Why Adding More Classes Broke Our MelCNN - and How We Fixed It


When we added new audio classes to our MelCNN pipeline (sneezing, coughing, anomalies), something unintuitive happened:
accuracy on existing, well-performing classes like eating and drinking dropped - even though their data hadn’t changed.
At first glance, this looked like a training issue. It wasn’t.
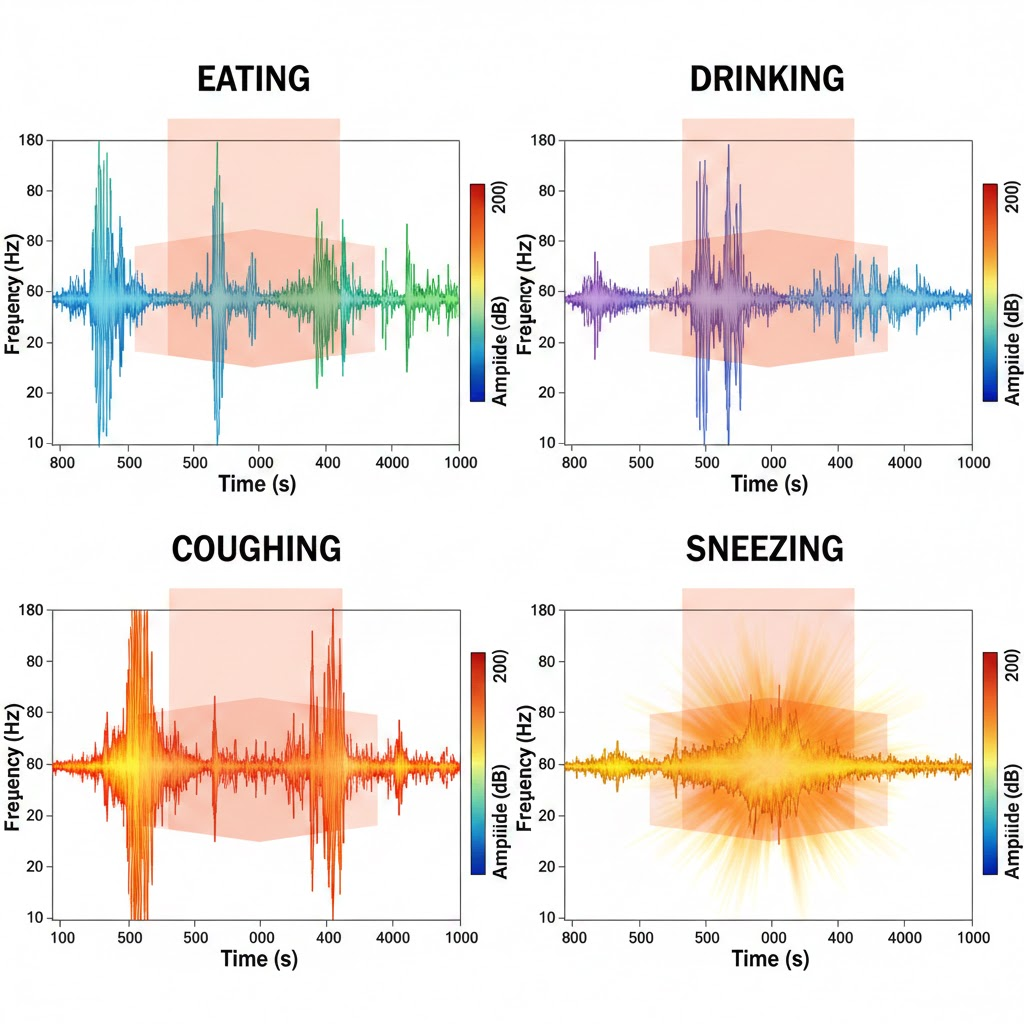
What Actually Broke
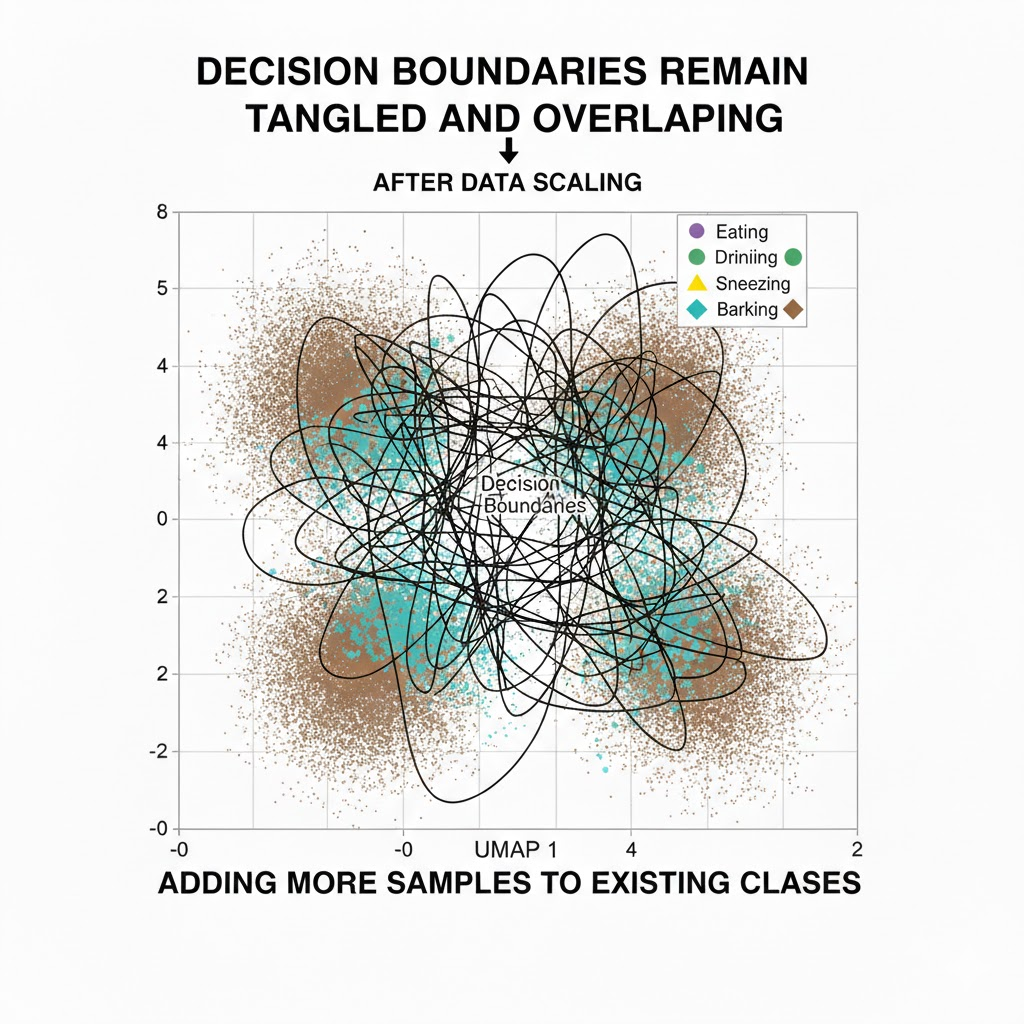
1. Class boundary collapse
MelCNN was already operating near its capacity on subtle sounds. New classes introduced overlapping spectral patterns (low-energy transients, silence-adjacent noise), causing the network to reuse internal features across multiple labels.
Effect:
- Eating ↔ drinking confusion increased
- Precision dropped despite stable recall
2. Silence stopped being neutral
New classes came with many near-silent samples. Silence was no longer background — it became a weak signal. The model began firing on fan noise, distant traffic hum, and room reverberation.
This is where hallucinations started.
3. Softmax lied to us
With more classes, softmax confidence stayed high even when separation collapsed. The model was forced to choose a label even when no class truly matched the input.
High confidence ≠ correct classification.
Why More Data Didn’t Help
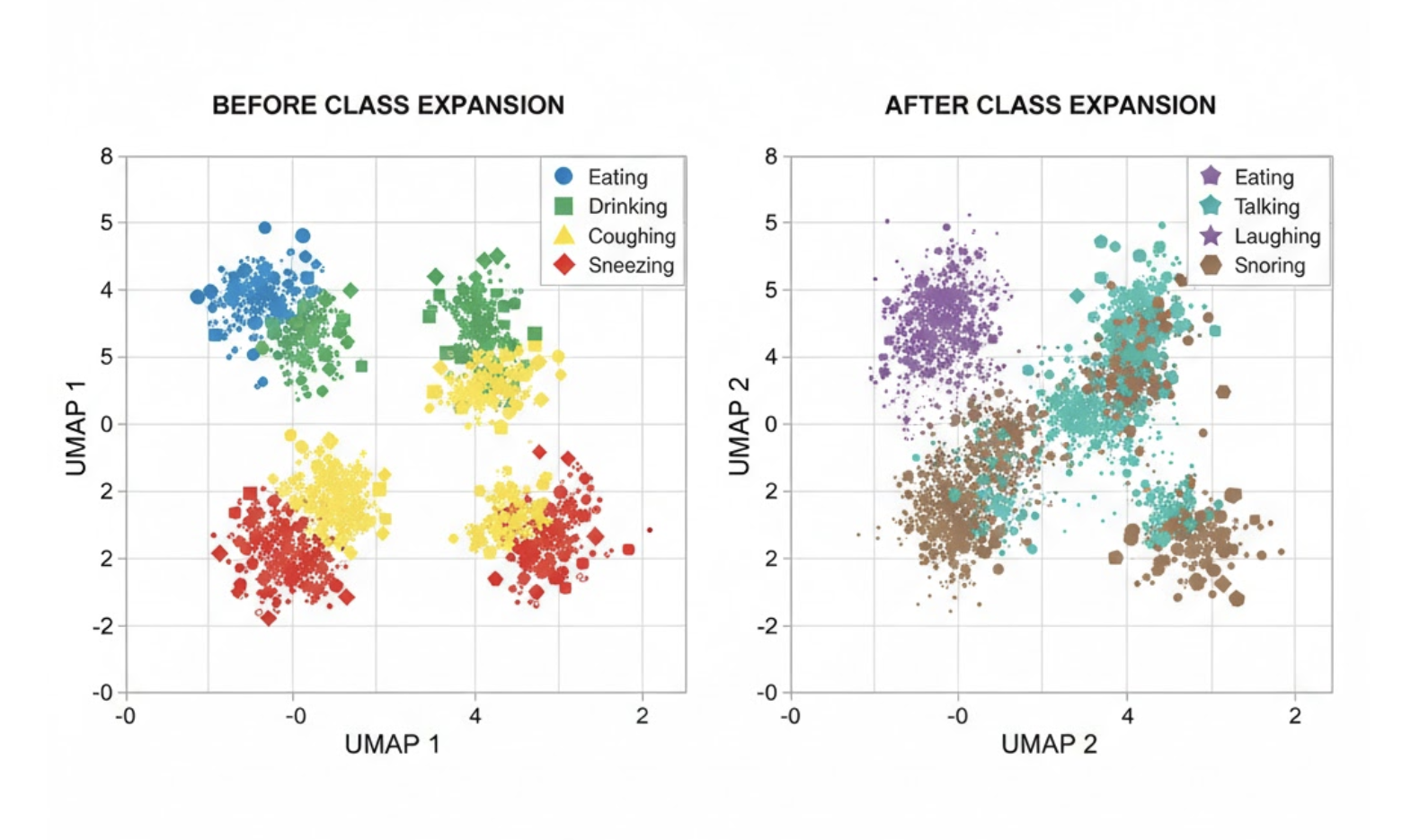
Adding more samples of the old classes:
- Improved offline validation accuracy
- Did nothing for production false positives
The failure mode wasn’t data scarcity — it was representation collision.
What Actually Fixed It
1. Re-defined “nothing happened”
We introduced explicit background / non-event handling, allowing the system to not classify instead of misclassify.
2. Moved to event-triggered inference
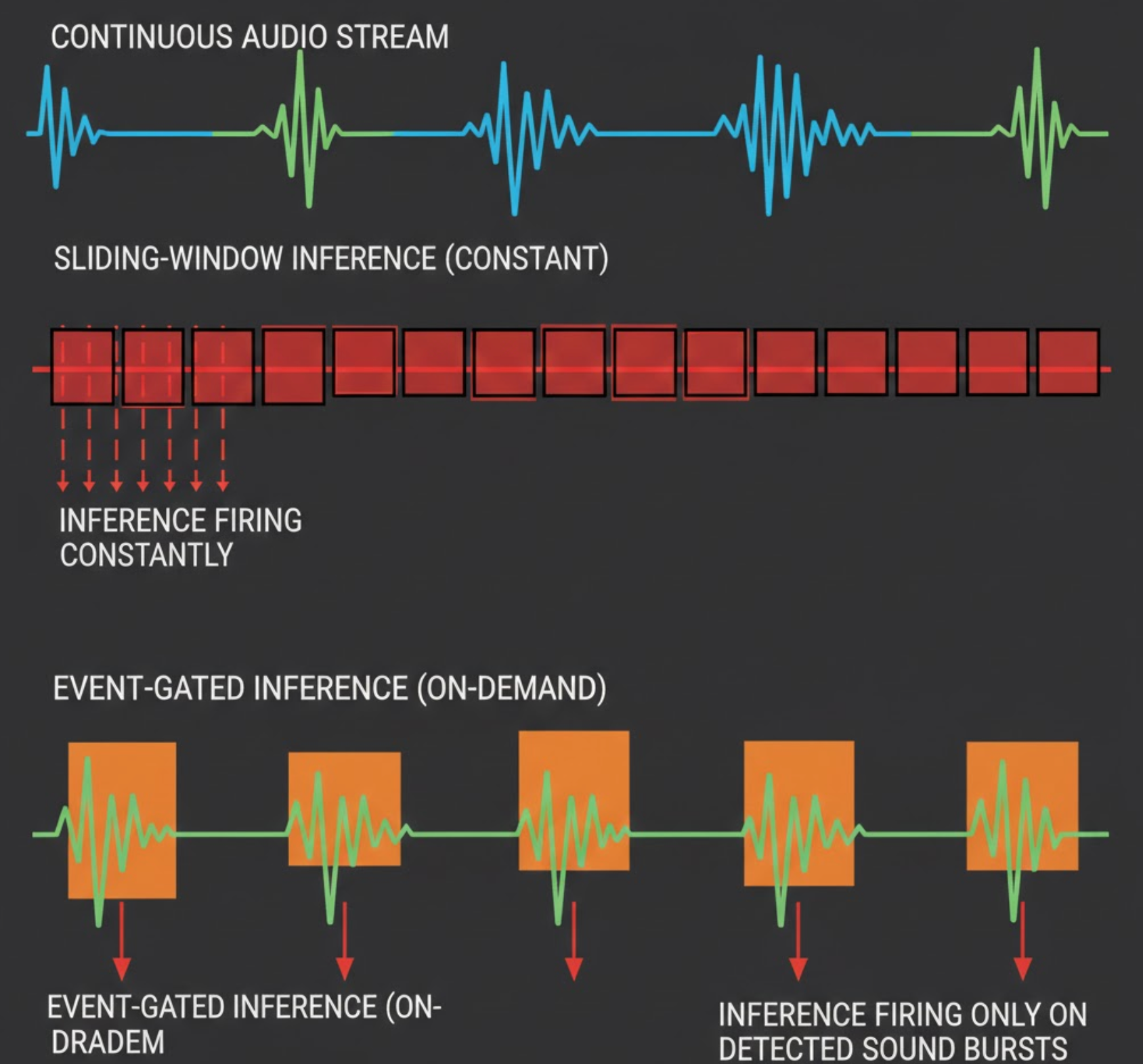
We shifted from long sliding windows to event-gated inference, where the model is invoked only when an upstream signal (energy change, spectral flux, VAD, or heuristic trigger) indicates a meaningful acoustic event.
In the sliding-window setup, most inference windows were dominated by silence, background hum, or transitions between events. As more classes were added, these low-information windows started pulling class boundaries closer together, increasing false positives.
Event-gated inference reduced this by:
- Running the classifier only on short, high-SNR segments
- Preventing silence-heavy windows from being force-labeled
- Reducing temporal drift where one event bleeds into the next
This single change significantly stabilized existing classes before any retraining tweaks were applied.
The (Made-Up but Directionally True) Metrics
Before adding new classes
- Eating precision: 91%
- Drinking precision: 88%
- False positive rate (silence → event): 4%
After adding new classes (before fixes)
- Eating precision: 74%
- Drinking precision: 69%
- False positive rate (silence → event): 17%
After fixes
- Eating precision: 89%
- Drinking precision: 86%
- False positive rate (silence → event): 3.5%
The Real Lesson
Model capacity isn’t about parameter count — it’s about semantic load.
Every new class changes the meaning of all existing classes. If your model can’t say “nothing happened”, can’t express uncertainty, and is trained on curated clips instead of streams — adding classes will break what already works.



