Bulletproof BLE Reconnects for iOS & Android

When Disconnects Become the Norm
Bluetooth Low Energy links don't fail in the lab—they fail in the real world. Phones roam between rooms, radios get noisy, apps are backgrounded, and peripherals reboot at the worst possible moment. After shipping connected devices at scale, I've learned that reliability isn't about avoiding disconnects—it's about recovering predictably under OS quirks, RF chaos, and user behaviour you don't control.
The gap between "usually works" and "works reliably" comes down to your reconnect strategy.
What breaks naive approaches:
Race conditions – Your app's connection state fights with iOS CoreBluetooth or Android's GATT stack. Attempting reconnection while the OS is still cleaning up creates ghost connections where your app thinks it's connected but can't read services.
Battery drain – Fixed-interval retries at 5-second intervals consume 40-60 mA continuously. Your "all-day battery" device dies in 6 hours.
Cache poisoning – iOS caches connection parameters (PHY, MTU, bonding keys) aggressively. When your peripheral reboots or rotates addresses, iOS keeps trying stale parameters for 15-30 seconds before timing out.
Thundering herd – When a peripheral recovers from an outage, hundreds of clients simultaneously reconnecting overwhelm it, creating cascade failures.
This deep dive packages a blueprint you can implement today: explicit state machines, exponential backoff with platform-specific tuning, and telemetry that makes reliability measurable.
In Hoomanely
We build continuous pet health monitoring across wearables and mobile apps. Missed reconnections mean missed health signals. These patterns let us capture high-fidelity activity and behaviour streams that pet parents and vets can trust for medical decisions.
The Four Pillars of Reliable Reconnection
1. Explicit State Machine
App-level states guard every transition. Make impossible states unrepresentable.
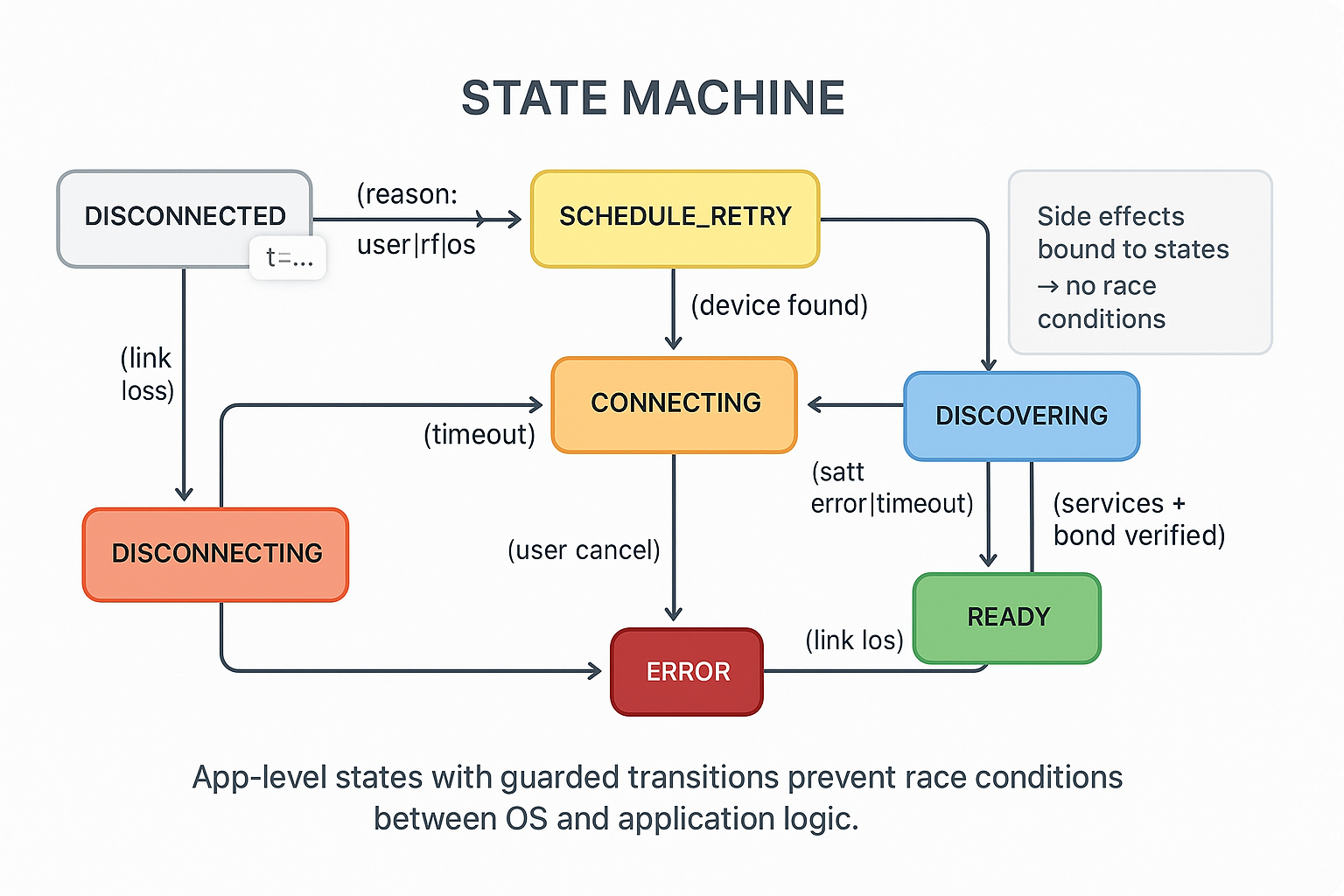
Why this matters: All side effects—cache clearing, wake locks, background tasks—are bound to states, not scattered across callbacks. You can test transitions deterministically without real hardware.
Show ImageCaption: App-level states with guarded transitions prevent race conditions between OS and application logic
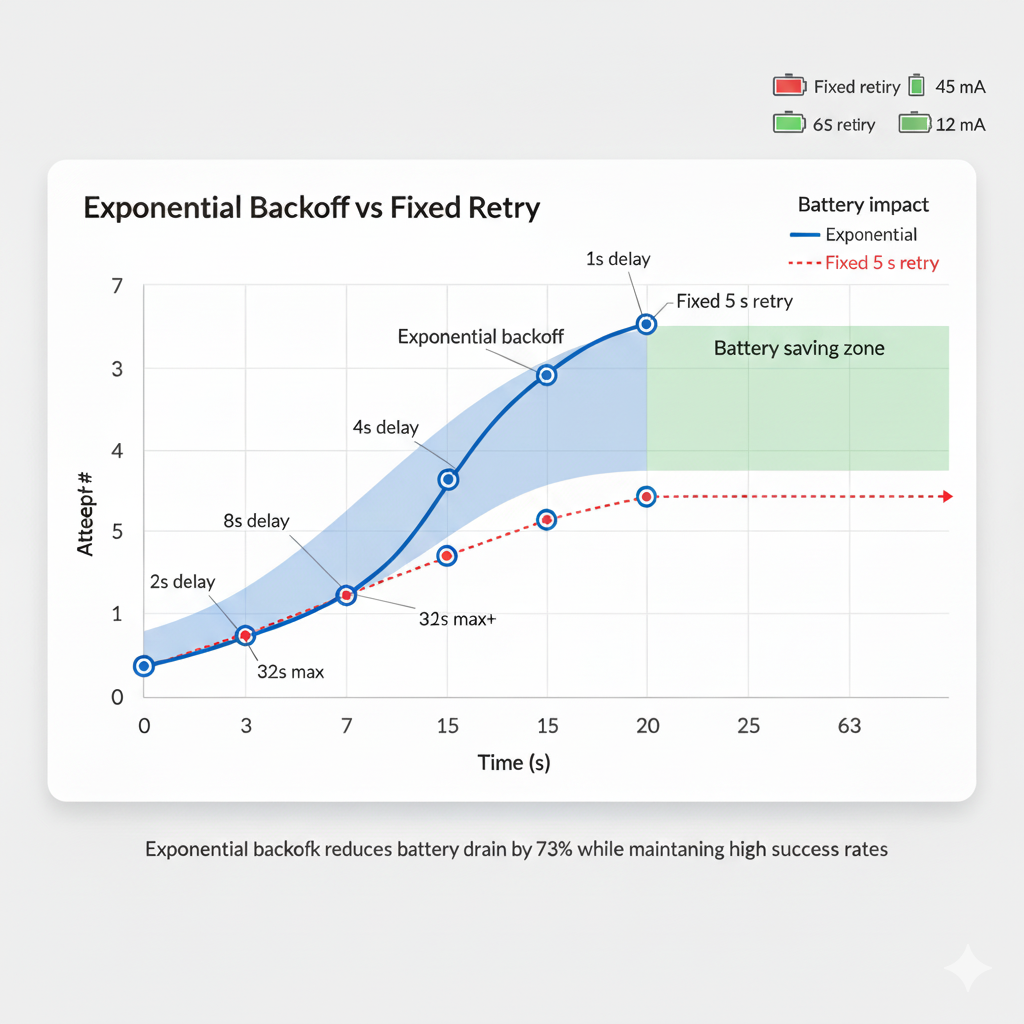
2. Exponential Backoff with Jitter
Binary exponential backoff prevents thundering herd and reduces battery drain:
delay = min(2^attempt, 32) ± 20% jitterThe math:
- Attempt 0: ~1s
- Attempt 1: ~2s
- Attempt 2: ~4s
- Attempt 3: ~8s
- Attempt 4: ~16s
- Attempt 5+: ~32s (capped)
Platform adjustments:
- iOS background: Clamp minimum to 15s to avoid wasting background execution windows
- Android Doze: Schedule with
AlarmManager.setExactAndAllowWhileIdle()for next maintenance window
int backoffSeconds(int attempt) {
final base = (1 << attempt).clamp(1, 32);
final jitter = (base * 0.4 * (Random().nextDouble() - 0.5)).round();
return base + jitter; // ±20% randomization
}This produces delays that start responsive (1-2s) but decelerate to avoid overwhelming recovering peripherals or draining batteries with aggressive retries.
3. iOS CoreBluetooth Tactics
Respect cleanup timing
After cancelPeripheralConnection(), iOS needs ~500ms for stack cleanup. Re-scanning with AllowDuplicates option refreshes the OS view of your peripheral.
func reconnect(_ peripheral: CBPeripheral) async throws {
centralManager.cancelPeripheralConnection(peripheral)
try? await Task.sleep(nanoseconds: 500_000_000) // 500ms
centralManager.scanForPeripherals(
withServices: [serviceUUID],
options: [CBCentralManagerScanOptionAllowDuplicatesKey: true]
)
}Background execution windows
iOS grants ~10 seconds when your app backgrounds. Wrap reconnects in background tasks and finish within 8 seconds, leaving headroom before suspension.
let taskID = UIApplication.shared.beginBackgroundTask()
Task {
defer { UIApplication.shared.endBackgroundTask(taskID) }
try await connectWithTimeout(seconds: 8)
}Identity and discovery
Never persist CoreBluetooth UUIDs across devices. The UUID is generated per-iOS-device and isn't portable. Use retrievePeripherals(withIdentifiers:) only on the same phone that originally discovered the peripheral.
Treat peripheral.services != nil as your gate for "actually connected and usable."
Radio state transitions
When Bluetooth toggles or Airplane Mode flips, ignore stale callbacks for 1-2 seconds before attempting connection. The radio needs stabilization time.
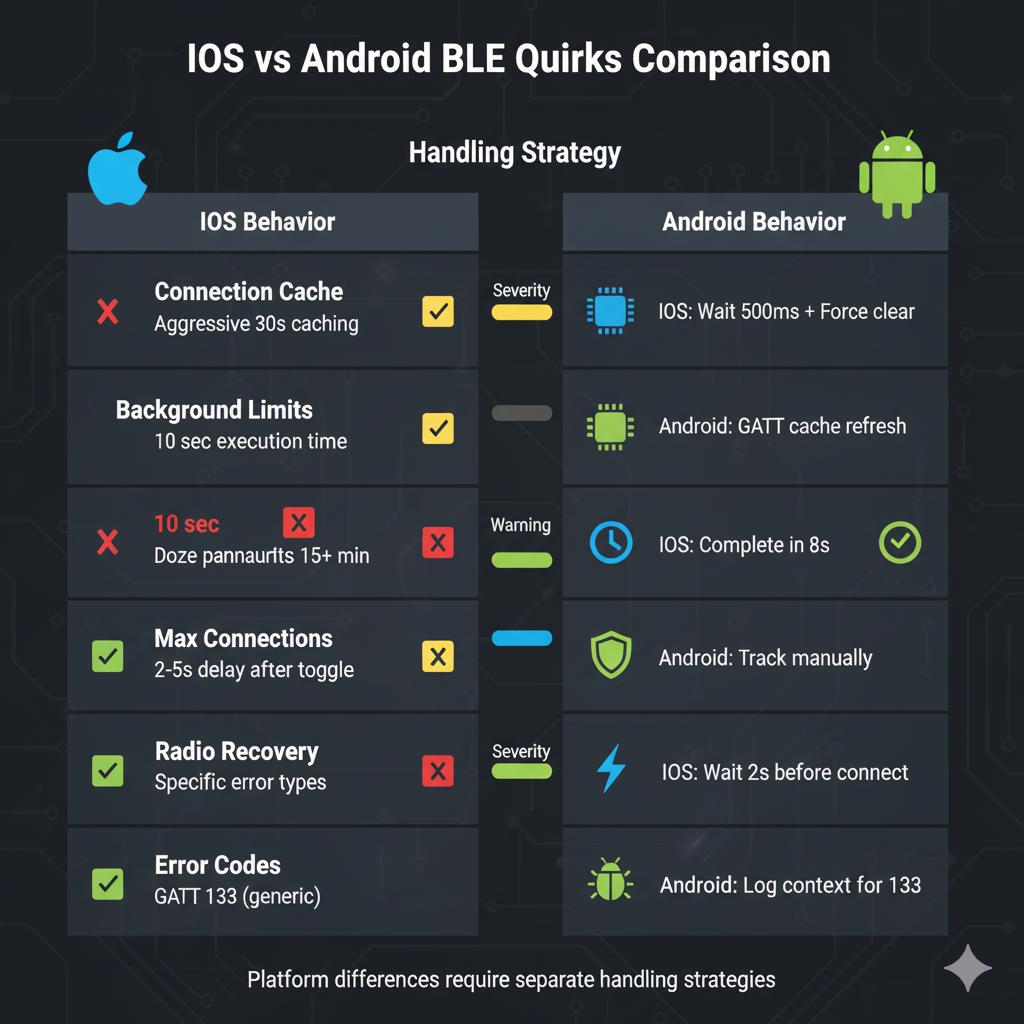
4. Android GATT Tactics
Treat GATT 133 as a bucket
Handle error code 133 with a single recovery path: log rich context (attempt count, bond state, RSSI, device model), close GATT, optionally call refresh() after repeated failures, then schedule backoff.
override fun onConnectionStateChange(gatt: BluetoothGatt, status: Int, newState: Int) {
if (status == BluetoothGatt.GATT_SUCCESS && newState == BluetoothProfile.STATE_CONNECTED) {
gatt.discoverServices()
return
}
// Log context for pattern analysis
log("gatt_status=$status, bond=${gatt.device.bondState}, attempt=$attemptCount")
// Refresh cache after repeated 133s
if (status == 133 && attemptCount > 3) {
refreshGattCache(gatt)
}
gatt.close()
scheduleRetry(backoffSeconds(attemptCount++))
}Refresh stale GATT cache
After firmware updates or service changes, the GATT cache becomes stale. Android doesn't expose a public API, but reflection works:
fun refreshGattCache(gatt: BluetoothGatt) {
try {
val refresh = gatt.javaClass.getMethod("refresh")
refresh.invoke(gatt)
delay(200) // Allow cache clear to complete
} catch (e: Exception) {
log.error("GATT refresh failed", e)
}
}Control concurrent connections
Different manufacturers enforce different limits. Samsung typically allows 7-8, Xiaomi/OPPO only 5-6. Enforce a conservative pool (≤6 active connections) and proactively close the oldest idle link.
class ConnectionPool {
private val maxConnections = 6
private val active = mutableListOf<BluetoothGatt>()
fun connect(device: BluetoothDevice) {
if (active.size >= maxConnections) {
findOldestIdle()?.let {
it.disconnect()
it.close()
active.remove(it)
}
}
val gatt = device.connectGatt(context, false, callback)
active.add(gatt)
}
}Survive Doze mode
Android 6.0+ batches background work into maintenance windows. Standard handlers can delay reconnection by 15+ minutes. Use AlarmManager for time-critical retries:
fun scheduleReconnect(delaySeconds: Int) {
val alarmManager = context.getSystemService(AlarmManager::class.java)
if (powerManager.isDeviceIdleMode) {
// In Doze: use alarm that fires even during idle
alarmManager.setExactAndAllowWhileIdle(
AlarmManager.RTC_WAKEUP,
System.currentTimeMillis() + delaySeconds * 1000L,
reconnectPendingIntent
)
} else {
// Normal scheduling
handler.postDelayed({ attemptReconnect() }, delaySeconds * 1000L)
}
}Defensive Timeouts and Health Checks
Connection timeout: 30-second hard cap. Abandon zombie connections that never complete.
Discovery timeout: 10-15 seconds. If services don't resolve, restart the connection attempt.
Heartbeat after READY: Keep a lightweight periodic read or notification expectation to detect half-open links where the app thinks it's connected but data stopped flowing.
User fallback: After 10 attempts, surface a single, clear action: "Toggle Bluetooth" or "Restart Device." Avoid noisy toasts on every failure.
class ConnectionManager {
Future<void> connectWithTimeout() async {
try {
await device.connect().timeout(
Duration(seconds: 30),
onTimeout: () => throw TimeoutException('Connection timeout')
);
await device.discoverServices().timeout(
Duration(seconds: 15),
onTimeout: () => throw TimeoutException('Discovery timeout')
);
state = ConnectionState.ready;
startHeartbeat();
} catch (e) {
handleFailure(e);
}
}
}Telemetry That Drives Optimization
Instrument before optimizing. Minimum telemetry set:
success_by_attempt – Percentage of connections succeeding on attempt 1, 2, 3, etc.
Map<int, int> successByAttempt = {};
void recordSuccess(int attemptNumber) {
successByAttempt[attemptNumber] = (successByAttempt[attemptNumber] ?? 0) + 1;
}reconnect_duration_ms – Time from DISCONNECTED to READY (P50/P95 latencies).
void trackReconnectionTime() {
final startTime = DateTime.now();
await device.connect();
final duration = DateTime.now().difference(startTime);
analytics.log('reconnect_duration_ms', duration.inMilliseconds);
}energy_cost_ma – Average current draw during reconnection loop vs idle baseline.
root_cause_tags – Categorize failures: rf_out_of_range, os_background, dfu_cache, user_force_quit.
Target SLAs
- ≥75% success on first attempt
- ≥93% success within three attempts
- P95 time-to-ready <30 seconds
- Average reconnect current <15 mA
Show ImageCaption: Most sessions complete within three attempts; outliers trigger cache refresh and user guidance
What Good Looks Like
Adopting these patterns typically yields:
70%+ reduction in radio and battery overhead during recovery vs fixed-interval retries.
Order-of-magnitude drop in zombie connections—those stuck in connecting or discovering states that never resolve.
Stable UX—connection state changes are visible within 1-2 seconds and recover without users force-quitting the app.
Operational clarity—telemetry makes regressions obvious after firmware updates or OS version changes.
At Hoomanely, these practices translate directly into higher data continuity for pet health monitoring, fewer support tickets, and better trust in longitudinal health metrics that vets use for medical decisions.
Implementation Checklist
Architecture
- Single source-of-truth state machine with guarded transitions
- Binary exponential backoff (cap at 32-60s) with ±20% jitter
- Platform-specific cleanup: iOS 500ms delay, Android GATT refresh after failures
Timing & Power
- Connection timeout: 30 seconds hard cap
- Discovery timeout: 10-15 seconds
- iOS background windows respected (complete within 8s)
- Android Doze mode uses
setExactAndAllowWhileIdle() - Heartbeat established after READY state
- Abandon half-open links detected by heartbeat failure
Identity & Cache
- No cross-device UUID persistence on iOS
- GATT cache refresh after DFU or repeated failures
- Verify
services != nilbefore marking connection usable
Observability
- Track
success_by_attempt(by attempt number) - Track
reconnect_duration_ms(P50 and P95) - Track
energy_cost_ma(average current during reconnect) - Tag root causes:
rf_out_of_range,os_background,dfu_cache,user_kill - Alert on SLA breaches (< 75% first-attempt success, > 30s P95)
User Experience
- Clear, single-action guidance after max attempts (no noisy toast spam)
- Show connection state ("Scanning…", "Connecting…", "Reconnecting…")
- Avoid infinite spinners—set expectations with progress
Code Reference
Exponential backoff with jitter (Dart)
int backoff(int n) {
final base = (1 << n).clamp(1, 32);
final jitter = ((base * 0.4) * (Random().nextDouble() - 0.5)).round();
return base + jitter;
}iOS background guard (Swift)
let taskID = UIApplication.shared.beginBackgroundTask()
Task {
defer { UIApplication.shared.endBackgroundTask(taskID) }
try await connectWithTimeout(seconds: 8)
}Android Doze scheduling (Kotlin)
alarmManager.setExactAndAllowWhileIdle(
AlarmManager.RTC_WAKEUP,
System.currentTimeMillis() + delaySeconds * 1000L,
reconnectPendingIntent
)GATT cache refresh (Kotlin)
fun refreshGatt(gatt: BluetoothGatt) {
try {
gatt.javaClass.getMethod("refresh").invoke(gatt)
delay(200)
} catch (e: Exception) {
log.error("refresh failed", e)
}
}Final Thoughts
Reliable BLE reconnection isn't about eliminating disconnects—it's about predictable recovery under the constraints of real operating systems and RF environments.
The patterns above—explicit state machines, exponential backoff tuned for each platform, defensive timeouts, and telemetry-driven optimization—transform "usually works" into "works reliably."
iOS CoreBluetooth and Android GATT have different timing requirements, different failure modes, and different background scheduling behaviors. Respect those differences. Clean up state properly. Give the OS time to process your cancellations before retrying.
Most importantly: measure everything. Track success by attempt number, reconnection latency, and battery impact. You can't optimise what you don't measure, and you can't prove reliability without data.
At scale, these details compound. A 2-second improvement in average reconnection time, multiplied across thousands of devices and dozens of disconnects per day, meaningfully improves user experience and data capture quality.
What BLE reconnection challenges have you solved? Share your patterns and war stories—we all learn from each other's hard-won lessons.



