Two-Tier Sensor Queue: Surviving BLE Dropouts at 100Hz

A pet wearable streams six-axis motion data at 100 Hz to a home hub over Bluetooth Low Energy. The dog walks into the next room. The wall absorbs more RF than the supervision timeout can tolerate, and the link drops. Twelve seconds later the dog walks back out and the link comes up again.
What happened to the 1,200 motion samples in flight during those twelve seconds?
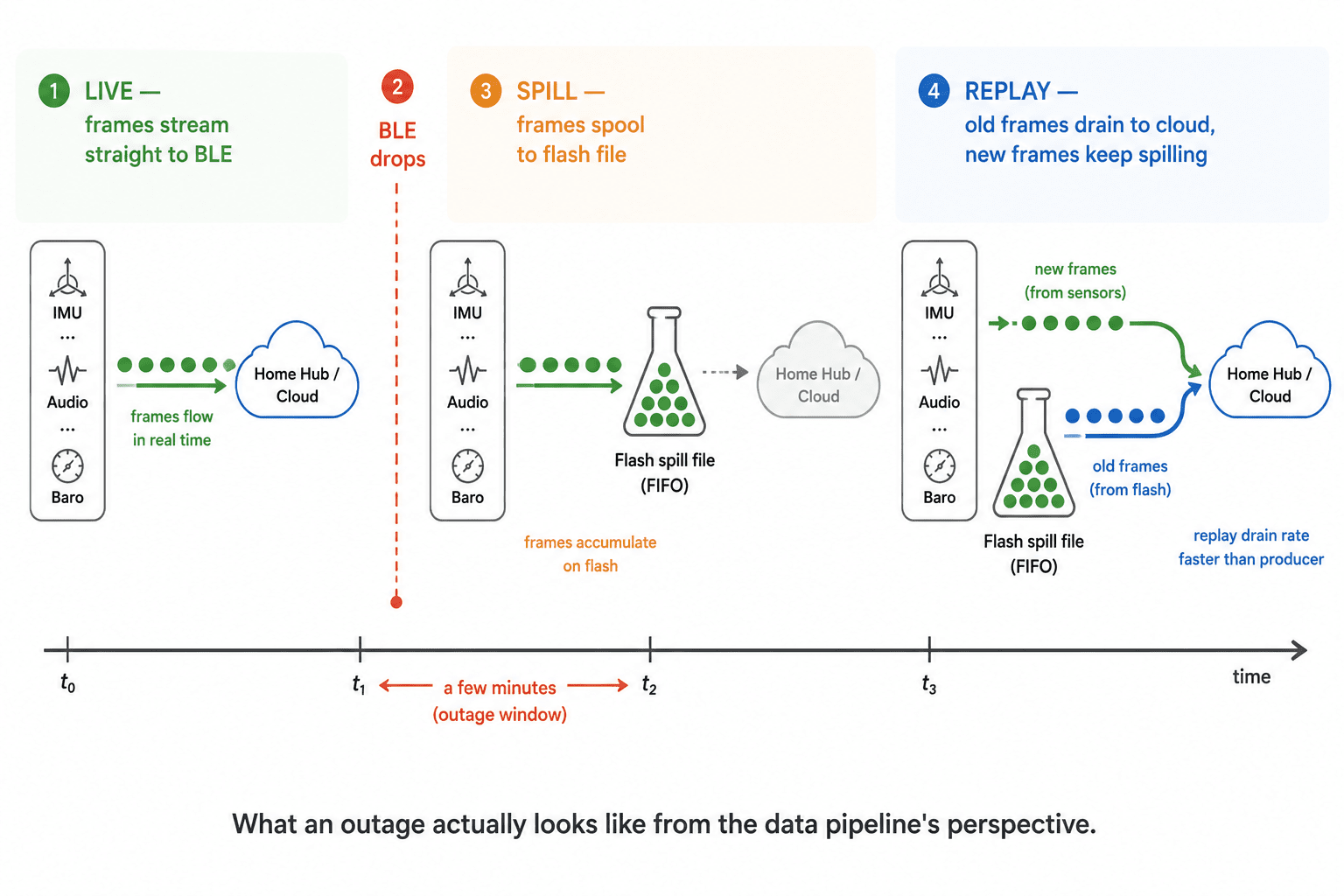
If the firmware was streaming naively, those samples are gone, and the activity timeline a veterinarian later reads has a 12-second hole right where the dog did something. This post walks through the two-tier persistent queue we built to make that hole impossible: a RAM ring buffer in front of a flash-backed spill file, governed by a three-mode state machine, with strictly chronological FIFO replay when the link returns.
Problem
Wearables don't get to choose where their owner walks. Even in an apartment, BLE link supervision tears down a connection after a few hundred milliseconds of consecutive missed packets, much shorter than the time a pet spends behind a couch.
The naive options all fail the same way. Drop on disconnect is easy to implement but destroys the dataset for any analysis, gait, sleep, activity bouts, that needs continuity. Blocking the producer when BLE is down holds up the IMU task and drops samples elsewhere, usually with worse failure modes. And one large single-tier RAM buffer works for a few seconds, then either you size it for the 99th-percentile outage and pay the RAM cost, or you blow up under real-world conditions.
The right pattern is a two-tier queue: a fast in-RAM ring for in-flight frames, plus a persistent flash file that holds everything the ring can't immediately deliver. A mode state machine arbitrates who reads the ring and where the data goes next. Crucially, this is not just a buffer, it's a timeline-preserving buffer. When the link comes back, the cloud must see frames in the same order the sensors recorded them, or downstream models that look at sequences fall apart.

Approach
The design uses three storage stages and a strict state machine.
Tier 1: RAM ring buffer. A FreeRTOS MessageBuffer at 192 KB. Producers (IMU sample-batcher, audio capture, barometer) push frames here unconditionally. Writes are an O(1) memcpy; nothing in the ring can block on flash I/O.
Tier 2: append-only flash file. Lives on the external flash filesystem, survives reboots. Each frame is written with dual length tags, a uint16 length prefix before the payload and an identical uint16 length suffix after it. The duplicate tag is the load-bearing design choice; with it, a reader can walk the file head-to-tail or tail-to-head with no index file.
Three-mode state machine governs who reads the ring and where the data goes:
// file_operations.c:154
static op_mode_t compute_mode(void)
{
/* BLE down: only path to preserve frames is the flash spill. */
if (!s_ble_up) return MODE_SPILL;
/* BLE up + persisted backlog: send oldest persisted data first
* (FIFO walk — see drain_replay). */
if (spill_size() > 0) return MODE_REPLAY;
/* BLE up + no backlog: stream ring -> BLE directly. */
return MODE_LIVE;
}LIVE means BLE up, spill empty, ring under 75% capacity, so the drain task ships frames from the ring directly over BLE. SPILL means BLE down (or ring at or above 75% as back-pressure relief), so the spill task is the sole ring consumer and everything it pulls goes into the flash file. REPLAY means BLE up but the flash file still holds backlog, so producer writes continue to spool into the file while the drain task pulls frames out and onto BLE.
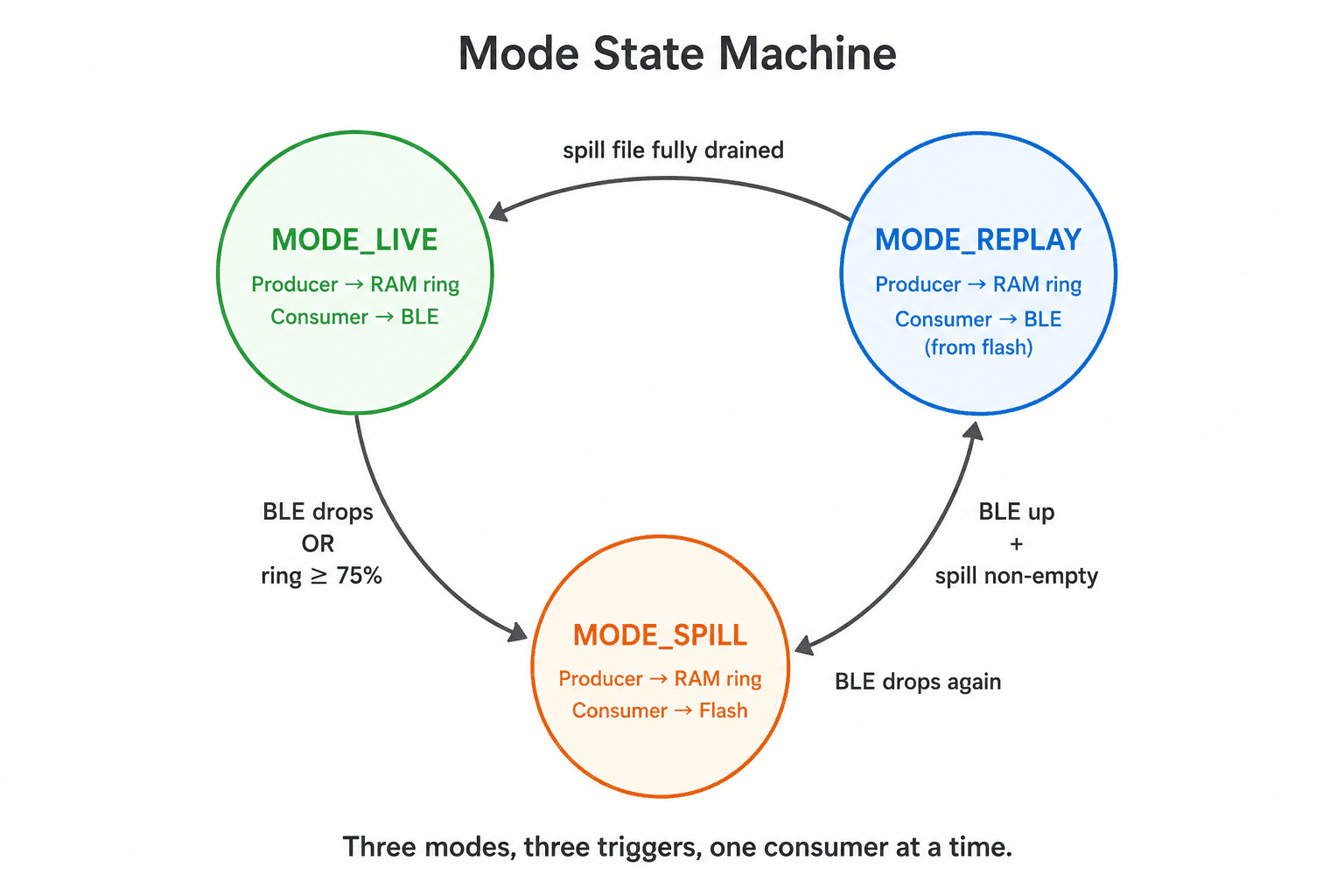
The state machine guarantees a single consumer of the ring at any instant, and a single reader of the flash file during REPLAY, which is what makes the design safe under sustained throughput.
Process
One write() per frame. The instinct is to write the leading length tag, then the payload, then the trailing tag, three write() syscalls per frame. Through the VFS layer of a flash filesystem, each call grabs an internal mutex; three writes per frame turned the spill task into the bottleneck.
// file_operations.c:343
static void spill_one_frame(const uint8_t *buf, size_t got)
{
/* Build the framed bytes (header + payload + trailer) in one
* contiguous buffer so we do exactly ONE write() syscall per frame
* instead of three. FATFS goes through VFS and grabs an internal
* mutex on every write — three writes per frame turned the spill
* task into the bottleneck (~33 fps, vs producer rate ~95 fps for
* audio bursts), causing sustained ring overflow. With one
* write() per frame the spill task stays comfortably ahead. */
static uint8_t framed[MAX_FRAME_BYTES + 4];
framed[0] = (uint8_t)(got & 0xFF);
framed[1] = (uint8_t)((got >> 8) & 0xFF);
memcpy(&framed[2], buf, got);
framed[2 + got] = (uint8_t)(got & 0xFF);
framed[2 + got + 1] = (uint8_t)((got >> 8) & 0xFF);
write(s_spill_fd, framed, got + 4);
}Measured before and after: spill throughput climbed from about 33 frames per second, bottlenecked on filesystem mutex contention, to comfortably ahead of even audio-burst producer rates around 95 fps.
Writing the length prefix before reading the payload. During replay, frames are packed into a fixed-size batch buffer that's handed to the BLE transport in one shot. The trick is the order:
// file_operations.c:756 (drain_replay, FIFO forward walk)
size_t prefix_at = batch_used;
batch[batch_used++] = (uint8_t)(flen & 0xFF);
batch[batch_used++] = (uint8_t)((flen >> 8) & 0xFF);
if ((size_t)read(s_replay_fd, &batch[batch_used], flen) != flen) {
ESP_LOGE(TAG, "replay: payload read failed");
batch_used = prefix_at;
break;
}
batch_used += flen;
batch_frames++;
s_replay_pos = next_pos;We write the 2-byte length tag into the batch buffer first, then read the payload directly behind it. If the read fails, the saved prefix_at offset rewinds batch_used cleanly so the partial frame doesn't pollute the next send.
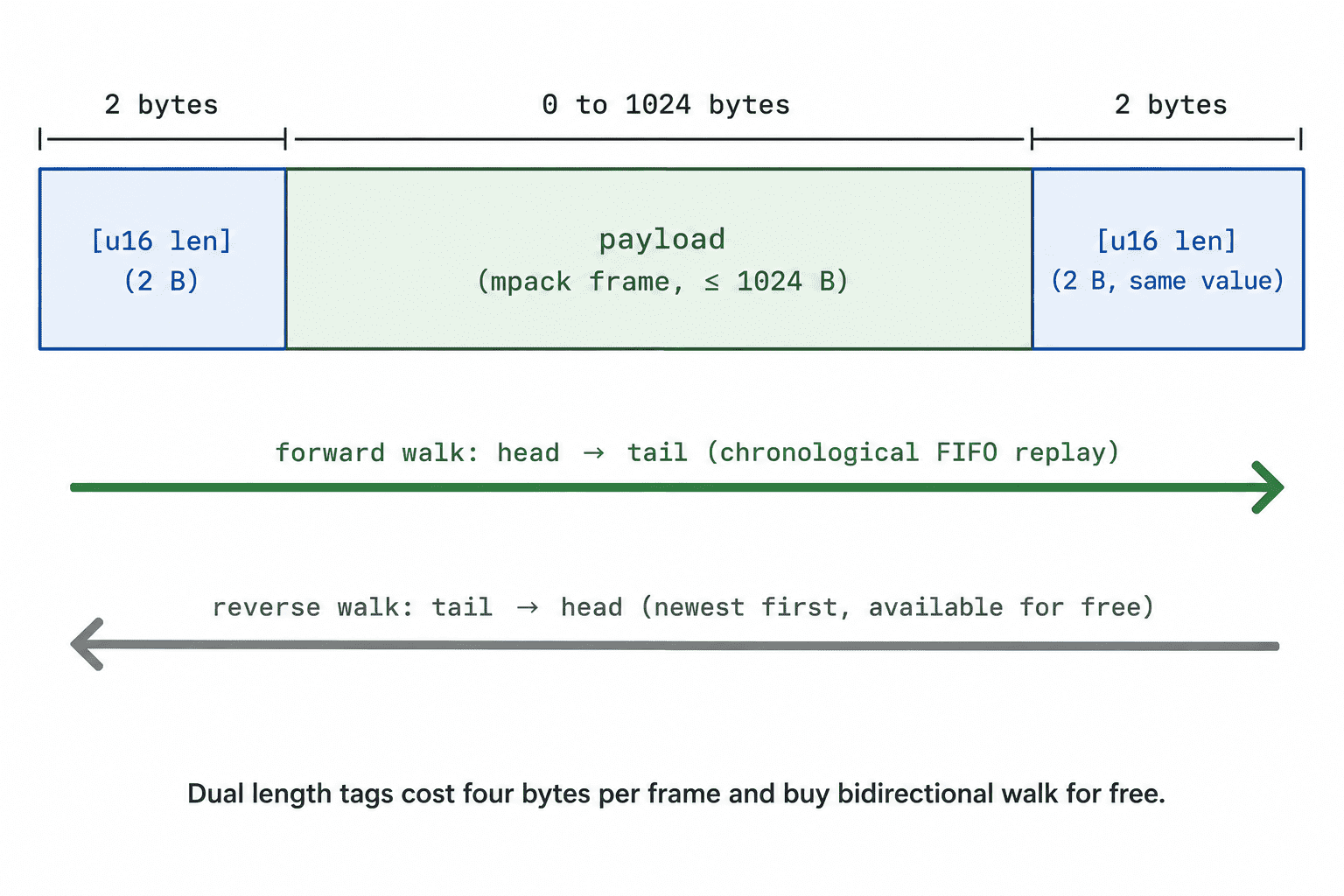
Results
The state machine plus this framing gives a few non-obvious properties. No frames are lost across typical, minutes-long BLE outages, since the flash spill scales far beyond realistic in-home dropouts. Replays are chronological by default, since walking the file head-to-tail reconstructs the timeline in the same order sensors recorded it, and the dual-tag framing means flipping to tail-first is a three-line change. The system survives reboots, since a brown-out or watchdog reset during an outage simply leaves the file on disk, and the next boot picks up replay from where it left off, in order. And there's exactly one consumer at a time, no racing readers, no dual-handle filesystem hazards.
Why it matters at Hoomanely
Everything the Biosense AI Engine concludes about a pet's gait, restlessness, sleep, or distress depends on whether the firmware delivered a complete, ordered, time-true record of what the sensors saw. A model trained on data with random 12-second holes learns the wrong thing. A model that sometimes sees yesterday's frames replayed in reverse learns very wrong things. The two-tier queue isn't a buffer, it's the load-bearing contract between sensors at the edge and intelligence in the cloud.
Key takeaways
A single buffer is never enough, separate RAM (fast, lossy on full) from flash (persistent, slow). A state machine beats flag checks, three modes, three triggers, one consumer at a time. Framing decides walk direction, dual length tags cost four bytes per frame and buy the freedom to choose chronological or freshest-first replay without an index file. Measure where you actually lose frames, our biggest win came from collapsing three write() syscalls into one. And the replay path is the rare path, test it under load, since it's the one that bites in production.