Similarity Search: A Deep Dive into Image Similarity Search


Introduction
Image similarity search is one of the most versatile and widely used techniques in modern computer vision. Whether you're identifying duplicate images, powering search engines, detecting tampering, or performing lightweight recognition tasks on edge devices, the idea remains the same: convert images into numerical representations and measure how close they are.
At Hoomanely, we use this method in a small part of our food‑detection workflow inside our smart bowl system - specifically to understand whether the bowl contains food and how similar it is to previous states. That’s all the context you’ll see about our product; the rest of this post is a deep, standalone exploration of image similarity systems and how they work.
The Problem Space
Traditional image classification assumes you know the categories beforehand. But many tasks don’t fit neatly into labels:
- You want to know how similar two images are, not which class they belong to.
- Objects may vary subtly in texture, color, or partial appearance.
- Conditions like lighting, angle, and occlusions change constantly.
Similarity search solves these cases by comparing images in a continuous space rather than discrete labels.
Why Image Similarity??
Image similarity works by embedding images in a metric space. The closer two embedding vectors are, the more visually similar their images should be.
Key advantages:
- Robust to lighting and orientation shifts
- Works without strict class definitions
- Easily scalable - just add more reference images
- Efficient enough to run on mobile or edge hardware
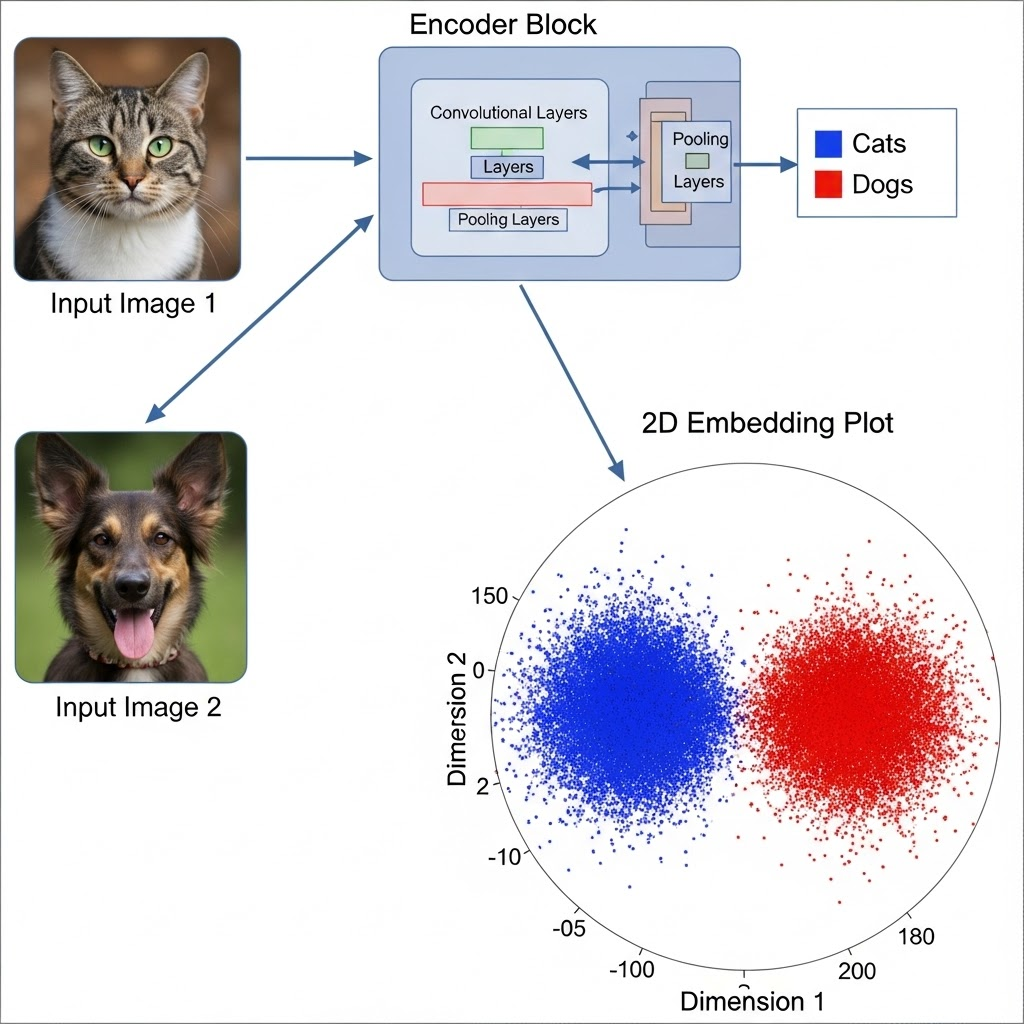
How Image Similarity Systems Work
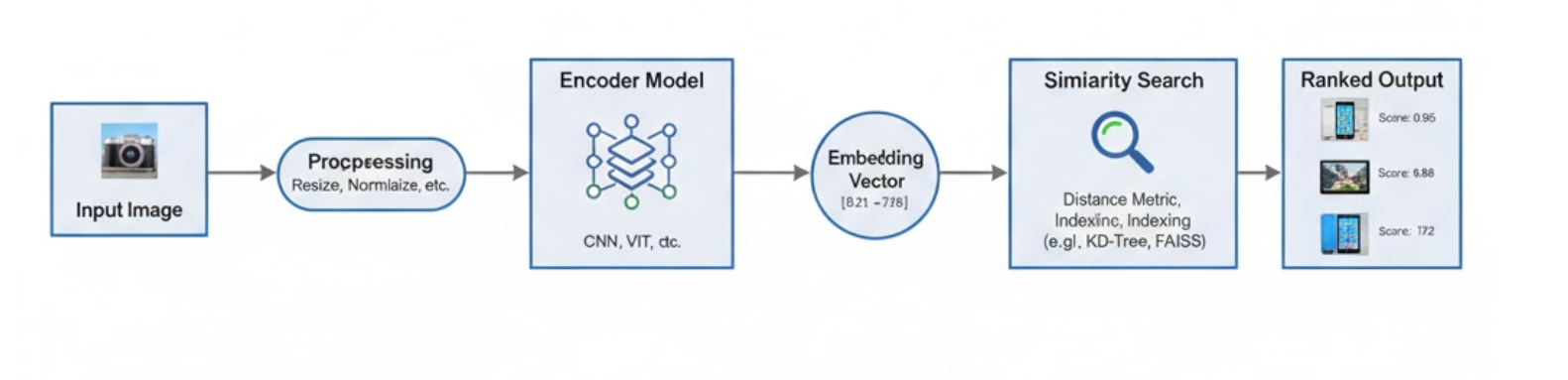
A clean and modular similarity search pipeline generally includes these steps:
1. Preprocessing
Before any comparison, ensure consistency:
- Resize to a standard shape (e.g., 224×224)
- Normalize pixel values
- Optional: crop, denoise, augment
Consistent preprocessing makes similarity scores reliable.
2. Embedding Generation
An embedding model transforms an image into a compact vector (often 128–1024 dimensions). Popular architectures:
- MobileNetV3
- EfficientNet-Lite
- CLIP ViT encoders
- ResNet‑based encoders
These vectors capture visual features such as shape, color distribution, and texture.
3. Similarity Computation
Once you have embeddings, you compare them using a chosen similarity metric (more on these shortly).
4. Ranking / Decision Layer
The system ranks gallery images based on similarity or applies a threshold to decide whether two images are “close enough.”
This architecture can power:
- Reverse image search
- Duplicate detection
- Visual recommendation engines
- Light object recognition
- State comparison workflows
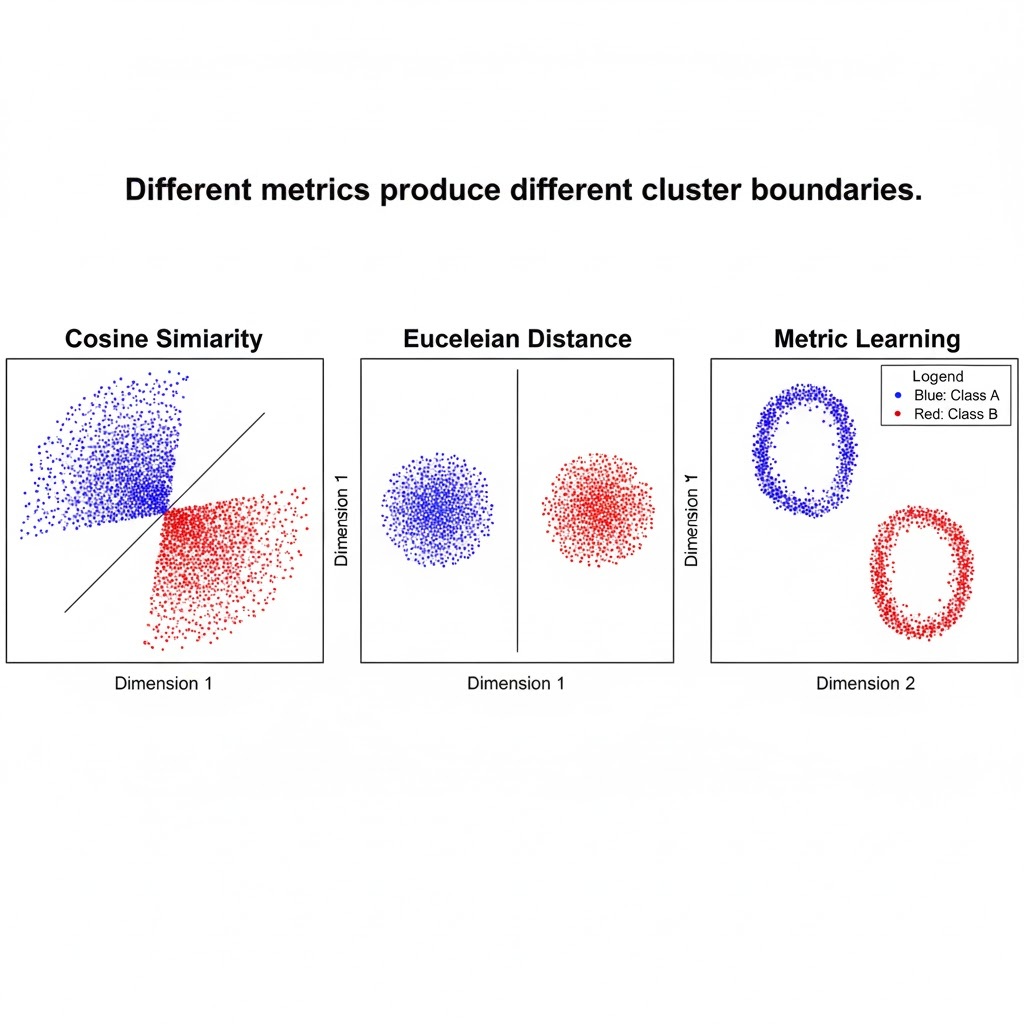
Similarity Metrics: How “Closeness” Is Measured
Not all distance metrics behave the same. Choosing the right one dramatically affects system performance.
Below are the most common similarity score criteria used in production systems.
1. Cosine Similarity (most widely used)
Cosine measures the angle between two embedding vectors.
cosine(A, B) = (A · B) / (‖A‖ ‖B‖)
Why it works well:
- Insensitive to overall brightness
- Stable across small variations
- Works beautifully for high-dimensional embeddings
Most neural image encoders produce direction‑rich embeddings, making cosine a natural fit.
2. Euclidean Distance (L2)
Measures the straight‑line distance between two vectors.
d(A, B) = sqrt( Σ (A_i - B_i)^2 )
Good for:
- Shape‑driven images
- Embeddings that are L2‑normalized
Caution:
Sensitive to magnitude differences if not normalized.
3. Manhattan Distance (L1)
Sums the absolute differences.
- More robust to noise than Euclidean
- Good for datasets with high variance or mixed textures
Often used in conjunction with cosine for tie‑breaking.
4. Structural Similarity Index (SSIM)
SSIM compares perceptual quality instead of raw pixel differences.
Evaluates:
- Contrast
- Luminance
- Structural patterns
Best suited for comparing very similar images or detecting distortion, compression artifacts, and tampering.
5. Learned Similarity (Metric Learning)
Here, the model is trained directly to understand similarity rather than classification.
Popular approaches:
- Triplet Loss
- Contrastive Loss
- ArcFace / CosFace style margin losses
Benefits:
- Learns task‑specific similarity
- Creates tight clusters even for subtly different classes
- Ideal when domain images vary a lot
Drawback:
Requires curated positive/negative pairs and a substantial training set.
Applications of Image Similarity Search
Similarity systems enable a wide range of real-world applications:
1. Visual Search & Retrieval
Search by example, like Google Lens or e‑commerce "search by photo".
2. Duplicate & Near‑Duplicate Detection
Useful for content moderation, dataset cleaning, or cloud storage optimization.
3. Quality Inspection in Manufacturing
Identify deviations, defects, or subtle pattern changes.
4. Medical Imaging
Compare pathology samples, X‑rays, or scans with known references.
5. Lightweight Recognition Workflows
Instead of training classifiers for every category - compare images with a reference gallery.
6. State Comparison Systems
A small part of our work at Hoomanely uses this idea to compare bowl states. Similar techniques are widely used in robotics and autonomous systems.
Advantages & Limitations
Advantages
- Flexible across domains
- Works even with unlabeled data
- Easily expandable
- Lightweight models suffice
- Great balance between accuracy and compute
Limitations
- Needs a diverse reference gallery
- Quality depends heavily on the embedding model
- Hard to explain similarity decisions in some cases
- Sensitive to major viewpoint changes unless trained for it
Best Practices for Building Robust Similarity Systems
1. Maintain a High‑Quality Gallery
Diverse samples improve robustness.
2. Normalize Embeddings
Always L2‑normalize unless using cosine directly.
3. Use Multiple Metrics
Cosine + Euclidean often catches edge cases.
4. Threshold Carefully
Dynamic thresholds adapt to lighting and noise.
5. Benchmark Regularly
Track recall@k, precision@k, and false positives.
Conclusion: Why Similarity Search Matters
Image similarity search is one of the most elegant and practical ideas in computer vision. Instead of forcing images into rigid classes, it creates a continuous understanding of visuals - allowing systems to work fluidly across environments, categories, and subtle variations.
From powering search engines to enabling industrial inspection to helping compare real‑world physical states, similarity search is a foundational building block for any modern vision pipeline.
A small portion of Hoomanely’s own work taps into this concept, but the technique itself stands much broader: a versatile, scalable, and immensely useful approach for visual understanding.
Key Takeaways
- Image similarity search maps images into a vector space and measures closeness.
- Cosine similarity is the most stable and widely used metric.
- Euclidean, Manhattan, SSIM, and learned metrics each have specific strengths.
- Similarity search powers everything from search engines to industrial and medical systems.
- A strong gallery and a good embedding model are the core of a successful system.



