Retrieval as a Runtime Capability

Retrieval is one of the most powerful tools we have for making AI genuinely helpful—because it lets systems ground responses in real, evolving knowledge: user history, device signals, policies, docs, and live state. The catch is that retrieval is also a runtime capability. Context arrives at different speeds. Some sources update asynchronously. Latency budgets shape how deep we can go. And occasionally, the most relevant knowledge simply isn’t available in the moment.
Well-designed AI systems don’t treat that variability as a problem to hide—they treat it as a constraint to engineer around. This post explores how to build retrieval-aware AI that stays useful and trustworthy across the full spectrum of context availability: from rich, fresh evidence to partial or missing signals. The goal isn’t to always “know more,” but to respond predictably when you know less—using bounded retrieval, adaptive response modes, and stability-first behavior that preserves user trust while still moving the workflow forward.
The core shift: retrieval isn’t a dependency, it’s a variable
Most RAG pipelines behave like this:
- Retrieve top-K chunks
- Stuff context into the model
- Generate an answer
- Hope the retrieval was good enough
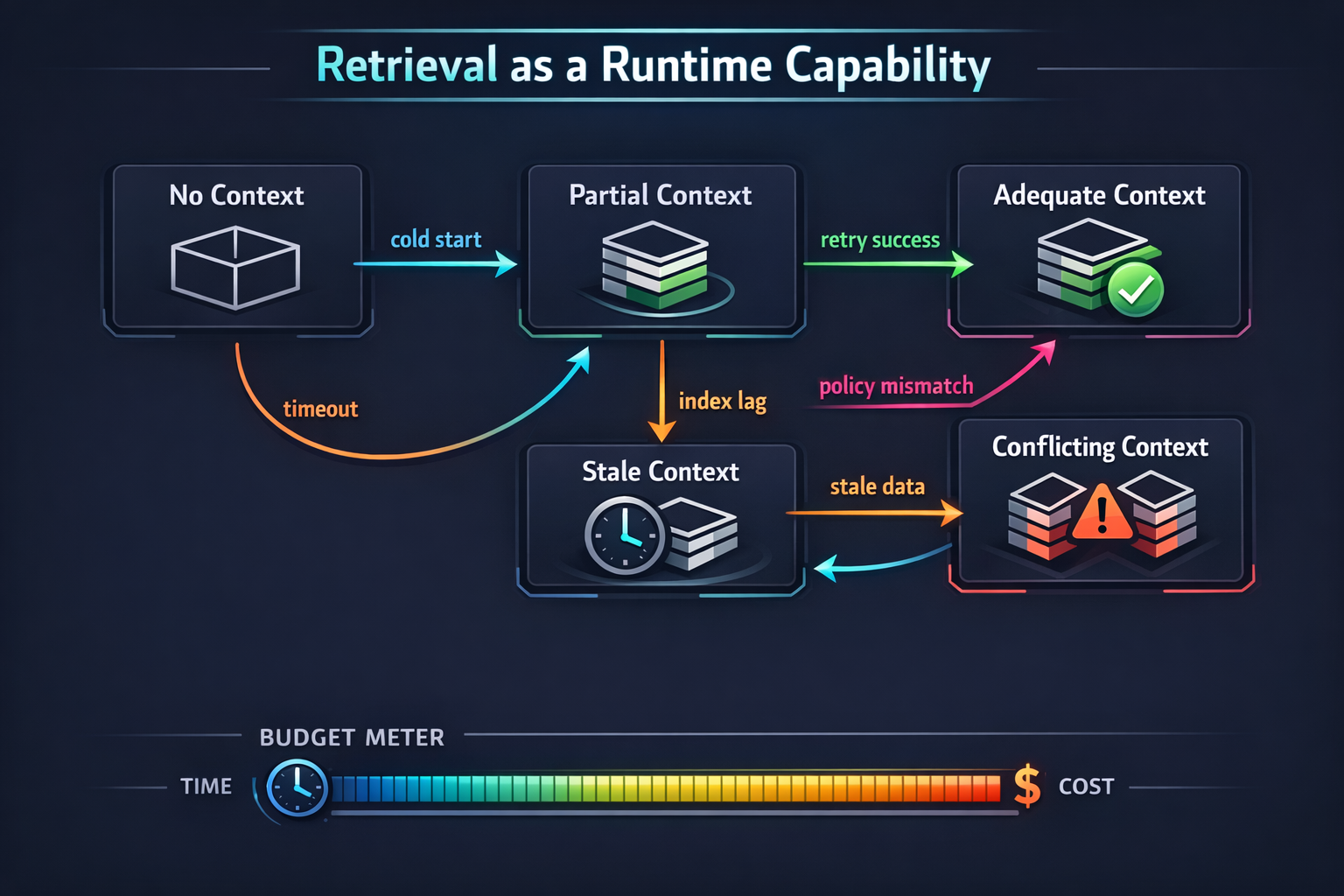
In production, step (1) is a moving target. So instead of designing around “top-K,” design around context availability as a runtime signal.
Think of retrieval quality as a vector, not a boolean:
- Completeness: did we fetch all relevant sources or just a slice?
- Freshness: how stale is the index vs the underlying source of truth?
- Coverage: do we have any user-specific data or only global docs?
- Consistency: are sources mutually compatible, or conflicting?
- Budget: how much time/cost did we spend before cutting off?
A useful system makes these variables first-class inputs into response behavior.
Why partial context is the default in production
Here are the common “context gaps” that show up at scale:
1) Sparse user reality
New users, cold starts, missing permissions, offline devices, partial onboarding—retrieval may return a handful of generic docs and nothing personal.
2) Lag and reordering
Your index updates aren’t synchronous with writes. Even if ingestion is fast, out-of-order events and delayed enrichments create short windows where retrieval lies by omission.
3) Latency is a hard wall
In interactive UX, you often have sub-second budgets. Retrieval can be cut off mid-flight, returning incomplete results or no results at all.
4) Conflicting sources
Policies say one thing, config says another, and a rollout doc says a third. Retrieval returns true statements that don’t cohere.
The stable design assumption is: context will be incomplete more often than you think.
A production-grade architecture: Retrieval-Aware Response Planning
Instead of “retrieve then answer,” add an explicit planning layer:
Pipeline
- Request classifier → determines context dependency
- Budgeter → assigns time/cost limits and stages
- Retriever → executes staged retrieval with fallbacks
- Context grader → scores adequacy/consistency
- Response planner → selects a response mode
- Generator + verifier → writes + checks claims against evidence
- UI adapter → shapes how uncertainty is communicated
This is how you make retrieval a capability the system can use—not a guarantee it requires.
Step 1: Classify requests by dependency on context
Not every question needs retrieval. A stable system starts by routing requests into intent classes that define what “safe to answer” means.
A) Context-free (safe without retrieval)
General explanations, definitions, broad best practices.
Response strategy: answer directly, optionally offer “want me to tailor this to your setup?”
B) Context-helped (better with retrieval, but not required)
“How do I debug X in our system?” when generic steps are still useful.
Response strategy: give baseline steps + ask for missing details only if necessary.
C) Context-required (unsafe without retrieval)
User/account-specific questions, configuration-dependent flows, audits, “what happened last night,” “is my device online,” etc.
Response strategy: either retrieve or refuse gracefully (with next steps).
D) Context-sensitive (answer changes if context is wrong)
Policies, security posture, billing, compliance, medical-like advice. Even if retrieval exists, it must be verified.
Response strategy: retrieve + evidence-bound output + uncertainty flags.
Key principle: Classification must happen before retrieval. Otherwise you waste budget retrieving for questions that didn’t need it—and worse, you answer context-required questions without acknowledging missing context.
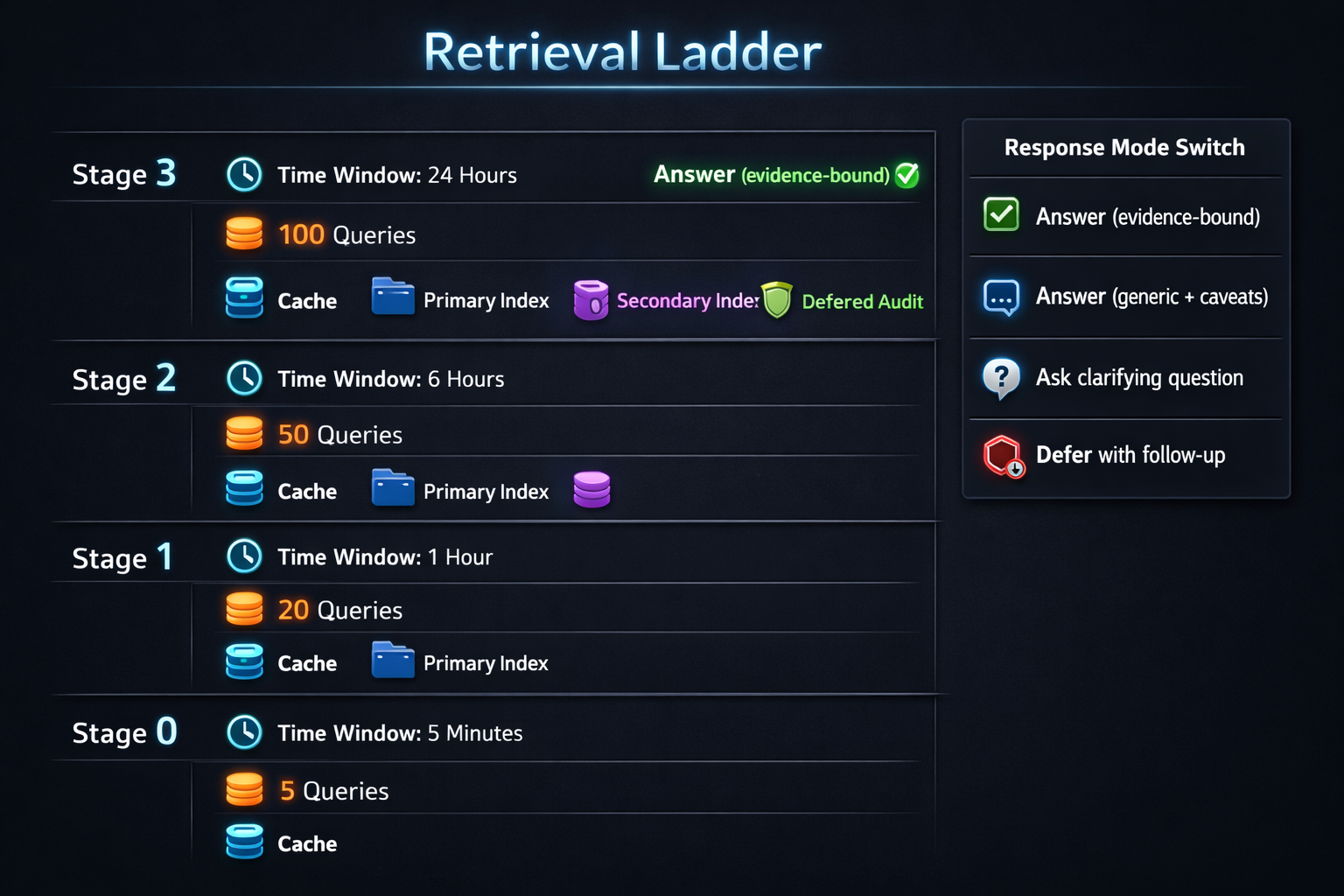
Step 2: Enforce time- and cost-bounded retrieval (without lying)
Treat retrieval as a staged process, not a single query.
A common staging pattern:
- Stage 0 (0–50ms): cached memory / local session facts
- Stage 1 (50–150ms): small, high-precision retrieval (low fanout)
- Stage 2 (150–350ms): broader retrieval, secondary indices, expansions
- Stage 3 (350ms+): deferred retrieval (async follow-up), deep audit mode
Budgeting rules that keep behavior predictable
- Hard deadlines: “Stop retrieval at T=220ms, no exceptions.”
- Fanout caps: “Max 2 indices, max 6 queries total.”
- Chunk caps: “Max 12 chunks to the model.”
- Compute caps: “Max 1 re-rank pass” (or none if you’re avoiding it).
- Defer instead of exceed: if you can’t retrieve enough, switch response mode.
This is where most systems fail: they keep trying to retrieve until time runs out, then still answer as if nothing happened. A stable system makes the cutoff visible to the planner.
Minimal pseudo-code (illustrative):
deadline_ms = 220
start = now_ms()
ctx = []
ctx += load_session_cache(budget_ms=30)
if now_ms() - start < deadline_ms:
ctx += retrieve_primary(max_queries=2, budget_ms=120)
if now_ms() - start < deadline_ms and ctx_is_thin(ctx):
ctx += retrieve_secondary(max_queries=3, budget_ms=70)
signal = grade_context(ctx, elapsed_ms=now_ms()-start, deadline_ms=deadline_ms)
return plan_response(signal, ctx)
The important part isn’t the code—it’s the contract: retrieval runs inside bounds, and output behavior depends on what actually returned.
Step 3: Grade context adequacy like you grade latency
Before generation, compute a Context Adequacy Signal that the response planner can trust.
A simple scoring model:
- Coverage score (0–1): did we retrieve anything relevant?
- Specificity score (0–1): do we have user-specific facts or only generic docs?
- Freshness score (0–1): based on source timestamps / index lag
- Consistency score (0–1): contradictions detected across sources
- Budget score (0–1): how close to cutoff / partial retrieval was
Then derive states like:
NO_CONTEXTPARTIAL_CONTEXT_GENERICPARTIAL_CONTEXT_USERADEQUATE_CONTEXTCONFLICTING_CONTEXTSTALE_CONTEXT
This grading layer is the difference between:
- “The model thinks it knows.”
- “The system knows what it knows.”
Step 4: Adapt response behavior to available knowledge
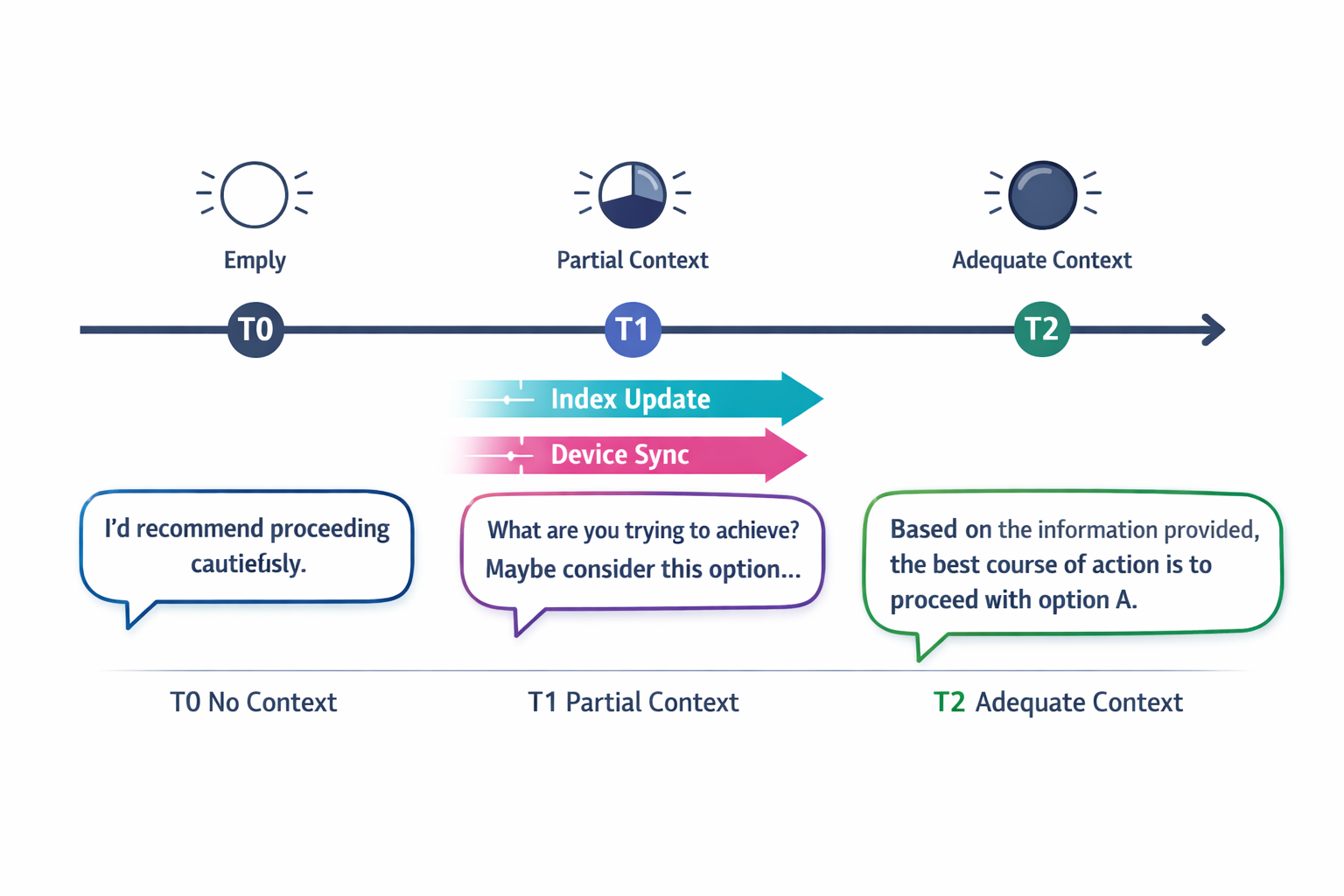
Once you have a context state, the response planner chooses a response mode. This is the heart of “useful with partial context.”
Mode 1: Evidence-bound answer (adequate context)
- Answer directly
- Cite retrieved facts (internally) and keep claims anchored
- Include “what I used” at a human level: “Based on your last sync and policy X…”
Mode 2: Conservative answer (partial context)
- Provide what’s safe and stable
- Clearly separate:
- Known from context
- Assumptions
- Next steps to confirm
- Offer a lightweight clarification prompt only when it unlocks correctness
Example pattern:
- What I can tell from the available context: …
- What I can’t confirm yet: …
- Fastest way to confirm: …
Mode 3: Diagnostic questions (context-required, missing)
Ask the minimum number of questions to unlock retrieval or validation.
Good questions are:
- binary where possible (yes/no)
- tied to a specific missing variable
- phrased in user language, not system language
Mode 4: Refuse-with-path (unsafe without context)
When answering would be misleading, refuse while staying helpful:
- state what’s missing
- offer actions: “connect device,” “run sync,” “share log id,” “enable permission”
- if applicable: provide general guidance while refusing the specific claim
Mode 5: Conflict resolution mode (conflicting context)
When sources disagree:
- don’t average them
- don’t pick one silently
- present the conflict and propose resolution steps
Example:
- “Policy says X, but config snapshot says Y. Which environment is active?”
- “If you’re on rollout version A, then…, otherwise…”
Rule: Never let the model silently “decide” conflicts that the system can’t justify.
Step 5: Avoid hallucinating certainty with “claim typing”
One extremely practical technique: classify each sentence the assistant emits into a claim type, and enforce formatting rules.
Common claim types:
- Observed: directly supported by retrieved evidence
- Derived: logical inference from observed facts
- Suggested: recommended action or best practice
- Unknown: explicitly stated as not knowable from current context
Then enforce constraints:
- Observed claims must map to evidence IDs
- Derived claims must cite which observed claims they depend on
- Unknown claims must not be phrased as factual
Even without showing citations to users, this internal discipline prevents “confident blur.”
A lightweight implementation is to instruct the generator to output structured sections, then post-process for compliance.
Step 6: Make partial context feel reliable to users
“Graceful degradation” is not only backend logic—it’s also UX truthfulness.
Patterns that preserve trust:
- Progressive disclosure: show the best safe answer first, then “Want deeper accuracy? Fetch more context.”
- Fast + correct beats slow + complete: a 200ms conservative response wins over a 2s answer users can’t trust.
- Stable phrasing under uncertainty: define templates so answers don’t vary wildly across similar missing-context states.
- Explicit next action: if context is missing, the user should always know what to do.
A small but powerful addition: attach a Context Badge to the response internally (or visibly, depending on product maturity):
- “Based on limited context”
- “Verified with recent data”
- “Conflicting sources detected”
This is how you turn uncertainty from a liability into a design feature.
Hoomanely’s mission is to help people care for their companions with intelligence that’s useful in daily life, not just impressive in demos. In systems that bridge mobile apps, cloud services, and edge devices, partial context is unavoidable—devices go offline, data syncs late, and user history varies widely.
This “retrieval as capability” approach fits naturally when an assistant needs to answer responsibly across mixed context states—sometimes with rich history, sometimes with only general guidance. For example, when devices like EverSense or EverBowl are involved, there are moments where the best response is not a definitive claim, but a conservative, action-oriented step (“I can’t confirm the latest sync yet—here’s the quickest way to validate it, and what it likely means.”). That stability-first posture is what keeps AI helpful across real-world variability.
Step 7: Operational patterns that make this robust
A few production patterns that help the above actually work:
1) Retrieval “contracts” per endpoint
Define budgets and allowed sources per request class. Don’t let every feature “just retrieve more.”
2) Context snapshots
When correctness matters, store a snapshot of the evidence used to generate the answer (IDs + timestamps). This improves debuggability and makes behavior auditable.
3) Shadow evaluation
Run the same request through deeper retrieval in the background (non-user-blocking) to measure how often partial-context answers diverge. Use it to tune:
- stage budgets
- classification rules
- refusal thresholds
4) Deterministic fallbacks
When retrieval fails, you want repeatable behavior:
- fixed response templates
- fixed “ask 1–2 questions” logic
- fixed “defer” path
5) Consistency guardrails
If a user repeats a question, answers shouldn’t swing wildly. Cache context states briefly, and reuse prior adequacy signals when reasonable.
Takeaways
- Treat retrieval as a runtime capability, not a prerequisite.
- Classify requests by context dependency before you retrieve.
- Use staged retrieval with strict time/cost/fanout bounds.
- Grade context into explicit states (no/partial/adequate/conflicting/stale).
- Choose response modes deliberately: evidence-bound, conservative, ask, refuse-with-path, conflict resolution.
- Prevent hallucinated certainty using claim typing and evidence mapping.
- Make uncertainty product-shaped: stable templates, next actions, and optional deeper accuracy paths.
When retrieval is imperfect—and it will be—trust comes from systems that stay useful without pretending they know more than they do.
Cover image (graphical, attractive)
COVER IMAGE PROMPT (illustrative, dark-mode, highly graphical):
Create a cinematic, dark-mode cover illustration titled “Retrieval as a Runtime Capability” (title text only; no other text). Visual: a central AI “core” (glowing orb or neural lattice) connected to multiple context sources (document stacks, device icon, user profile card, policy scroll) via luminous data streams. Some streams are solid (available context), some are dotted/fading (missing context), and some are split with warning markers (conflicting context). In the foreground, add a sleek “runtime gate” mechanism—like valves or circuit breakers—that controls which streams reach the core, with a visible time/cost budget ring around it. Style: modern vector + soft cinematic glow, crisp edges, subtle depth, neon accents, product-adjacent and technically precise, no dashboards, no synthetic tables, no clutter.



