Reliable Backend Workflows on AWS: Idempotency, Retries, and Failure Modes

Modern backend systems rarely fail loudly. They fail quietly—through duplicated requests, partially completed workflows, retried executions, and replayed messages that look successful but slowly erode correctness. On AWS, these behaviors are not edge cases or misconfigurations. They are the default operating conditions of a resilient, distributed platform.
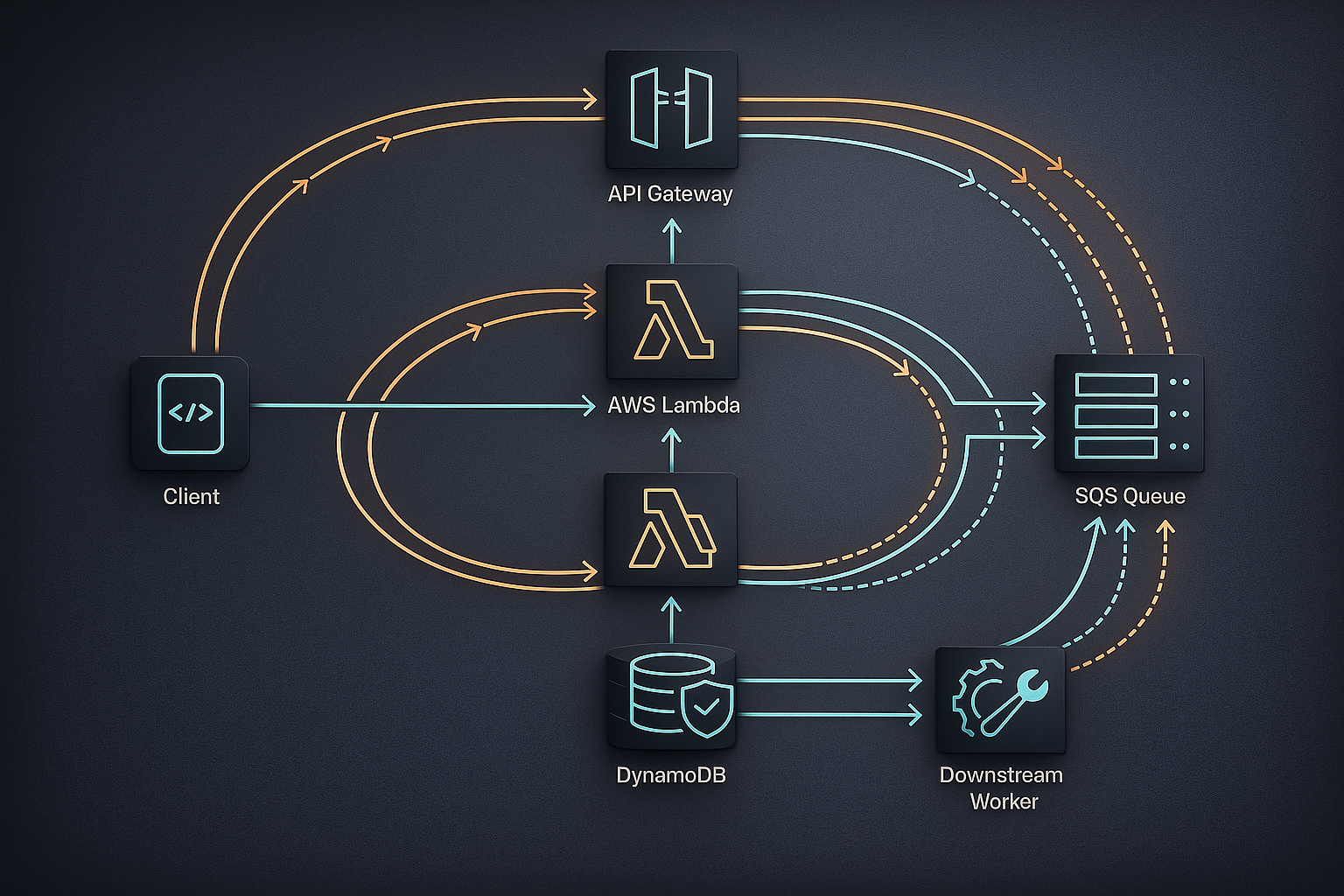
API Gateway retries requests when responses are ambiguous. AWS Lambda may re-execute handlers after timeouts or partial failures. SQS redelivers messages to guarantee durability. Mobile clients reconnect and resend actions after flaky network conditions. Each of these behaviors is individually reasonable. Together, they form an environment where backend workflows must assume duplication, reordering, and retries as normal.
This blog explores how Hoomanely designs reliable backend workflows on AWS by embracing this reality. Rather than attempting to simulate “exactly-once” execution, the focus is on building systems that remain correct under retries, partial failure, and duplication. The discussion is grounded in Python services running on AWS Lambda, DynamoDB, and queues, and reflects production patterns rather than theoretical guarantees.
The At-Least-Once Reality of AWS
AWS prioritizes durability and availability over execution purity. This design choice manifests as at-least-once delivery across many core services. A request may be processed more than once, and a message may be delivered multiple times, but the platform ensures that work is not silently dropped.
From an application perspective, this means several things happen regularly:
- A client times out and retries while the server continues processing.
- A Lambda invocation completes a write but crashes before returning a response.
- A queue message becomes visible again due to a transient worker failure.
- A Step Functions state retries automatically after a perceived failure.
These scenarios are not failures of AWS. They are signals that the application layer must be designed to tolerate re-execution.
The key mistake many systems make is assuming retries are exceptional. In reality, retries are the steady state. Correctness must be preserved even when the same logical action is processed multiple times.
Failure as a Design Input, Not an Exception Path
In many codebases, failure handling lives at the edges: catch blocks, retry decorators, or generic error handlers. This often leads to brittle systems where success paths are carefully designed, but failure paths are loosely considered.
By answering these questions early, workflows are designed to be safe under replay rather than patched after issues appear in production.
Idempotency as a System Property
Idempotency is often reduced to a single mechanism, such as storing an idempotency key in a table. While useful, this framing is incomplete. True idempotency is not an attribute of an endpoint; it is a property of the entire workflow.
A backend operation is idempotent if executing it multiple times produces the same final system state as executing it once. Achieving this requires alignment across several layers:
- Request identity must be stable.
- Writes must be conditional or fenced.
- Side effects must be guarded.
- Downstream consumers must tolerate duplication.
If any layer violates these principles, retries can leak into incorrect state.
Stable Request Identity in Python APIs
Every mutating request must carry a stable, client-defined identity that represents the logical action being performed. This identity is distinct from infrastructure-generated request IDs and must remain consistent across retries.
Common examples include action identifiers such as meal log IDs, timeline event IDs, or update transaction IDs. These identifiers are generated once on the client or upstream service and reused whenever the request is retried.
On the backend, this identity becomes the anchor for deduplication. Without it, retries are indistinguishable from new actions, and correctness becomes probabilistic.
Deduplication as a Guardrail, Not a Feature
Deduplication should not be an optional optimization. It is a guardrail that protects core state from corruption.
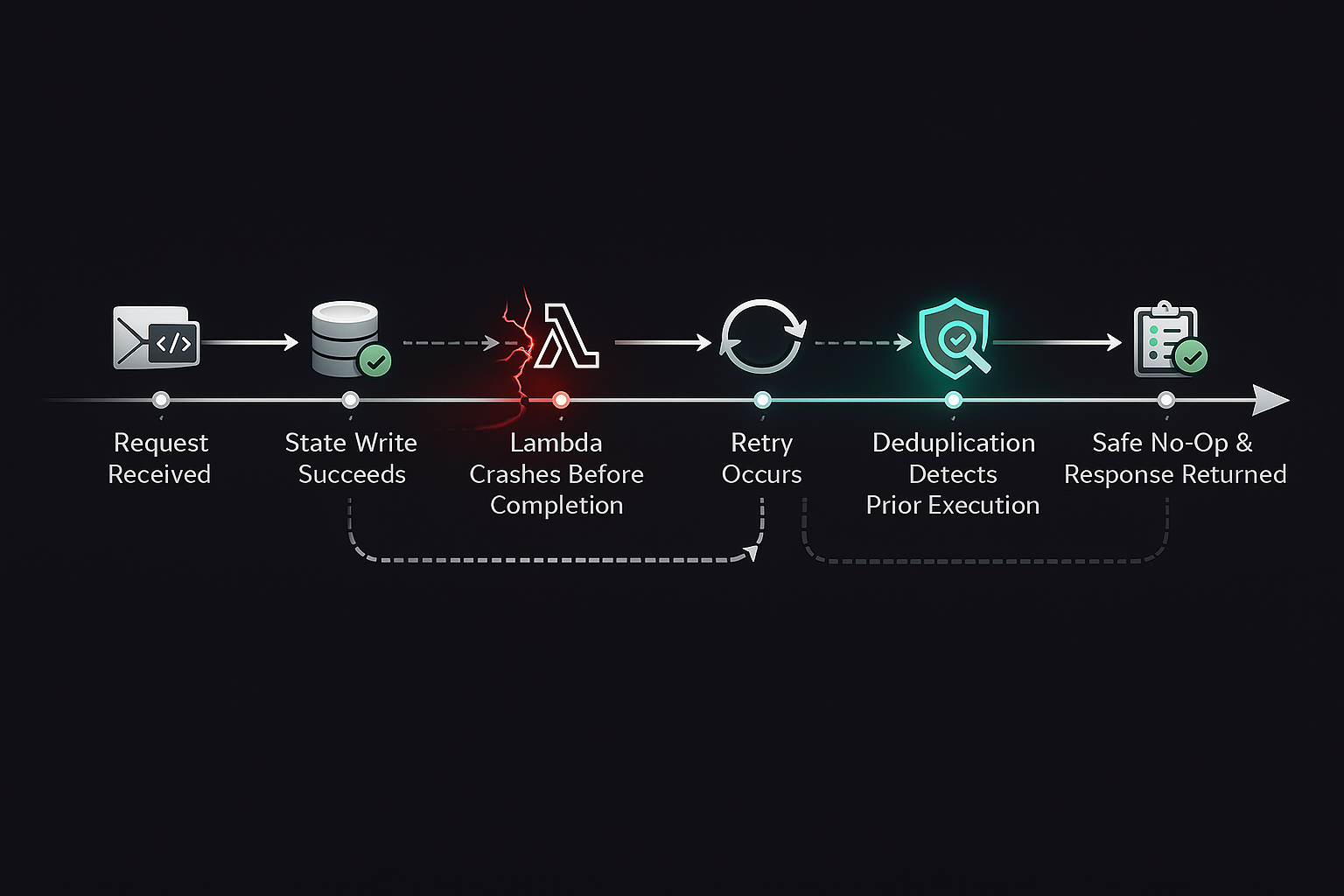
A typical pattern involves maintaining a deduplication record keyed by the action identifier and action type. When a request arrives, the backend checks whether this action has already been processed. If so, the handler short-circuits and returns the previously recorded result or a safe acknowledgment.
This approach ensures that retries do not reapply state changes, even if they occur minutes or hours later. More importantly, it decouples correctness from timing assumptions.
Conditional Writes and Storage-Level Enforcement
Application-level checks are insufficient under concurrency. Two retries may arrive simultaneously, both pass an in-memory check, and both attempt to write. Storage-level enforcement is required to close this gap.
DynamoDB conditional writes are central to this strategy. They allow writes to succeed only if specific conditions hold true, such as the absence of a record or a matching version number.
Examples of conditional enforcement include:
- Creating a record only if it does not already exist.
- Updating a record only if the expected version matches.
- Appending data only if a specific event ID has not been seen before.
These conditions ensure that retries become harmless no-ops rather than duplicated state changes.
Multi-Step Workflows and Write Fencing
Single-write operations are relatively easy to make idempotent. Multi-step workflows are more complex, particularly when steps involve different data models or side effects.
Consider a workflow that records an event, updates an aggregate, and triggers downstream fan-out. If the function crashes after the aggregate update but before fan-out, a retry may re-execute all steps, duplicating effects.
Write fencing addresses this problem by associating each execution with a unique fence or execution token. Each write checks whether it has already been applied for that fence. If so, it is skipped.
This pattern ensures that retries resume safely rather than restarting blindly. It also allows partial progress to be preserved without duplication.
Retry-Safe Background Workers
Queues and event-driven workers amplify the impact of retries. A single message can be delivered multiple times, potentially long after the original processing attempt.
Workers must assume that every message may be a replay. Visibility timeouts and retry delays are not locks or guarantees; they are best-effort coordination mechanisms.
To remain correct, background workers must:
- Treat message payloads as immutable commands.
- Use stable identifiers for deduplication.
- Guard side effects with conditional writes.
- Avoid relying on in-memory state for correctness.
These principles ensure that replayed messages do not produce duplicated or inconsistent outcomes.
Fan-Out as a Duplication Multiplier
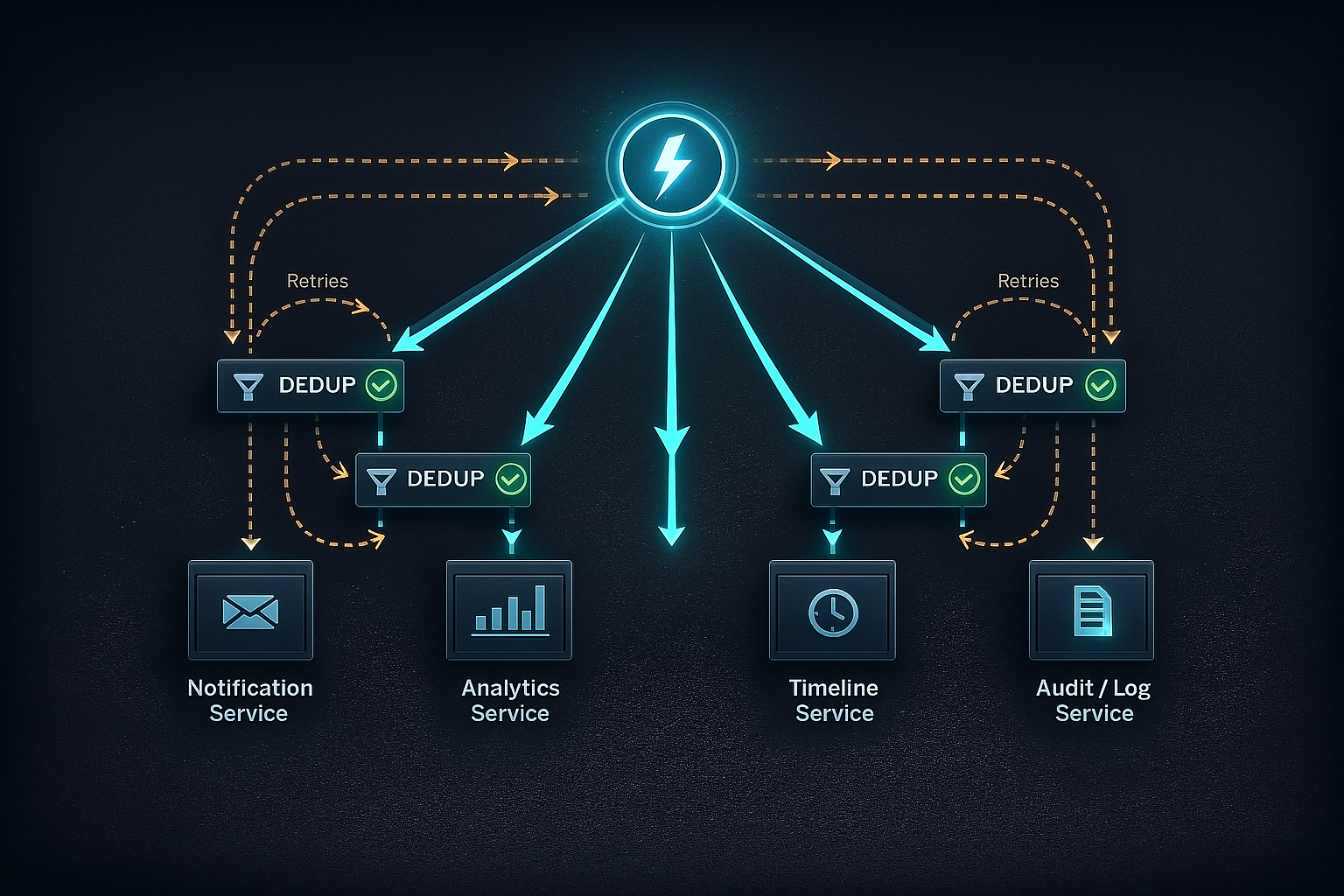
Fan-out is where retry-related bugs become most visible. A single retried action can trigger multiple notifications, duplicate analytics events, or repeated downstream updates.
To contain this, fan-out must be treated as a chain of idempotent operations rather than a single fire-and-forget step. Each downstream consumer must independently enforce deduplication based on stable identifiers.
This approach distributes correctness across the system, preventing a single failure from cascading into widespread inconsistency.
Observability of Retries and Failure Modes
Retry-safe systems are only trustworthy if retries are observable. Silent retries are dangerous because they hide failure patterns and make debugging difficult.
Key signals to monitor include retry rates, deduplication hits, conditional write failures, and replayed workflow executions. These metrics provide insight into how often the system is operating under retry conditions and whether safeguards are working as intended.
At Hoomanely, retries are logged as structured events rather than treated as errors. This allows teams to audit behavior, identify hotspots, and refine workflows without conflating retries with genuine faults.
Designing for Mobile-Induced Retries
Mobile clients are particularly retry-prone. Network interruptions, background suspensions, and user impatience all contribute to duplicate requests.
Backend workflows must assume that mobile-originated actions may be resent multiple times and may arrive out of order. Idempotency and deduplication are not optional in this context; they are fundamental to preserving user trust.
By designing backend workflows that are retry-safe by default, mobile behavior becomes predictable rather than problematic.
Explicit Failure Modes to Design For
Reliable backend systems explicitly account for common failure scenarios rather than treating them as anomalies. These include handler crashes after partial writes, concurrent retries racing each other, delayed message redelivery, and downstream timeouts.
Each of these scenarios must result in a system state that is consistent, non-duplicated, and recoverable. Achieving this requires deliberate modeling of failure modes during design, not reactive fixes after incidents.
Reliability as an Architectural Discipline
Retry-safe design is not a collection of tricks. It is an architectural discipline rooted in stable identifiers, conditional writes, idempotent side effects, and observable behavior.
At Hoomanely, these principles allow backend systems to remain correct even as AWS aggressively retries operations to preserve availability. Rather than fighting the platform, the architecture works with it.
Exactly-once execution is a comforting abstraction, but it does not reflect how distributed systems behave in production. AWS favors resilience over purity, and backend systems must be designed accordingly.
Reliable workflows are built by assuming retries, duplication, and partial failure are inevitable. Idempotency is not a feature that can be bolted on later; it is a property that emerges from careful system design. Correctness is engineered, not assumed.



