The Silicon Errata Trap: Navigating Undocumented Hardware Bugs in Advanced Microcontrollers

When building cutting-edge pet health monitoring devices, encountering undocumented silicon quirks isn't just frustrating—it can derail product timelines and compromise system reliability. While working on Hoomanely's next-generation pet healthcare platform, our team discovered that even the most sophisticated ARM Cortex-M33 based microcontrollers harbor subtle timing anomalies that demand creative software workarounds.
The Hidden Reality of Modern Silicon
Every microcontroller generation brings impressive feature sets, higher clock speeds, and enhanced peripherals. However, beneath the marketing specifications lies a complex reality: silicon errata. These aren't just minor inconveniences—they're fundamental hardware behaviors that can cause intermittent failures, timing violations, and system instability if not properly addressed.
Our recent experience developing a high-performance camera module with integrated AI processing capabilities revealed several critical timing-related issues that required systematic detection and mitigation strategies.
Case Study: RTC Clock Domain Synchronization Issues
One of the most challenging errata we encountered involved Real-Time Clock (RTC) initialization failures under specific power sequencing conditions. The issue manifested as sporadic HAL_RTC_Init failures, particularly when transitioning between different power states—critical for a battery-powered pet monitoring device that needs to maintain accurate timestamps.
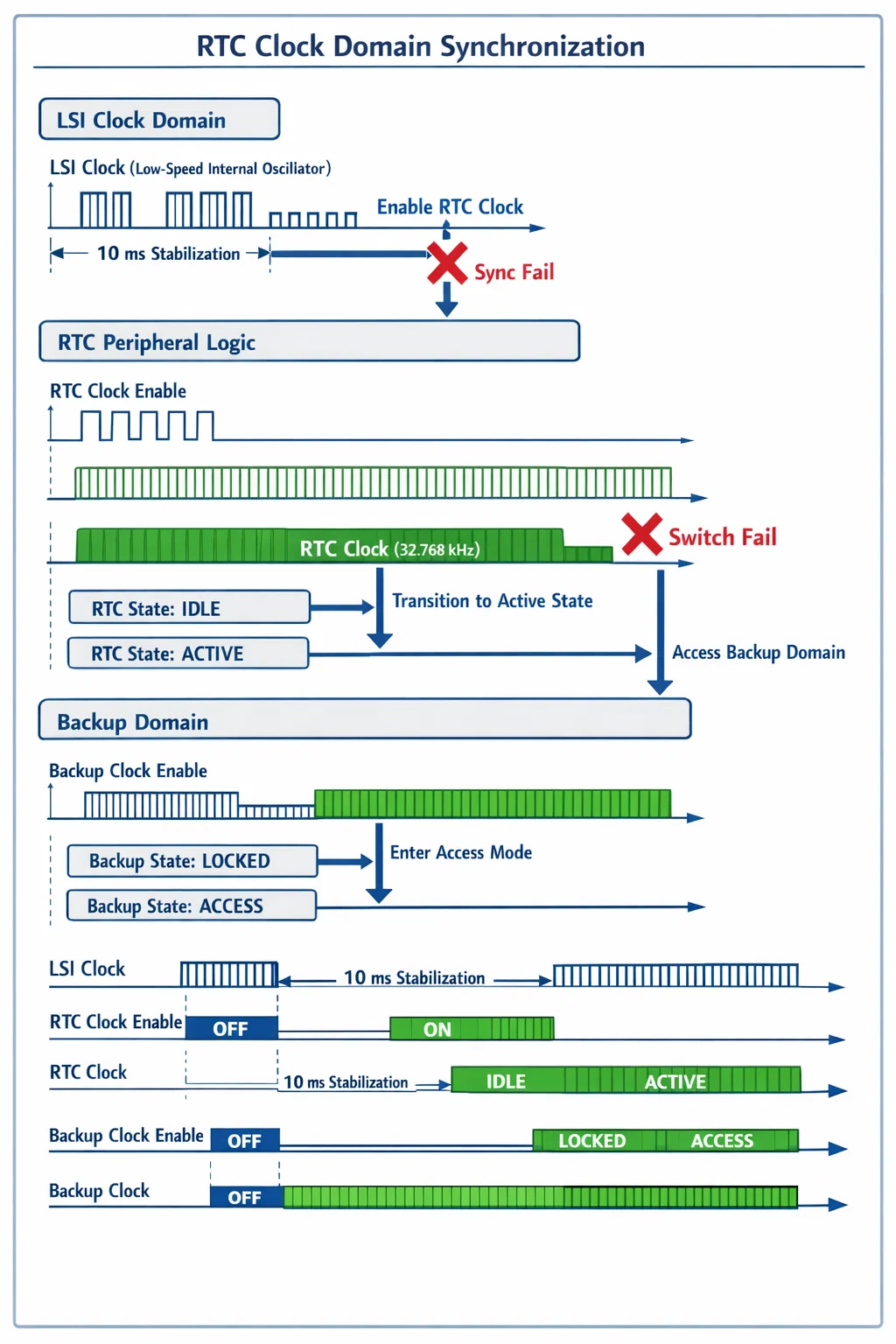
The Problem Surface
Initial symptoms appeared deceptively simple: occasional RTC initialization failures with no clear error pattern. Standard debugging approaches yielded inconsistent results, suggesting a timing-dependent root cause.
// Original failing approach
HAL_StatusTypeDef RTC_Init(void) {
hrtc.Instance = RTC;
hrtc.Init.HourFormat = RTC_HOURFORMAT_24;
hrtc.Init.AsynchPrediv = 127; // LSI: 32000/(127+1) = 250Hz
hrtc.Init.SynchPrediv = 249; // 250/(249+1) = 1Hz
return HAL_RTC_Init(&hrtc); // Sporadic failures here
}
The Workaround Strategy
Through systematic analysis, we discovered that the RTC peripheral requires specific clock domain sequencing that isn't documented in the standard reference manual. The solution involved implementing a multi-stage initialization process with explicit clock domain management:
HAL_StatusTypeDef RTC_ClockConfig(void) {
// Step 1: Enable backup domain access FIRST
HAL_PWR_EnableBkUpAccess();
// Step 2: Configure LSI oscillator with verification
RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_LSI;
RCC_OscInitStruct.LSIState = RCC_LSI_ON;
if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) {
return HAL_ERROR;
}
// Step 3: Force reset if in error state
if (hrtc.State == HAL_RTC_STATE_ERROR) {
__HAL_RCC_BACKUPRESET_FORCE();
HAL_Delay(10); // Critical timing delay
__HAL_RCC_BACKUPRESET_RELEASE();
HAL_Delay(10); // Allow stabilization
}
// Step 4: Enable peripheral clocks in sequence
__HAL_RCC_RTC_ENABLE();
__HAL_RCC_RTC_CLK_ENABLE();
return HAL_OK;
}
The key insight was that clock domain transitions require explicit stabilization delays—typically 10ms—that aren't mentioned in the peripheral documentation.
Memory Subsystem Timing Anomalies
Working with 8MB external PSRAM via the FMC interface revealed another category of errata: memory access timing dependencies that vary with system load and peripheral activity.
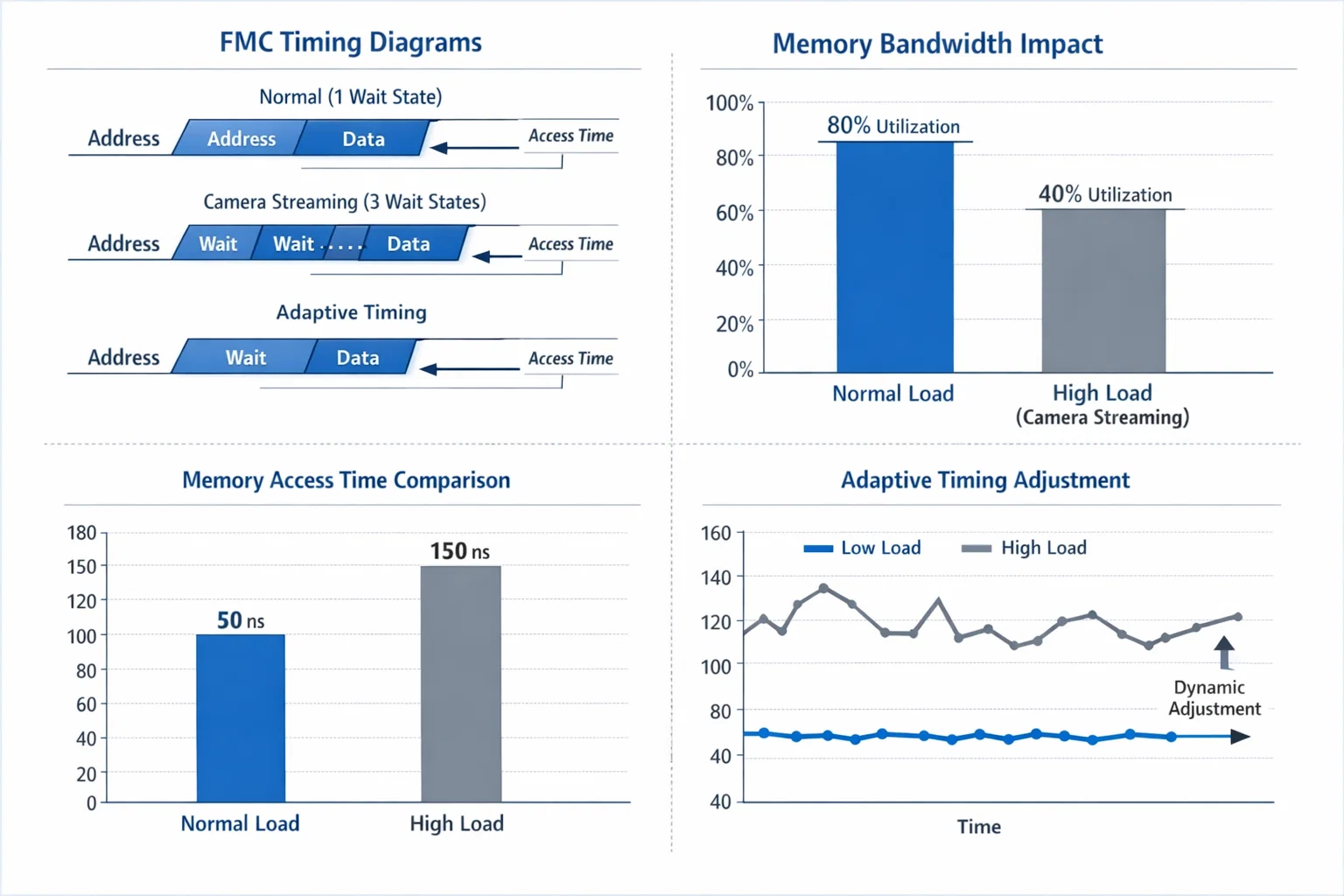
Dynamic Timing Requirements
Standard FMC timing calculations based on datasheet specifications proved insufficient under high-bandwidth conditions. Camera data streaming while simultaneously accessing PSRAM created bus contention scenarios that required adaptive timing adjustments:
// Adaptive PSRAM access with timing compensation
void PSRAMwrite(void *psram_addr, const void *src_data, size_t size) {
// Check current system load indicators
if (is_camera_streaming() || is_dma_active()) {
// Insert additional wait states for high-load conditions
configure_fmc_extended_timing();
}
// Perform write with error checking
memcpy(psram_addr, src_data, size);
// Verify write integrity
if (memcmp(psram_addr, src_data, size) != 0) {
// Retry with conservative timing
configure_fmc_safe_timing();
memcpy(psram_addr, src_data, size);
}
// Restore optimal timing
configure_fmc_default_timing();
}
OCTOSPI Flash Interface Synchronization
External flash operations via the OCTOSPI interface presented timing challenges related to delay block configuration—a feature designed to provide phase adjustment for high-speed operations but prone to instability at boundary conditions.
Delay Block Calibration Issues
The OCTOSPI delay block requires periodic recalibration, particularly after thermal cycling or power transitions. We implemented a proactive calibration strategy:
HAL_StatusTypeDef octospi_maintain_timing_integrity(void) {
static uint32_t last_calibration = 0;
uint32_t current_time = HAL_GetTick();
// Recalibrate every 60 seconds or after significant events
if ((current_time - last_calibration) > 60000 ||
thermal_event_detected() ||
power_transition_detected()) {
// Perform delay block recalibration
HAL_XSPI_DLYB_GetClockPeriod(&hxspi, &delay_config);
HAL_XSPI_DLYB_SetConfig(&hxspi, &delay_config);
last_calibration = current_time;
}
return HAL_OK;
}
Building Robust Detection Strategies
Successfully managing silicon errata requires proactive detection and systematic validation approaches:
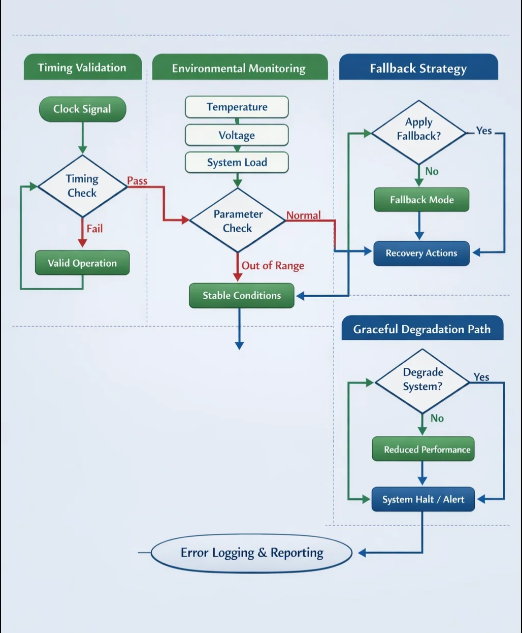
1. Timing Validation Framework
Implement comprehensive timing verification during initialization:
bool validate_peripheral_timing(peripheral_type_t peripheral) {
uint32_t start_time = HAL_GetTick();
bool success = initialize_peripheral(peripheral);
uint32_t end_time = HAL_GetTick();
// Log timing patterns for analysis
log_timing_data(peripheral, success, end_time - start_time);
return success && (end_time - start_time) < expected_max_time;
}
2. Environmental Monitoring
Track conditions that trigger errata:
typedef struct {
float temperature;
uint32_t supply_voltage;
uint32_t system_load;
bool thermal_event;
} system_environment_t;
void monitor_errata_triggers(void) {
system_environment_t env = get_system_environment();
if (env.temperature > TEMP_THRESHOLD ||
env.supply_voltage < VOLTAGE_THRESHOLD) {
apply_conservative_timing();
}
}
3. Graceful Degradation
Implement fallback strategies for critical operations:
HAL_StatusTypeDef robust_memory_operation(void *addr, void *data, size_t size) {
// Primary attempt with optimal settings
if (memory_write_optimized(addr, data, size) == HAL_OK) {
return HAL_OK;
}
// Fallback with conservative timing
configure_safe_mode();
if (memory_write_safe(addr, data, size) == HAL_OK) {
return HAL_OK;
}
// Final fallback with maximum safety margins
return memory_write_ultra_safe(addr, data, size);
}
Connecting to Hoomanely's Mission
At Hoomanely, our goal is to revolutionize pet healthcare through advanced technology that continuously monitors and analyzes pet health. This requires embedded systems that operate with unwavering reliability—the kind of dependability that only comes from thoroughly understanding and mitigating silicon-level behaviors.
These errata workarounds aren't just technical solutions; they're enablers of Hoomanely's preventive care vision. When our Edge AI devices process critical health data from multiple sensors, timing precision becomes paramount. A missed sensor reading due to memory access failure or an RTC desynchronization could mean the difference between early health intervention and reactive treatment.
Our systematic approach to silicon errata management directly strengthens Hoomanely's technology foundation, ensuring that the clinical-grade intelligence we promise remains consistently available for the pets and families who depend on it.
Key Takeaways
- Expect the Unexpected: Even well-documented peripherals harbor timing dependencies that emerge under specific operational conditions.
- Implement Defensive Programming: Build timing validation and fallback strategies into critical code paths from the beginning.
- Monitor Environmental Factors: Temperature, voltage, and system load can trigger latent errata—plan accordingly.
- Document Everything: Maintain detailed logs of errata encounters and solutions for future reference and team knowledge transfer.
- Test Under Stress: Real-world conditions often reveal errata that don't appear during development testing.
Successfully navigating silicon errata requires patience, systematic analysis, and robust engineering practices. While these hidden hardware behaviors can initially seem like insurmountable obstacles, they ultimately drive us toward more resilient, well-tested solutions that perform reliably in the real world where our technology makes a difference in pets' lives.



