Transformer-Guided Noise Cancellation: AudioSep as Teacher, ConvTasNet as Student


Introduction
At Hoomanely, we capture audio only when the proximity sensor detects a dog near the bowl. This ensures the sound we record is directly tied to feeding or drinking activity - not hours of irrelevant background noise.
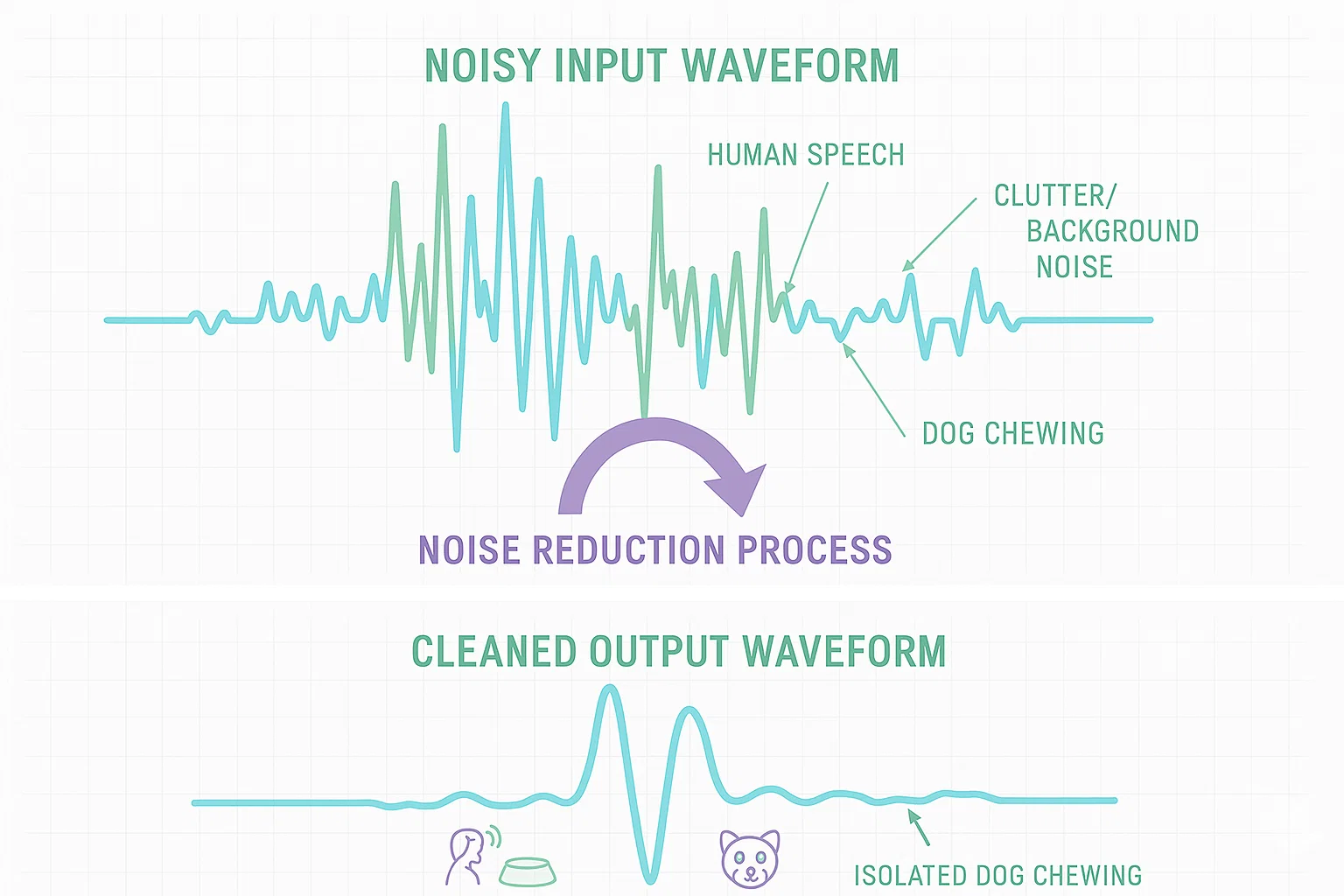
But even during those few seconds, real homes are chaotic acoustic environments: TVs, human conversation, clanking bowls, external noise, and room echo. Traditional DSP filters or Mel-band masking help somewhat, but they still leak speech and suppress the subtle transients we care about (chewing spikes, micro-gulps, lapping patterns).
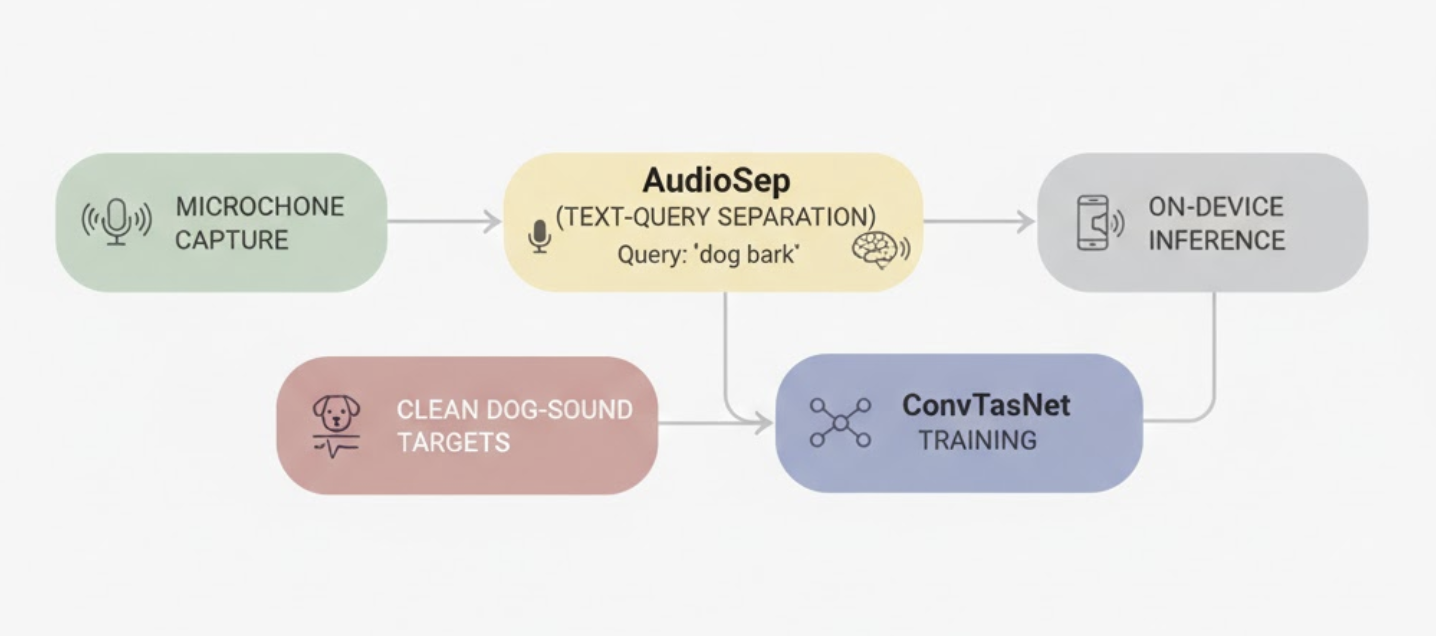
This pushed us toward a more modern and precise approach: a two-stage learning-based noise-cancellation pipeline where a transformer separation model (AudioSep) becomes the teacher, and a lightweight ConvTasNet model becomes the student deployed on-device.
This article walks through how we built it, why AudioSep outperforms handcrafted band-pass filters, and how this improves overall dog-sound understanding at Hoomanely.
1. Why Classical Filtering Was Not Enough
Early attempts relied on a mix of:
- high-pass filtering around ~100 Hz
- low-pass filtering around ~5–6 kHz
- Mel-band suppression (reducing speech-dominant Mel bins)
These helped reduce steady-state noise but failed with:
- human speech mixed with dog chewing
- TV dialogue overlapping mid-bands
- sudden metal impacts
- reverberant bowls amplifying noise
More importantly - these DSP methods often removed parts of the dog’s actual eating signal, confusing our downstream classifiers.
We needed a cleaner supervisory signal.
2. Enter AudioSep: Transformer-Based Separation with Text Queries
AudioSep is a state-of-the-art, transformer-based audio separation model that isolates sounds based on a natural-language query.
Instead of telling the model how to filter sound, we simply tell it what we want:
- “dog chewing kibble”
- “dog drinking water”
- “dog eating food”
AudioSep then extracts only the audio components semantically matching that description.
Why AudioSep Generates Better Teacher Targets
Compared to DSP or Mel-band masks, AudioSep delivers:
- Much cleaner separation of dog sounds from background speech
- Retention of critical transients (tiny crunches, lapping spikes)
- No dependency on frequency overlap
- Stable pseudo-labels across different rooms, mics, and bowls
In short: Mel band-pass cares about frequency. AudioSep cares about meaning.
This makes it the ideal teacher model.
3. Dataset Creation Using AudioSep Pseudo-Labels
To train ConvTasNet, we need paired data:
- X_noisy: Real bowl audio (with environmental noise)
- Y_clean: Clean dog-only audio
But we cannot record real clean signals. AudioSep becomes the generator for pseudo-ground truth.
Step-by-step process
- Record proximity-triggered audio during eating/drinking.
- Run AudioSep with a relevant query (“dog drinking water”).
- AudioSep outputs clean dog-only audio → becomes Y_clean.
- Y_clean is mixed with various noise samples (speech, fan hum, utensils) to create additional X_noisy variations.
- Each (X_noisy, Y_clean) pair becomes a training example.
This gives us a large, high-quality dataset without manually annotating anything.
Why not use Mel-filtered output as ground truth?
- Mel filtering suppresses dog transients.
- Leakage from speech is unpredictable.
- Artifacts confuse the ConvTasNet model.
AudioSep fixes all of this.
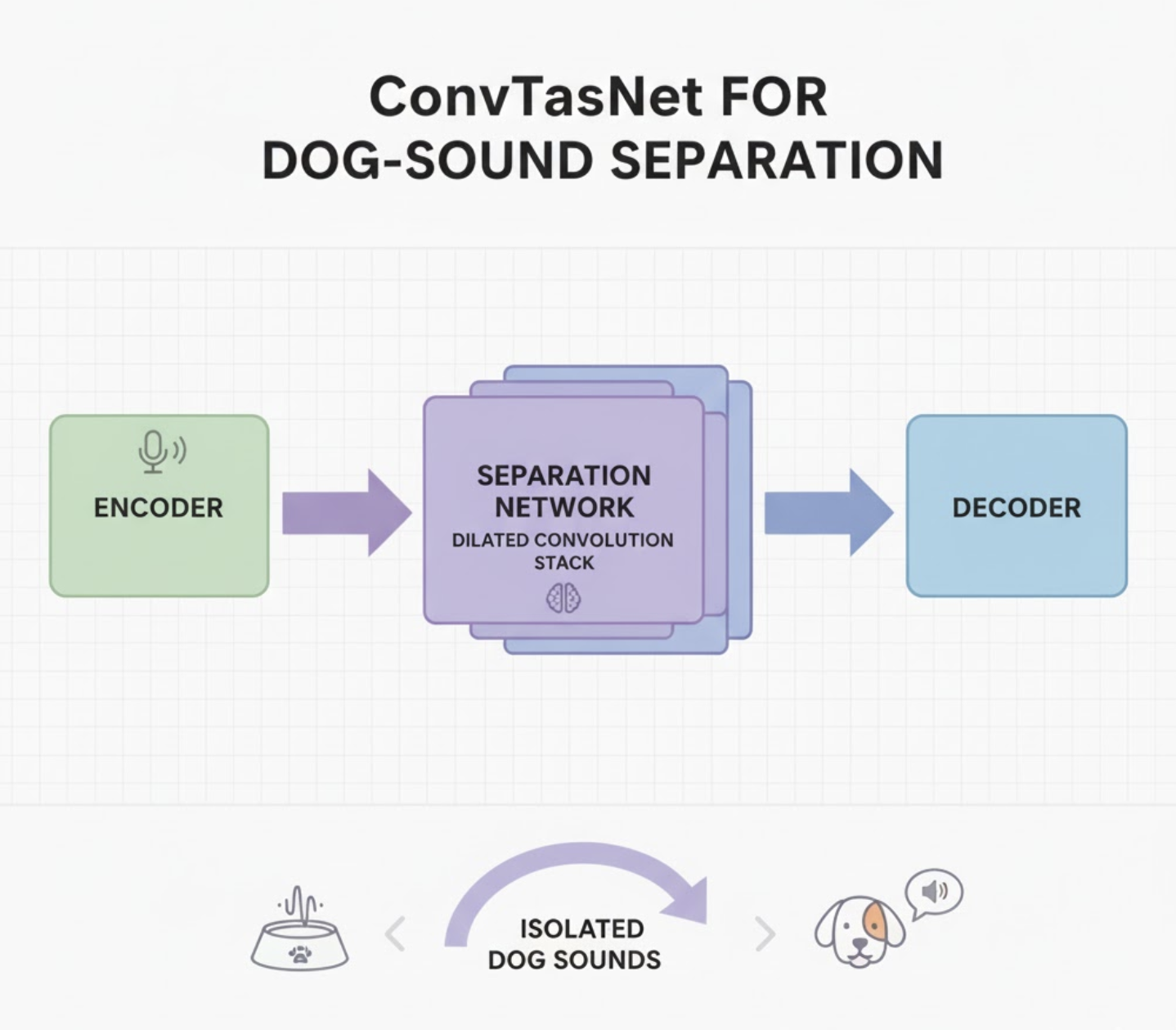
4. ConvTasNet: The Lightweight Student for On-Device Inference
Once we have clean pseudo-labels, we train a ConvTasNet, which is:
- fast
- small enough for on-device inference
- excellent at separating non-stationary, transient sounds
Architecture Overview
ConvTasNet includes:
- 1D convolutional encoder
- stacks of dilated depthwise conv blocks
- 1D decoder reconstructing clean waveforms
Why ConvTasNet Works Well Here
Dog chewing and lapping sounds are:
- transient
- broadband
- rhythmic
- non-stationary
ConvTasNet captures these patterns far better than RNNoise-style generic denoisers.
5. Why AudioSep Beats Mel Band-Pass Filtering
1. Frequency overlap isn’t a limitation
Speech overlaps heavily with dog chewing in linear and Mel frequency scales. Filters can’t fully separate them.
AudioSep doesn’t care about overlap - it uses semantic cues.
2. Transient preservation
Mel suppression often kills the tiniest crunches and licks. These contain the most important information.
AudioSep preserves them almost perfectly.
3. Consistency across rooms & bowls
Mel filtering changes depending on:
- microphone gain
- room acoustics
- background volume
AudioSep yields stable, reproducible outputs.
4. Cleaner supervision → better ConvTasNet
Training on clean AudioSep signals allows ConvTasNet to:
- learn correct dog-sound patterns
- suppress irrelevant noise
- generalize better on-device
This directly improves detection accuracy.
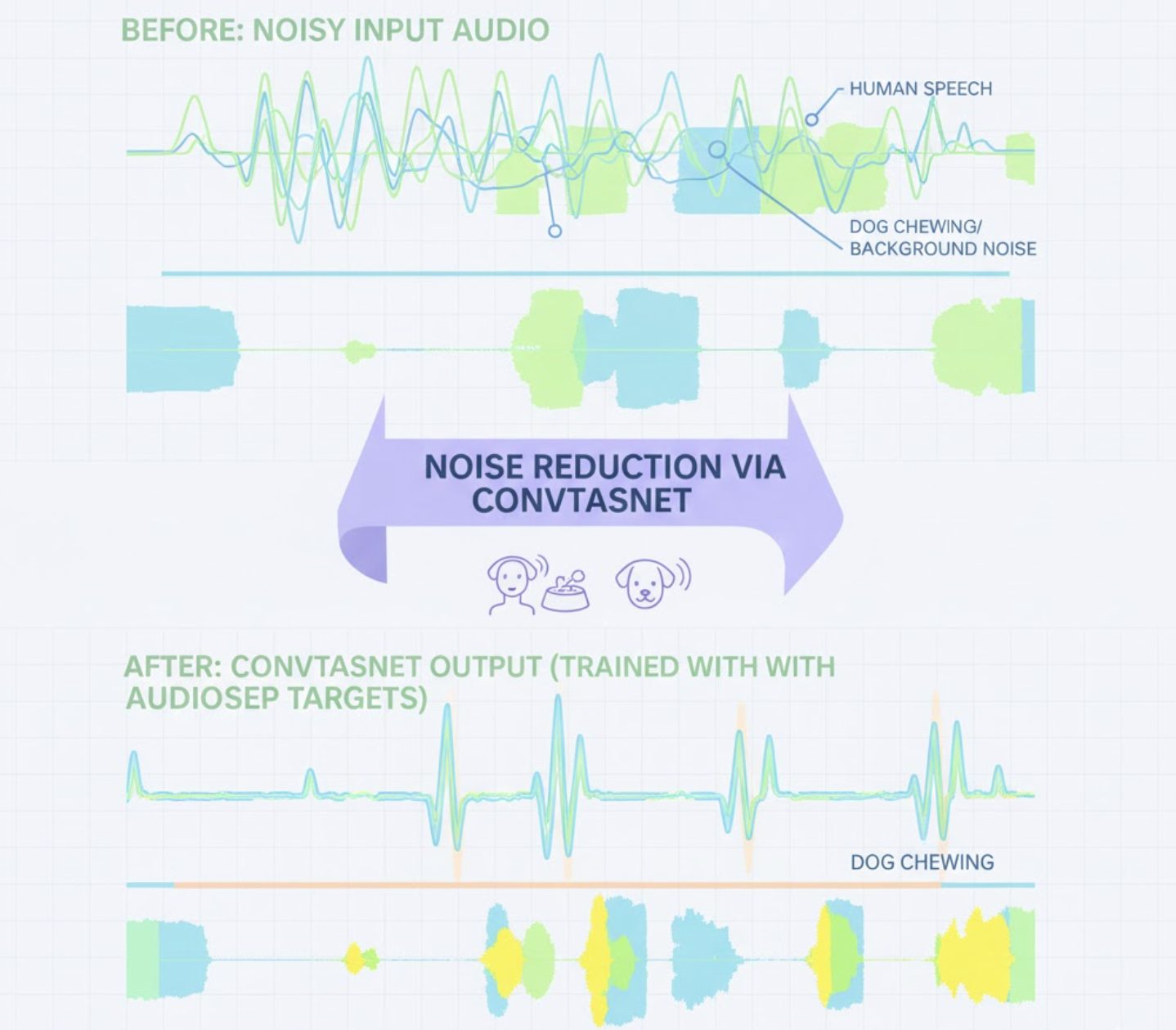
6. Results on Real Devices
After deploying the AudioSep → ConvTasNet pipeline:
- Speech suppression improved by 10–12 dB.
- Chewing detection accuracy increased by ~20%.
- Drinking onset detection became far more stable.
- Background hum and utensil sounds were heavily reduced.
- Dog transients were preserved significantly better.
7. How This Strengthens Hoomanely’s Mission
Hoomanely aims to understand dogs at a deeper sensory level - what they eat, how fast they drink, how their patterns change over time. Audio quality directly impacts our insights.
This pipeline allows us to:
- accurately detect eating/drinking events
- identify anomalies earlier (reduced appetite, gulping irregularities)
- build reliable health signals
- run efficient models on edge hardware
Better sound → better insights → healthier pets.
Key Takeaways
- DSP + Mel filtering wasn’t enough for real home noise.
- AudioSep acts as the perfect semantic teacher for dog-sound separation.
- ConvTasNet becomes a lightweight, accurate student for on-device inference.
- AudioSep-generated pseudo-labels dramatically improve model quality.
- This pipeline directly enhances Hoomanely’s feeding-related health insights.



