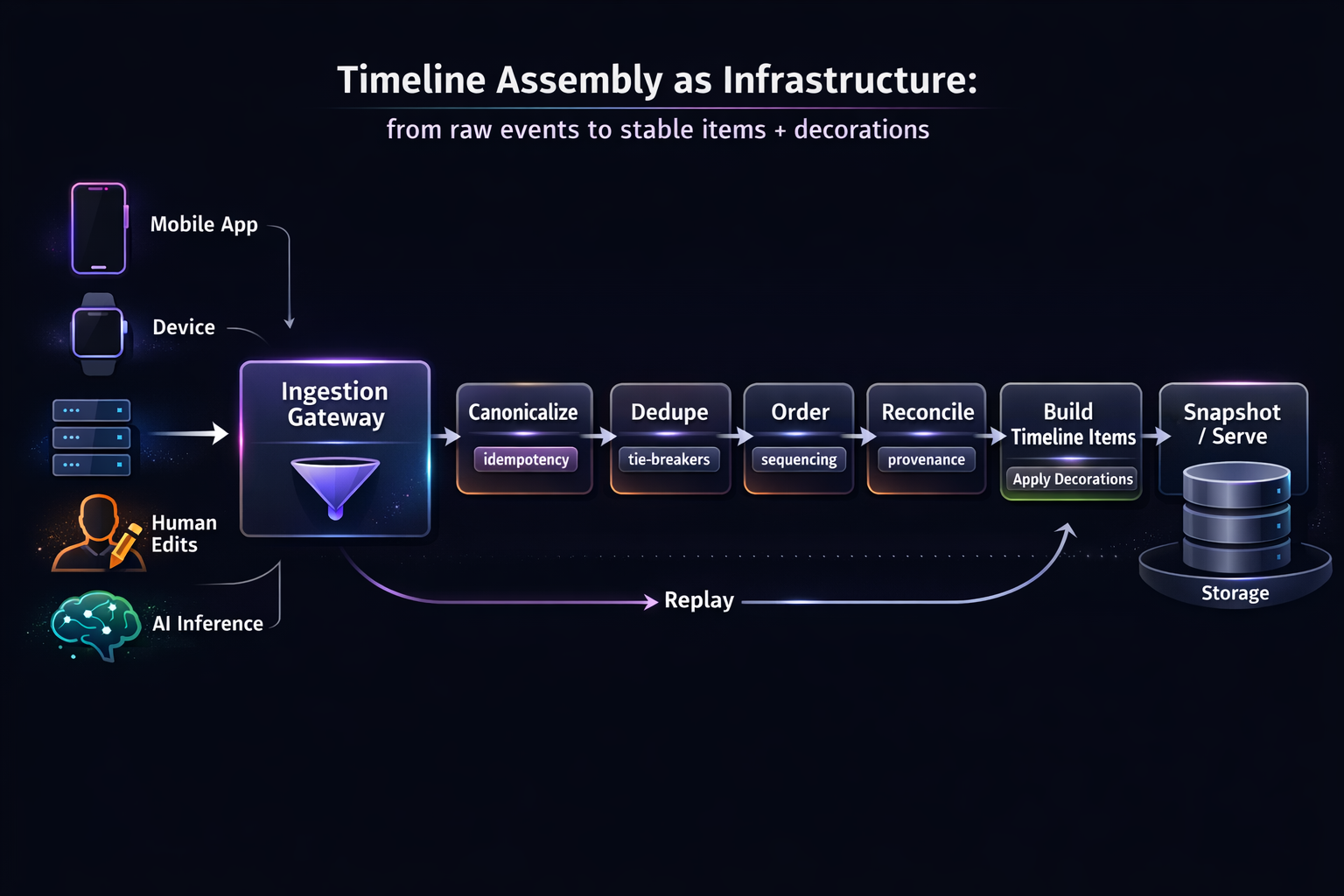
Timeline Assembly as Infrastructure

A user-visible history blends signals that behave nothing alike: taps and toggles from the app, device-originated events, backend jobs that complete later, human edits, and (increasingly) AI insights that evolve as models improve. These inputs arrive asynchronously, often out of order, sometimes duplicated, and occasionally retracted. If you treat the timeline as a UI problem, you end up with flicker, reordering, and “why did that change?” moments that quietly break trust.
Treating timeline assembly as infrastructure flips the mindset: the timeline becomes a deterministic, replayable pipeline that converts noisy distributed inputs into a stable narrative—one that can explain itself, tolerate late data, and improve intelligence without rewriting the user’s reality.
The real problem: a timeline is a trust contract
A “correct” timeline is not just one that reflects what happened—it’s one that stays stable as systems catch up.
Common failure patterns look harmless in logs, but painful in UX:
- Out-of-order arrivals: an enrichment arrives after the user has already seen the base event.
- Retries & duplicates: an at-least-once pipeline replays the same logical action.
- Corrections: a device reports new calibration; a backend job revises a value; a user edits history.
- AI overlays: an insight changes because the model got better (or context increased).
If each consumer assembles these differently (mobile app, web app, analytics export), your timeline becomes inconsistent by surface. Users notice. The infrastructure approach has one goal: make “what the user sees” a deterministic function of inputs, regardless of arrival order or partial failure.
Infrastructure approach
Build an assembly pipeline that produces stable “timeline items” from events, then layers enrichments and AI as versioned decorations—not as edits to the core.
That single design choice drives most of the reliability properties you want:
- predictable ordering
- idempotency under retries
- safe late-arrival handling
- explainability
- evolvability
Define a canonical event model
Your first enemy is not out-of-order delivery—it’s inconsistent meaning. A canonical model should make these explicit:
What happened (fact)
This is the “core” signal that should not change lightly.
actor(who/what produced it)entity(what it’s about)kind(what type of event)occurred_at(when it happened in source time)source(mobile, device, backend job, human edit)payload(the raw facts)
Why we believe it (provenance)
You want to answer: “Where did this come from?”
- ingestion metadata (topic/partition, request id)
- signature / device id / auth principal
- processing lineage (pipeline stages)
How to dedupe it (identity)
This is the backbone of determinism.
event_id(unique per emission)- and a
logical_id(stable across retries for the same logical action)
A practical pattern is:
event_id: unique UUID for each emitted messagelogical_id: idempotency key derived from intent
e.g.,hash(actor_id + kind + entity_id + client_action_id)
This prevents the “same thing twice” problem from being handled ad hoc later.
Convert raw events into timeline items with deterministic rules
A timeline item is the user-facing unit: one row, one card, one moment.
The key is: timeline items are not the same as events.
- Multiple events may map to one item (e.g., “Meal recorded” + “Nutrition computed”).
- One event may create multiple items (rare, but possible for fan-out narratives).
The golden rule: item identity must be stable
If your item ID changes across replays, your UI can’t do diff-based updates safely.
A robust item identity usually includes:
entity_id(the subject)logical_id(the intent anchor)item_kind(user-visible type)- optional
scope_key(if one logical action produces multiple cards)
Example (illustrative, minimal):
timeline_item_id = hash(entity_id + logical_id + item_kind + scope_key)
Now you can replay the entire pipeline, and the same inputs always yield the same item IDs.
Ordering that ignores arrival time
Arrival time is a lie in distributed systems. Your ordering must be computed from semantic time plus stable tie-breakers.
A practical ordering key looks like:
occurred_at(source time, normalized)ordering_group(e.g., session, day-bucket, or device sequence window)source_priority(only as a tie-breaker)timeline_item_id(final deterministic tie-break)
Handling clock skew without chaos
If you ingest from devices, clock skew is inevitable. You don’t need perfect clocks—you need stable rules.
Use:
- normalized occurred_at (with bounded skew correction)
- sequence numbers when available (device monotonic counters)
- and a clear policy: “If skew exceeds X minutes, bucket by ingest day but preserve original occurred_at as metadata.”
That last clause is important: don’t hide truth—annotate it.
Reconciliation rules (merging, superseding, and correcting)
Reconciliation is how you prevent a timeline from “rewriting itself” while still accepting corrections.
Think in three operations:
Merge (decorate the same item)
A later enrichment adds fields without changing the core meaning.
- Example: “Meal detected” later gains “calories estimate”.
Supersede (replace with a newer version)
A correction invalidates part of the earlier fact.
- Example: “Weight reading” corrected after calibration update.
Retract (rare, but real)
A signal is deemed invalid.
- Example: false positive detection.
The key infrastructure decision: don’t mutate history silently. Instead:
- keep the core fact immutable where possible
- represent corrections as new events that map deterministically to:
- the same item (merge), or
- a replacement item linked by
supersedes_item_id
This lets the UI render stable transitions:
- “Updated” badge
- “Corrected value” callout
- “Reclassified” label
Late arrivals without user confusion
Late arrivals are normal. The question is whether the timeline jumps.
Use snapshot boundaries
A snapshot is a stable rendered view of a timeline segment—commonly:
- per day
- per session
- per “story arc” (e.g., a meal window)
Within a snapshot boundary, you can accept late arrivals with rules like:
- if new data affects only decorations → update in place
- if it changes ordering → avoid reshuffling unless it crosses a threshold
(e.g., “within the same minute” vs “moves across hours”)
Prefer “append with context” over “reorder everything”
If an event arrives extremely late, the UX-friendly move is often:
- keep the original position
- add a small “Late update” chip
- link to the corrected or related item
Engineers sometimes resist this because it’s not a perfect historical ordering. But remember the goal: stable narrative.
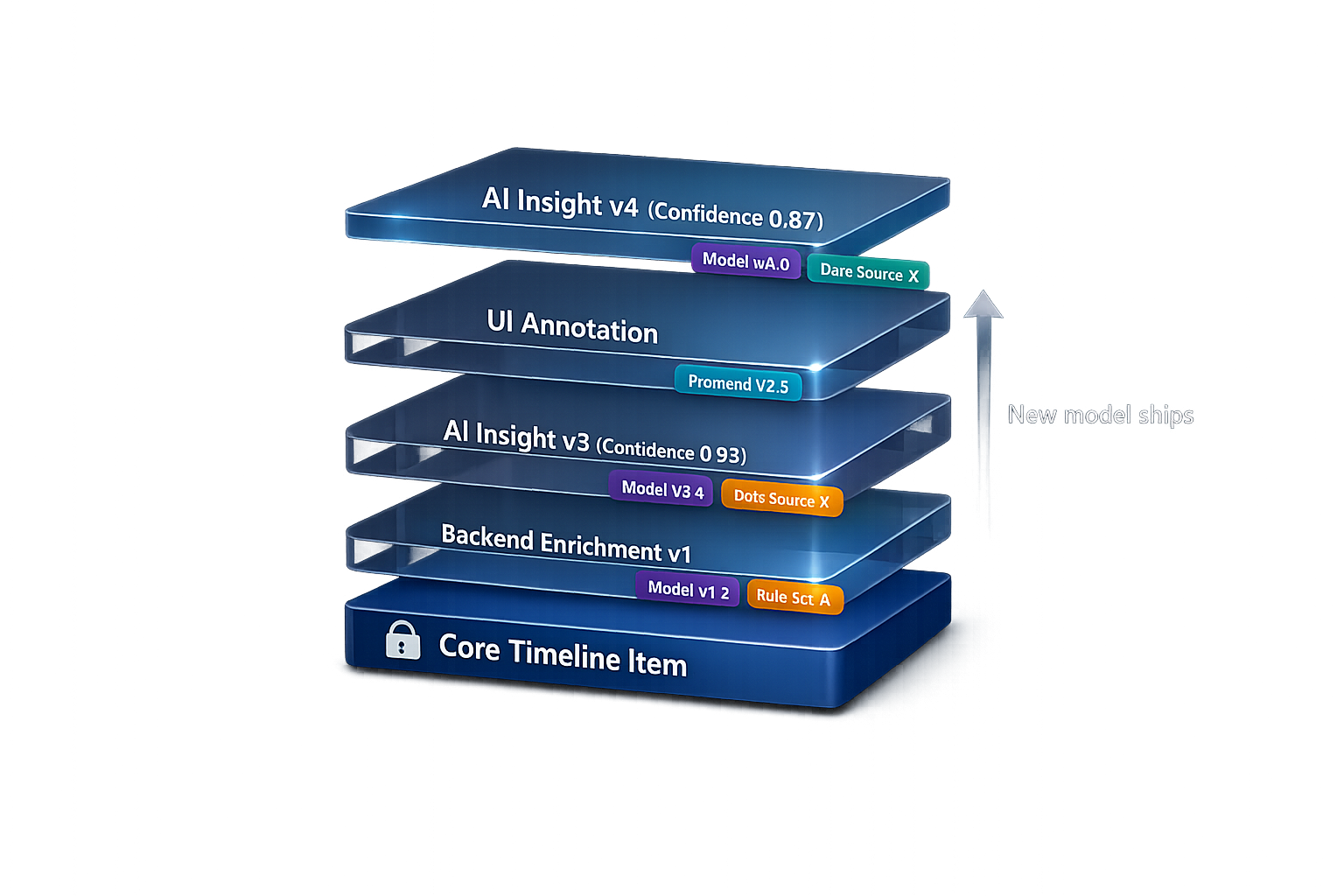
Decorations: enrichments and AI insights as overlays, not edits
This is where most timelines become unstable.
If AI insights overwrite the base item, you force users to re-learn the past every time the model changes.
Instead, treat AI and enrichments as decorations:
- Decorations have their own IDs
- Decorations are versioned
- Decorations carry provenance:
- model version
- feature flags
- confidence
- inputs used
Separate “facts” from “interpretations”
A clean mental model:
- Facts (core): “A meal event occurred at 7:12 PM.”
- Interpretations (decorations): “Likely eating behavior,” “Portion estimate,” “Nutrition suggestion.”
This supports safe iteration:
- you can improve interpretation logic without rewriting facts
- you can roll back interpretations without breaking the timeline

Controlled updates: diff-based rendering and stability
Once items and decorations are stable, you can serve the timeline in a way that prevents UI churn.
Serve diffs, not full refreshes
The API shape matters. A stable pattern:
GET /timeline?cursor=...returns:items[](stable IDs)decorations[](stable IDs + versions)next_cursor- optional
snapshot_id
Then:
- if a decoration updates, you send only decoration diffs
- if a correction supersedes an item, you send:
- new item
- link to superseded ID
- a small “state transition” payload the UI can render gracefully
Track “narrative stability” as a metric
Instead of only measuring relevance, measure stability:
- Reorder rate: how often items change position after first seen
- Mutation rate: how often core fields change after initial render
- Decoration churn: how often AI overlays change meaning vs just adding detail
- Explainability coverage: % of items that can show provenance + “why” metadata
These are the metrics that correlate with trust.
Replayability and explainability are non-negotiable
When something looks wrong, you need to answer:
- “What inputs produced this?”
- “What rules applied?”
- “What changed between yesterday and today?”
Make the pipeline replayable
Replay means:
- given the same event log + same config versions → you produce the same timeline items
- given a new pipeline version → you can measure diffs intentionally
Key practices:
- version your reconciliation rules
- version your decoration logic
- store provenance metadata with outputs
- keep raw events immutable (or at least append-only with retractions)
Provide an “explain” view
Even if users never see it, engineers (and support) will. An explain response for an item should include:
- contributing events (IDs + sources)
- applied reconciliation rule IDs
- decoration versions + confidence
- whether skew correction was applied
- whether the item was superseded
A practical checklist for building this in production
If you’re implementing timeline assembly as infrastructure, this checklist gets you 80% of the way:
Canonical model
- Every event has
event_idandlogical_id - Provenance is captured (source + lineage)
- Occurred time is normalized and stored alongside raw time
Determinism
- Timeline item IDs are stable across replays
- Ordering uses semantic time + deterministic tie-breakers
- Reconciliation is rule-driven and versioned
Late data
- Snapshot boundaries prevent full reshuffles
- Corrections become explicit transitions, not silent edits
AI + enrichments
- Insights are decorations with version + confidence
- Facts remain stable; interpretations evolve transparently
Ops
- Replay tooling exists (at least for a subset)
- Explain view exists for every item type
- Stability metrics are tracked (reorder, mutation, churn)
Hoomanely builds connected pet experiences where device signals, app actions, and intelligence must come together as a coherent story—without surprising pet parents. Treating timeline assembly as infrastructure strengthens that story: it keeps narratives stable as devices retry, enrichments arrive late, and AI improves over time. The result is simple: timelines that feel trustworthy, even when the system behind them is distributed and continuously learning.
Takeaways
- A timeline is a product surface, not a query result.
- Determinism starts with identity: logical IDs and stable item IDs.
- Ordering must be arrival-independent, with explicit tie-breakers.
- Corrections should be modeled as events that reconcile into stable transitions.
- Enrichments and AI belong in versioned decoration layers, not core edits.
- Replayability + explainability turn timeline bugs from mysteries into diffs.



