Retrieval as Infrastructure: Operating OpenSearch for AI Systems

For a long time, retrieval lived quietly in the background. It powered search boxes, filters, and internal tooling—important, but rarely the center of attention. AI changed that. In modern AI-backed products, retrieval is no longer an implementation detail. It sits directly on the critical path between user intent and system response.
Every AI interaction now fans out into multiple retrieval queries. Every user-visible delay is amplified by tail latency in search. Every partial failure in retrieval bleeds directly into hallucinations, empty answers, or degraded trust.
At Hoomanely, this shift forced a mindset change. OpenSearch is not “the search cluster” anymore—it is production infrastructure, comparable to an API gateway or a primary database. It must be predictable, bounded, observable, and evolvable under live traffic.
This post explores what it means to operate OpenSearch reliably for AI systems. Not how to create an index. Not how to tune relevance. But how to design, constrain, and run retrieval as infrastructure that AI systems can safely depend on.
The Problem: AI Workloads Break Traditional Search Assumptions
Classic search workloads were simple:
- One query per user action
- Human-scale latency tolerance
- Mostly read-heavy, predictable patterns
AI retrieval breaks all three.
A single AI request may trigger:
- Parallel vector queries across multiple indices
- Metadata filters layered on top of semantic search
- Fallback retrieval paths if the first query underperforms
- Reranking or secondary lookups
What looks like one request at the API boundary becomes dozens of OpenSearch operations behind the scenes.
This creates three immediate failure modes:
- Query amplification
Retrieval fans out faster than engineers expect, multiplying load non-linearly. - Tail latency dominance
Even if 95% of queries are fast, the slowest shard dictates user experience. - Hidden partial failures
Search can return “successful” responses with missing shards, empty segments, or silently skipped results.
If retrieval is treated as a best-effort dependency, AI systems inherit this unpredictability.
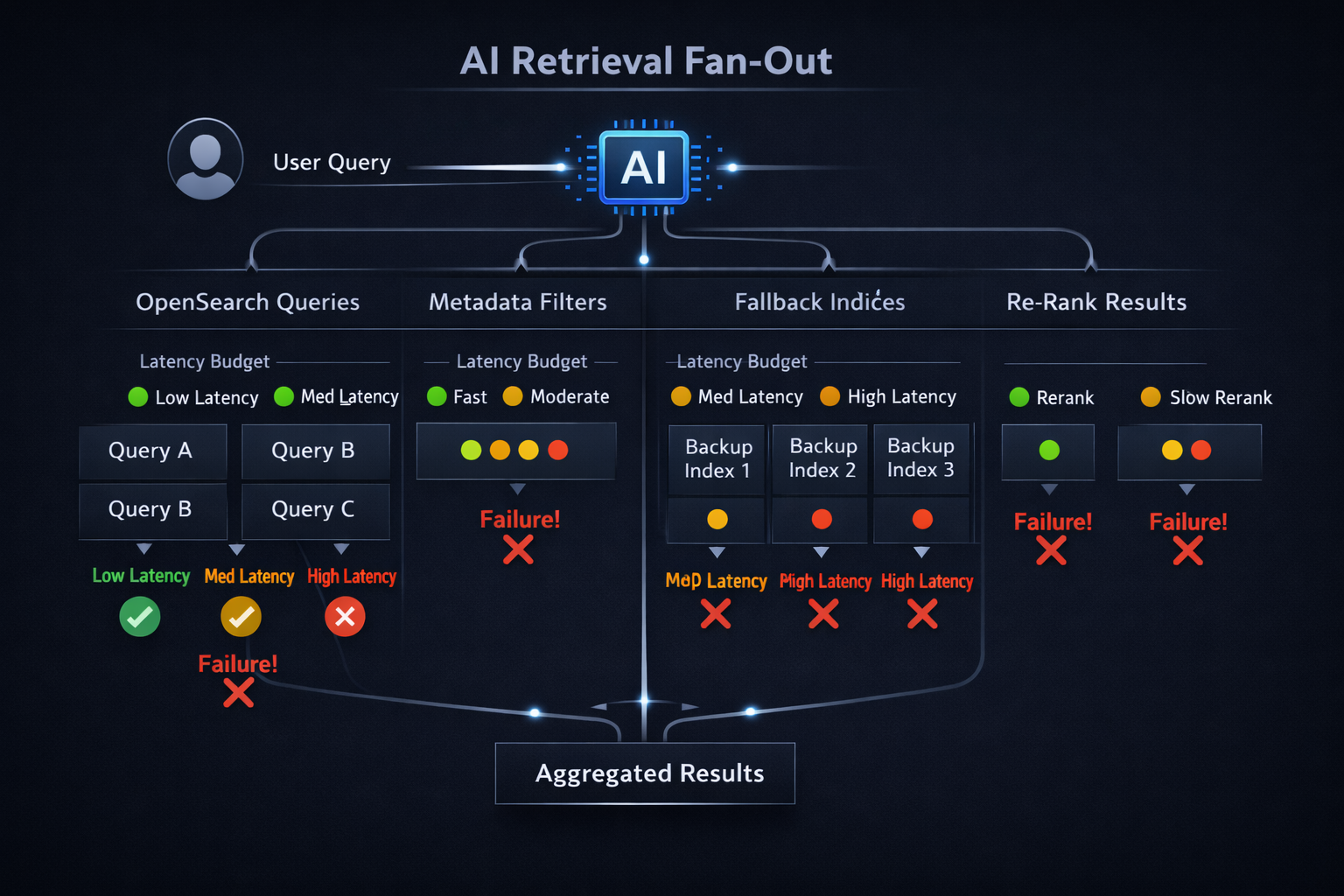
Treating OpenSearch as Latency-Critical Infrastructure
Once retrieval becomes part of the AI request path, latency budgets stop being abstract.
At Hoomanely, we treat OpenSearch with explicit constraints:
- Retrieval owns a fixed slice of end-to-end latency
- Anything beyond that budget is treated as failure, not “slow success”
- AI generation must degrade gracefully if retrieval exceeds its window
This means designing retrieval with:
- Hard query timeouts (not best-effort)
- Strict shard response expectations
- Predictable fan-out ceilings per request
Search clusters are no longer optimized for “maximum throughput.” They are optimized for bounded behavior under load.
That framing changes almost every operational decision.
Shard Strategy Under AI Query Fan-Out
Shard strategy is where most AI retrieval systems quietly accumulate risk. In AI-backed systems, a single user request rarely maps to a single search query. Instead, it fans out into parallel retrieval paths—semantic queries, filtered lookups, fallbacks, and secondary passes. Each of these paths must wait for responses from every shard involved. This makes shard layout a first-order determinant of tail latency, not just a storage concern.
Traditional guidance around sharding often optimizes for index size, ingestion throughput, or operational convenience. Under AI workloads, those assumptions break. What matters is how shards behave under concurrent, latency-sensitive fan-out, not how evenly data is distributed.
Key operational realities that emerge:
- Every additional shard increases the probability that one slow shard dictates overall response time.
- Oversharding amplifies tail latency even when average latency looks healthy.
- Vector-heavy queries are especially sensitive to shard-level CPU contention and cache locality.
At Hoomanely, shard decisions are framed around retrieval behavior, not data volume. Indices are shaped to answer one question clearly and fast, rather than many questions flexibly.
Practically, this leads to a few guiding principles:
- Prefer fewer, hotter shards over many small ones for AI-facing indices.
- Size shards so they comfortably fit in memory under expected query load.
- Use replicas deliberately to absorb bursty parallel queries—not just for fault tolerance.
- Separate fast-path and slow-path retrieval into different indices to prevent head-of-line blocking.
The goal is not perfect balance. The goal is predictable shard response under real AI traffic, even when usage spikes or query patterns shift.
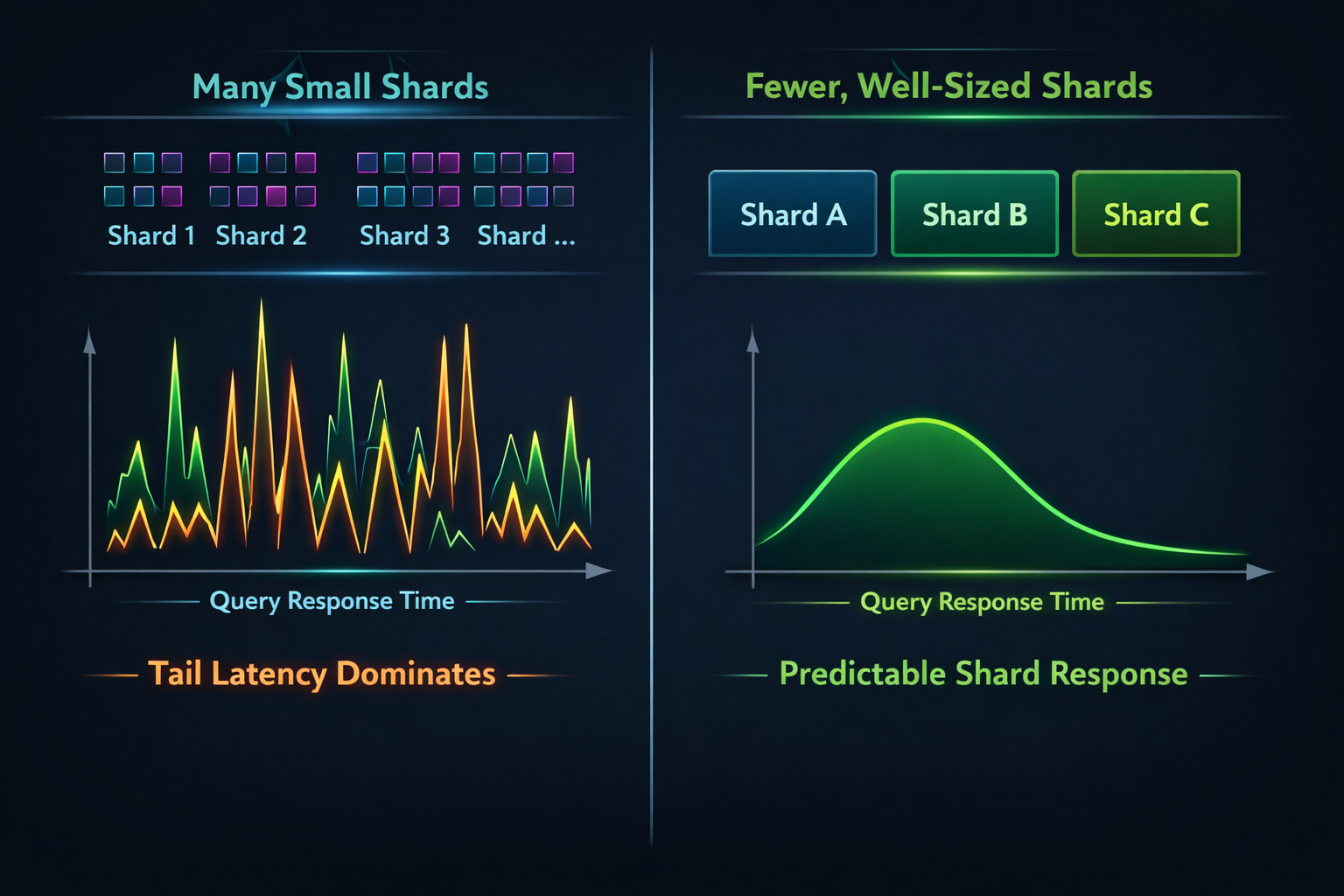
Controlling Tail Latency Before It Controls You
Average latency is a misleading metric in AI systems. Users experience the 99th percentile.
To control tail latency, retrieval must be defensive by design:
- Time-box every retrieval stage
Queries that exceed their budget are cut, not awaited. - Prefer partial answers over delayed answers
AI systems can reason with incomplete context—but users abandon slow responses. - Enforce per-request fan-out limits
Retrieval depth is capped, even if relevance might improve slightly beyond it.
One critical insight:
Tail latency is not a performance bug—it is a systems property.
You don’t eliminate it. You contain it.
At Hoomanely, AI orchestration layers treat retrieval responses as streams with deadlines. Late results are ignored, not merged.
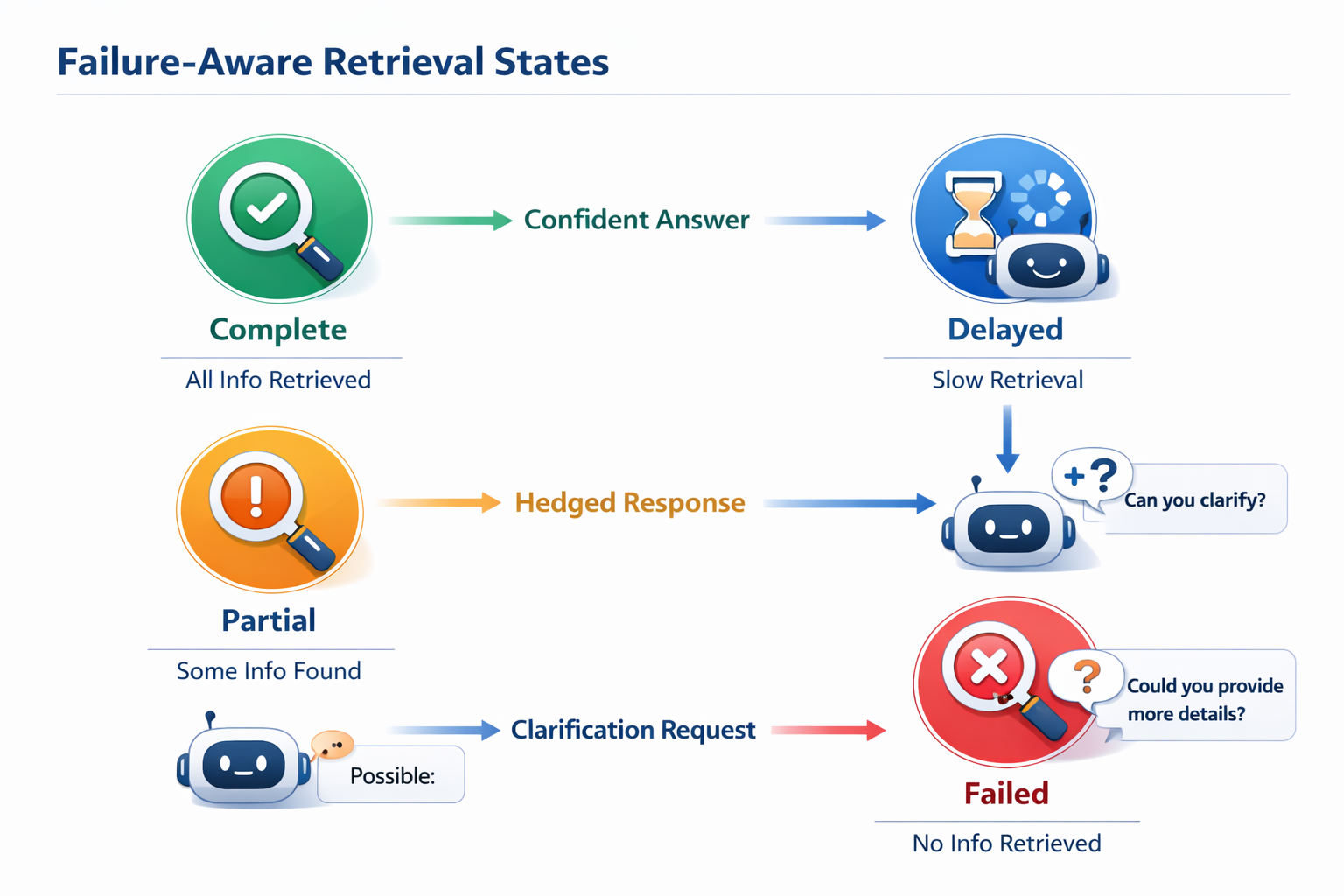
Failure-Aware Retrieval: Designing for Partial Truth
In production, retrieval rarely fails cleanly. OpenSearch failures tend to be partial and asymmetric: one shard times out, one replica lags, one segment misses a refresh window. From the cluster’s perspective, the request may still succeed. From the AI system’s perspective, the context is incomplete—and dangerously ambiguous.
Treating retrieval as a binary success/failure dependency leads to two common mistakes:
- Failing entire AI responses unnecessarily.
- Accepting incomplete context silently and allowing hallucinations.
Reliable AI systems take a different approach: they make retrieval failure explicit and actionable.
Instead of asking “did retrieval succeed?”, the system asks:
- How complete is the retrieved context?
- Which parts were missing or delayed?
- Is the remaining context sufficient for a confident response?
This requires retrieval to return more than documents—it must return signals.
In practice, failure-aware retrieval includes:
- Tagging retrieval responses with completeness metadata (e.g., shard coverage, timeout flags).
- Propagating retrieval confidence into the AI orchestration layer.
- Adjusting response behavior based on retrieval quality, not just model output.
This enables controlled degradation:
- When retrieval is complete → confident, direct answers.
- When retrieval is partial → hedged responses, clarifying questions, or scoped recommendations.
- When retrieval fails → explicit acknowledgment instead of fabricated certainty.
At Hoomanely, this pattern is critical because AI responses often influence real-world decisions. An answer that says “I may be missing some context” is far safer—and more trustworthy—than one that sounds confident but is wrong.
The underlying shift is subtle but powerful:
Retrieval is no longer just data access—it is a contract between infrastructure and intelligence.
Once retrieval quality is surfaced and respected, AI systems become more resilient, honest, and predictable under real operating conditions.
Observability Beyond “Cluster Is Green”
A green OpenSearch cluster tells you almost nothing about AI readiness.
For AI workloads, observability shifts from infrastructure health to experience health:
- Per-query latency distribution
- Shard-level timeout frequency
- Retrieval completeness ratios
- Query amplification per request
- Cost per AI interaction
At Hoomanely, we track:
- Retrieval latency as a first-class metric alongside model latency
- P95 and P99 shard response times, not just averages
- Retrieval contribution to total AI response time
This allows us to answer questions like:
- “Is search slowing down AI, or is the model?”
- “Which index version increased tail latency?”
- “Are we paying more for retrieval without quality gains?”
Without this visibility, teams chase the wrong bottlenecks.
Index Evolution Without Breaking Live AI Systems
AI systems evolve constantly:
- New chunking strategies
- New embedding models
- New metadata filters
- New schemas
Index evolution is inevitable—and dangerous.
Key principles we follow:
- Never mutate live indices in place
- Version everything: schema, embeddings, mappings
- Run shadow retrieval before promotion
New indices are introduced gradually:
- Shadow traffic compares latency and completeness
- AI outputs are evaluated offline
- Promotion happens only after stability is proven
This mirrors how we deploy application code—but applied to retrieval.
Hoomanely builds AI systems that sit close to real-world behavior—devices, events, and time-series signals. Whether insights come from EverSense telemetry or EverBowl interactions, retrieval often decides what context the AI sees at the moment of response.
That makes retrieval reliability a user trust issue, not just a backend concern.
By treating OpenSearch as infrastructure:
- AI responses remain stable under bursty traffic
- Latency stays predictable even as usage grows
- Index changes don’t destabilize live features
- Costs remain bounded and explainable
This operational discipline lets teams move faster without gambling on search behavior.
Takeaways
- Retrieval is no longer a helper—it is core AI infrastructure.
- AI workloads amplify shard design mistakes and latency variance.
- Tail latency must be bounded, not optimized away.
- Partial retrieval is inevitable; systems must acknowledge it explicitly.
- Observability must focus on retrieval experience, not just cluster health.
- Index evolution requires the same rigor as production deployments.
When retrieval is treated as infrastructure, AI systems become calmer, more predictable, and more trustworthy—no matter how complex they grow.



