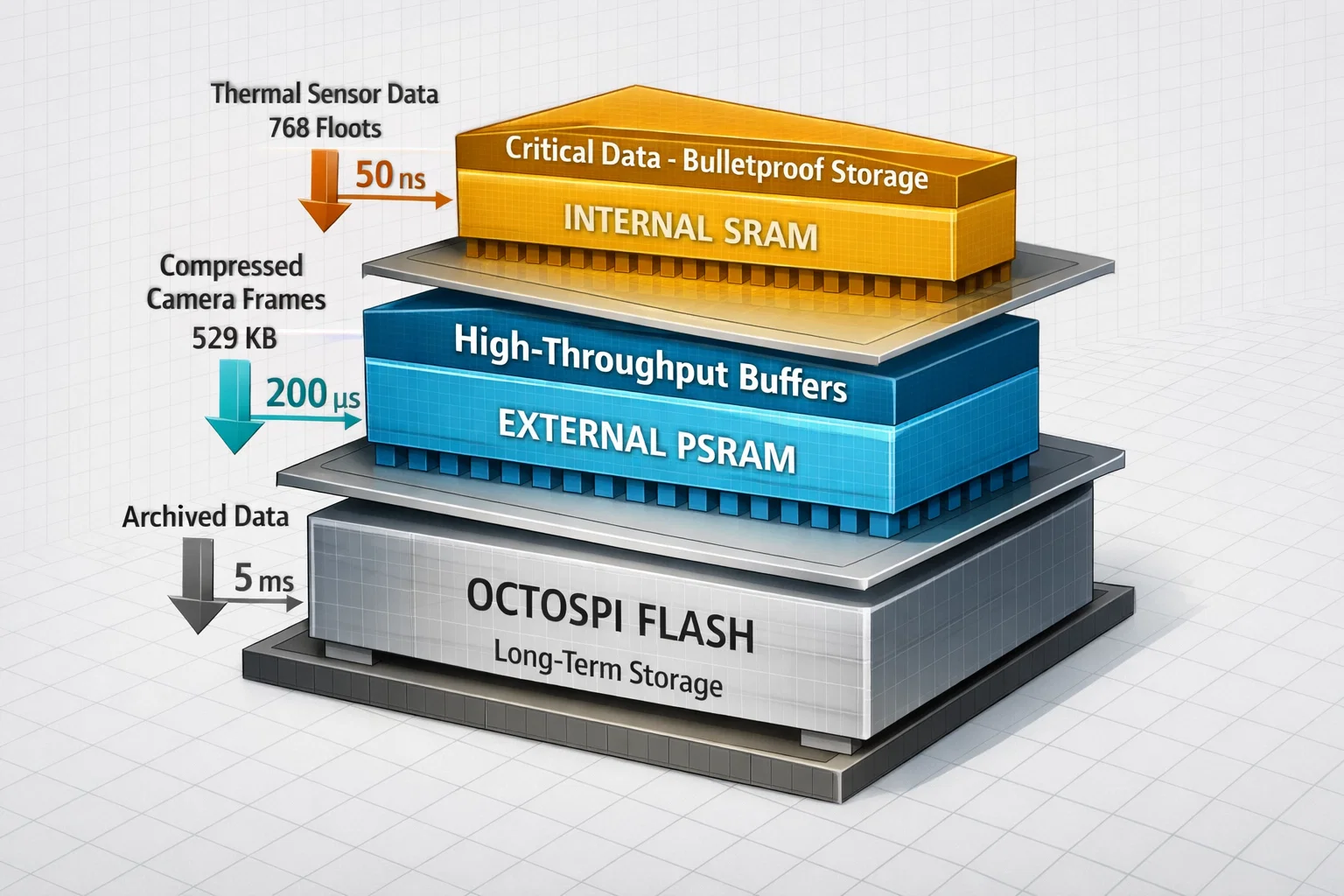
Edge AI devices operate under unique constraints: limited memory capacity, strict real-time deadlines, and the need for absolute reliability. Consider a pet health monitoring system processing thermal imagery at 30fps while simultaneously handling compressed visual data and CAN-FD communication at 5Mbps. A single memory allocation failure or timing violation could result in lost health data or false readings.
The key insight is recognizing that different data types have fundamentally different requirements. Critical thermal sensor data (768 float values representing temperature readings) demands deterministic access patterns and protection from hardware-level corruption. Meanwhile, bulk visual data (529KB compressed frames) benefits from high-capacity storage with optimized throughput.
Hardware-Aware Memory Allocation
Real-time systems must account for hardware quirks that can silently corrupt data. Modern microcontrollers like those in the embedded processor family often exhibit specific memory access patterns that can cause data alignment issues.
// CRITICAL: Thermal float data stored in SRAM to avoid 2-byte shift bug
float thermal_sram_pool[1][768] __attribute__((section(".sram")));
bool thermal_sram_in_use[1] = {false};
This approach isolates critical sensor data in internal SRAM, immune to external memory controller issues. The __attribute__((section(".sram"))) directive ensures the compiler places this data in the most reliable memory region available.
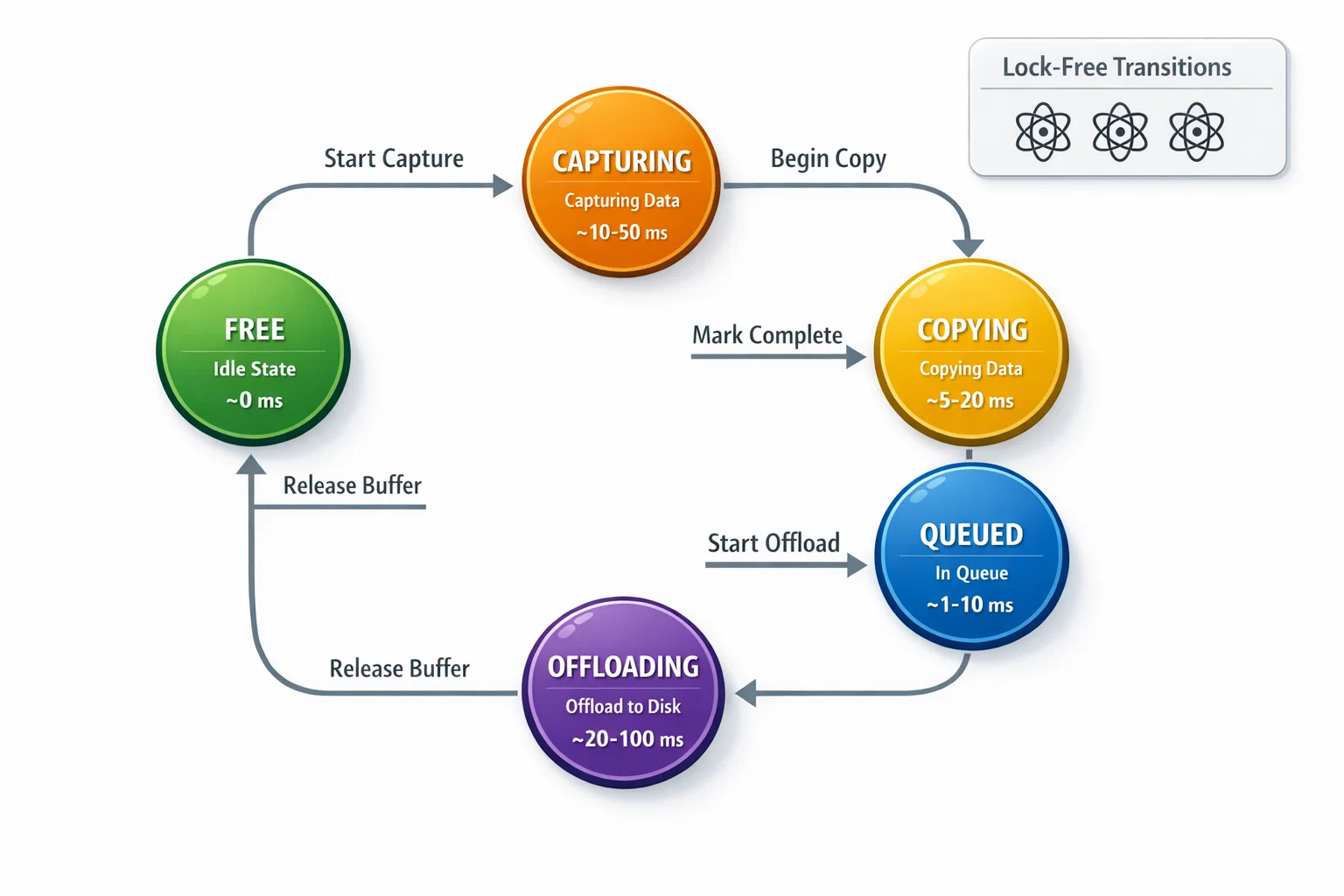
Lock-Free Buffer Management Architecture
Traditional mutex-based approaches introduce latency spikes that violate real-time constraints. A more sophisticated approach uses atomic operations and carefully designed state machines to achieve lock-free coordination between producers and consumers.
State-Driven Buffer Lifecycle
typedef enum {
BUFFER_STATE_FREE = 0,
BUFFER_STATE_CAPTURING = 1,
BUFFER_STATE_COPYING = 2,
BUFFER_STATE_QUEUED = 4,
BUFFER_STATE_OFFLOADING = 8
} buffer_state_t;
This state machine ensures buffers transition through well-defined phases without race conditions. The COPYING state prevents buffer reuse during slow PSRAM writes, while OFFLOADING coordinates with background storage operations.
// CRITICAL: Mark buffer as COPYING to prevent reuse during slow PSRAM write
if (dma_ring_buffer_mark_copying(sequence_id) != 0) {
LOG_ERROR_TAG(TAG, "Failed to mark buffer as COPYING! seq=%lu", sequence_id);
}
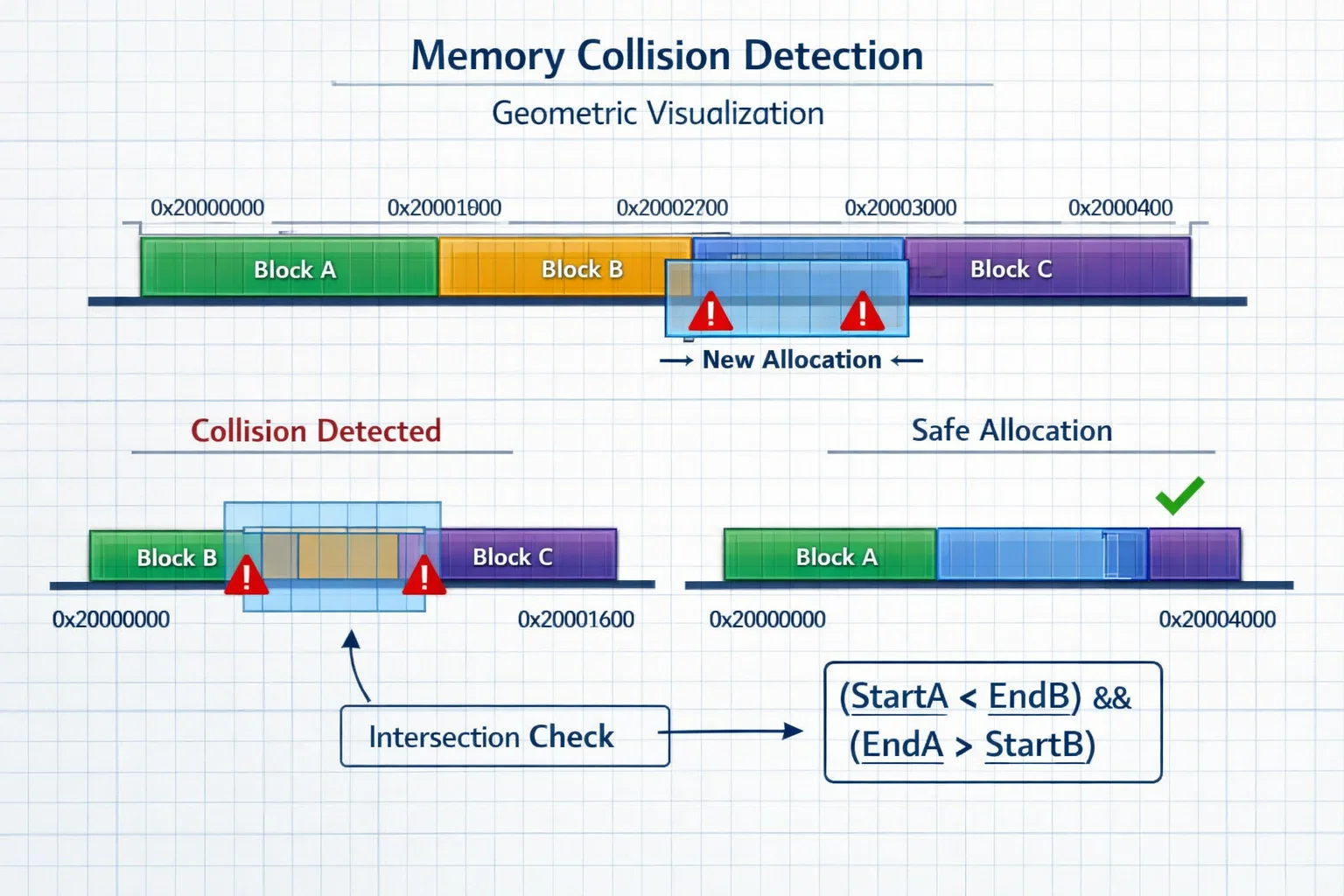
Collision Detection and Memory Protection
Advanced buffer managers implement collision detection to prevent data corruption during wrap-around scenarios:
static bool check_psram_collision(uint32_t start_offset, size_t size) {
uint32_t end_offset = start_offset + size;
for (int i = 0; i < PSRAM_THRESHOLD_ENTRIES; i++) {
if (psram_mgr.entries[i].in_use && psram_mgr.entries[i].camera_captured) {
uint32_t ent_start = psram_mgr.entries[i].camera_offset;
uint32_t ent_end = ent_start + psram_mgr.entries[i].camera_size;
// Intersection check: (StartA < EndB) && (EndA > StartB)
if (start_offset < ent_end && end_offset > ent_start) {
return true; // Collision detected
}
}
}
return false;
}
This geometric intersection algorithm ensures new data never overwrites active buffers, even during aggressive memory reuse scenarios.
DMA-Accelerated Memory Operations
Direct Memory Access transforms memory-intensive operations from CPU-blocking tasks into parallel processes. This is particularly crucial for OCTOSPI flash operations where write latencies can exceed 100ms.
Asynchronous Write Pipeline
if (HAL_XSPI_Transmit_DMA(&hospi1, (uint8_t *)current_buffer) != HAL_OK) {
LOG_ERROR_TAG(TAG, "DMA start failed at 0x%08lX", current_addr);
return -1;
}
// Wait for DMA completion via task notification
uint32_t notification_value = ulTaskNotifyTake(pdTRUE, pdMS_TO_TICKS(1000));
This approach achieves 50-60% performance improvement over CPU-based transfers while maintaining real-time responsiveness for other operations. The task notification mechanism ensures the calling thread sleeps efficiently rather than polling.

Page-Aligned Write Optimization
Flash memory operates on page boundaries (typically 256 bytes). Efficient memory management aligns writes to these boundaries and handles partial pages gracefully:
// Calculate page-aligned write size
uint32_t page_offset = current_addr % FLASH_PAGE_SIZE;
uint32_t bytes_to_write = FLASH_PAGE_SIZE - page_offset;
if (bytes_to_write > remaining) {
bytes_to_write = remaining;
}
Critical insight: Each page program operation requires a separate write enable command due to hardware limitations. The Write Enable Latch automatically clears after each page program completes.
// CRITICAL: Enable write for EACH page program
if (OSPI_WriteEnable() != HAL_OK) {
LOG_ERROR_TAG(TAG, "WriteEnable failed at page %lu", page_count);
return -1;
}
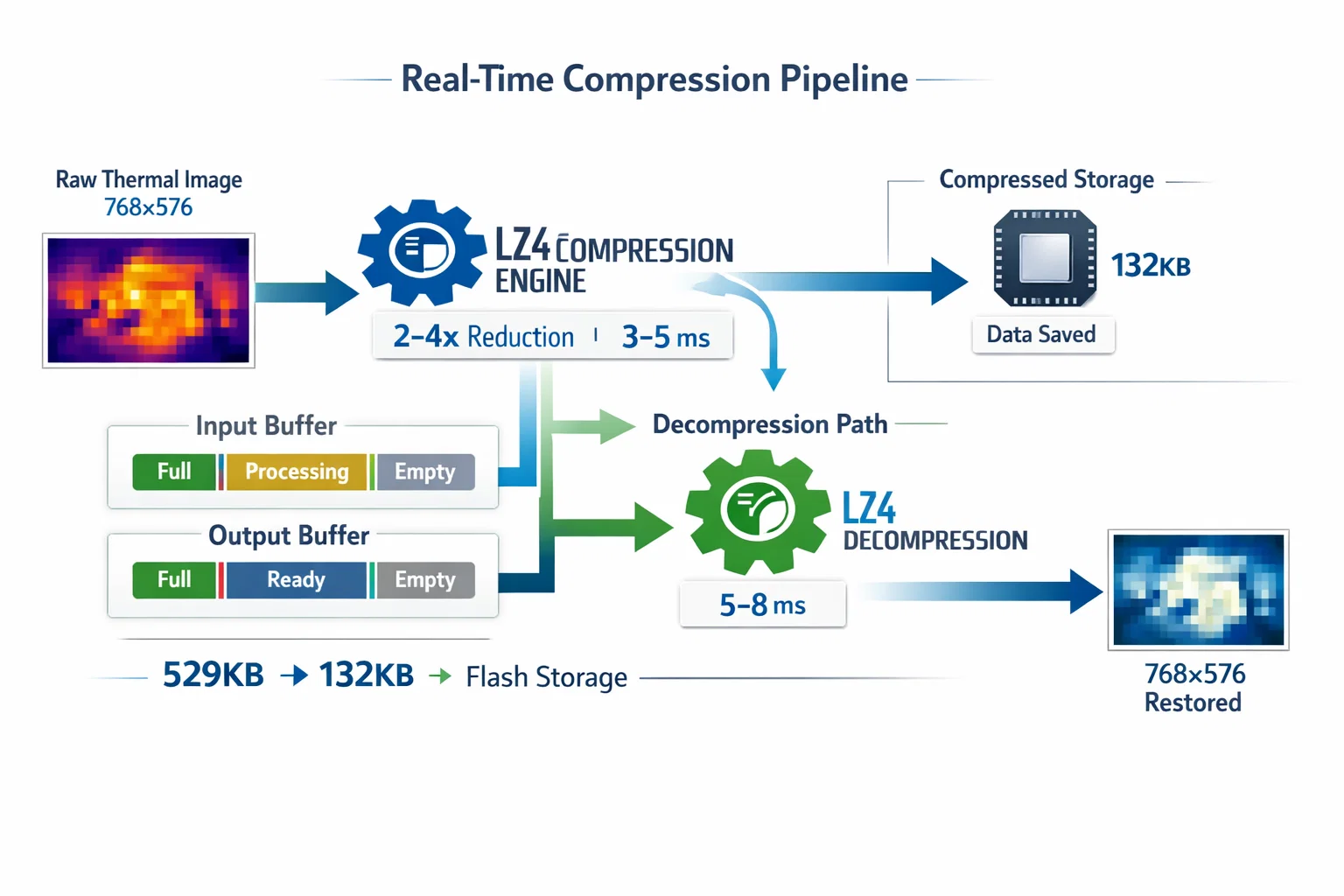
Advanced Compression Integration
Real-time compression presents unique memory management challenges. LZ4 compression offers an optimal balance between speed and compression ratio, but requires careful buffer coordination.
Streaming Compression Architecture
int camera_compress_image(const uint8_t *src, size_t src_size,
uint8_t *dst, size_t dst_capacity) {
LOG_INFO_TAG(TAG, "Starting LZ4_compress_default (%lu bytes)...", src_size);
TickType_t compress_start = xTaskGetTickCount();
int compressed_size = LZ4_compress_default((const char *)src, (char *)dst,
(int)src_size, (int)dst_capacity);
TickType_t compress_end = xTaskGetTickCount();
uint32_t compress_time = (compress_end - compress_start) * portTICK_PERIOD_MS;
float ratio = (float)src_size / compressed_size;
LOG_INFO_TAG(TAG, "Compressed %lu → %d bytes (%.2fx ratio, %lu ms)",
src_size, compressed_size, ratio, compress_time);
return compressed_size;
}
The compression bound calculation ensures destination buffers never overflow:
size_t camera_compress_bound(size_t src_size) {
return LZ4_compressBound(src_size);
}
Threshold-Based Flow Control
Sophisticated buffer management implements hysteresis to prevent capture stuttering. Simple threshold systems cause oscillation: capture until full, stop, clear one buffer, resume capture, repeat. Advanced systems use burst-aware thresholds.
Burst Hysteresis Logic
// Only resume capture if we have space for a FULL BURST (3 entries)
// This prevents "stuttering" (capture 1 -> block -> capture 1)
if (psram_mgr.entry_count <= (PSRAM_THRESHOLD_ENTRIES - BURST_SIZE) && DCMI_suspend) {
DCMI_suspend = false;
psram_mgr.threshold_reached = false;
LOG_INFO_TAG(TAG, "=== DCMI RESUMED (Burst Space Available) ===");
}
This approach ensures the system operates in distinct modes: either capturing full bursts efficiently or performing background offload operations without interference.
High-Speed Communication Memory Management
CAN-FD protocol support requires careful attention to frame size mapping and buffer allocation. Unlike traditional CAN's 8-byte limit, CAN-FD supports up to 64 bytes with specific DLC (Data Length Code) mappings.
Dynamic DLC Calculation
uint32_t GetFDCANDLC(uint8_t len) {
if (len <= 8) {
// Standard CAN compatibility
switch (len) {
case 0: return FDCAN_DLC_BYTES_0;
case 1: return FDCAN_DLC_BYTES_1;
// ... additional cases
}
} else {
// CAN FD extended lengths
if (len <= 12) return FDCAN_DLC_BYTES_12;
if (len <= 16) return FDCAN_DLC_BYTES_16;
if (len <= 20) return FDCAN_DLC_BYTES_20;
if (len <= 24) return FDCAN_DLC_BYTES_24;
if (len <= 32) return FDCAN_DLC_BYTES_32;
if (len <= 48) return FDCAN_DLC_BYTES_48;
if (len <= 64) return FDCAN_DLC_BYTES_64;
return FDCAN_DLC_BYTES_64; // Clamp to maximum
}
}
This mapping ensures optimal bandwidth utilization while maintaining compatibility with existing CAN infrastructure.

Zombie Entry Detection and Cleanup
Long-running systems must handle orphaned buffers that never complete their lifecycle. Zombie detection algorithms identify entries that fall behind the processing window.
FIFO-Ordered Cleanup Strategy
// Zombie Check - entries that are too far behind current sequence
if (max_seq > psram_mgr.entries[i].sequence_id &&
(max_seq - psram_mgr.entries[i].sequence_id) > (BURST_SIZE * 2)) {
LOG_WARN_TAG(TAG, "DETECTED ZOMBIE ENTRY[%d] seq=%lu (Current max=%lu)",
i, psram_mgr.entries[i].sequence_id, max_seq);
// Critical: Release DMA ring buffer to prevent leak
dma_ring_buffer_release(psram_mgr.entries[i].sequence_id);
psram_mgr.entries[i].in_use = false;
psram_mgr.entry_count--;
}
This cleanup mechanism prevents memory leaks while maintaining data integrity for active processing streams.
Performance Monitoring and Validation
Production memory management systems require comprehensive telemetry to detect degradation before it impacts operation.
Real-Time Performance Metrics
LOG_INFO_TAG(TAG, "[PERF] | STORAGE_NET | Seq %lu | ThermStore+Offload: %lu ms | "
"OffloadBlock: %lu ms | NetThermStore: ~%d ms |",
sequence_id, total_time, offload_duration, 10);
Key metrics include:
- Buffer allocation time: Should remain under 1ms for real-time compliance
- Compression ratios: Typical 2-4x for thermal imagery
- DMA transfer rates: Target 50-60% improvement over CPU-based transfers
- Memory utilization patterns: Track high-water marks and fragmentation
The Edge AI Connection
These advanced memory management techniques directly enable Hoomanely's vision of continuous pet health monitoring. By efficiently managing thermal imagery (fever detection), compressed visual data (activity analysis), and real-time sensor fusion, edge devices can provide 24/7 health insights without compromising system reliability.
The bulletproof buffer architecture ensures that critical health data—a pet's thermal signature indicating illness, movement patterns suggesting distress, or environmental factors affecting wellbeing—never gets lost due to memory management failures. This reliability foundation enables Hoomanely's preventive healthcare approach to transform reactive veterinary care into proactive health optimization.
Key Takeaways
Effective real-time memory management requires a multi-layered approach:
Hardware-Aware Design: Understand and work around microcontroller-specific memory quirks through strategic allocation patterns.
Lock-Free Coordination: Implement state machines and atomic operations to eliminate latency-inducing mutex operations.
DMA Integration: Leverage hardware acceleration for memory-intensive operations while maintaining CPU availability for real-time tasks.
Intelligent Flow Control: Use burst-aware thresholds and hysteresis to prevent system oscillation and optimize throughput.
Proactive Cleanup: Implement zombie detection and automated resource recovery to maintain system health over extended operation periods.
Comprehensive Monitoring: Deploy real-time telemetry to detect and address performance degradation before it impacts system operation.
These techniques transform memory management from a potential failure point into a competitive advantage, enabling sophisticated edge AI applications that operate reliably in resource-constrained environments.



