Closing the Auto-Labeling Loop with Gemma 4


How we achieved fully automated, production-grade image labeling by adding VLM validation as the final quality gate
The Problem: The Last 15% of Labels Were Garbage
We had built a sophisticated three-stage pipeline (YOLO → Grounding DINO → SAM3) that could generate thousands of segmentation labels automatically. But there was a problem: 15% of the generated labels were unusable.
Closed eyes. Humans in frame. Masks on noses instead of eyes. Thermal artifacts. The classic "last mile" problem of automation—our pipeline was 85% amazing and 15% catastrophically wrong.
Manual review wasn't scalable. We needed thousands of labels, and checking each one manually would take weeks. We needed to close the loop with automated validation.
The Breakthrough: Why Not Just Use "Dog Eye" Detection?
First, let's back up to why we built this pipeline in the first place. The obvious approach seemed simple: use a state-of-the-art object detection model with the prompt "dog eye" and call it a day. But reality had other plans.
The Problem with Direct Detection
We discovered that using "dog eye" as a detection prompt led to a critical failure mode: the model would frequently detect entire dogs instead of their eyes. This happened because:
- Semantic ambiguity: "dog eye" can be interpreted as "an eye belonging to a dog" (what we want) or "a dog-like eye" or even just "dog" (what the model sometimes gives us)
- Visual dominance: Dogs are large, prominent objects in pet camera images, while eyes are small details
- Training data bias: Detection models are often trained on whole-object detection tasks, making them biased toward detecting complete animals
This fundamental issue forced us to rethink our approach entirely.
Our Solution: Close the Loop with VLM Validation
We developed a four-stage pipeline where each stage builds on the previous one, culminating in Gemma 4 VLM validation that acts as an automated quality gate. Here's the complete architecture:
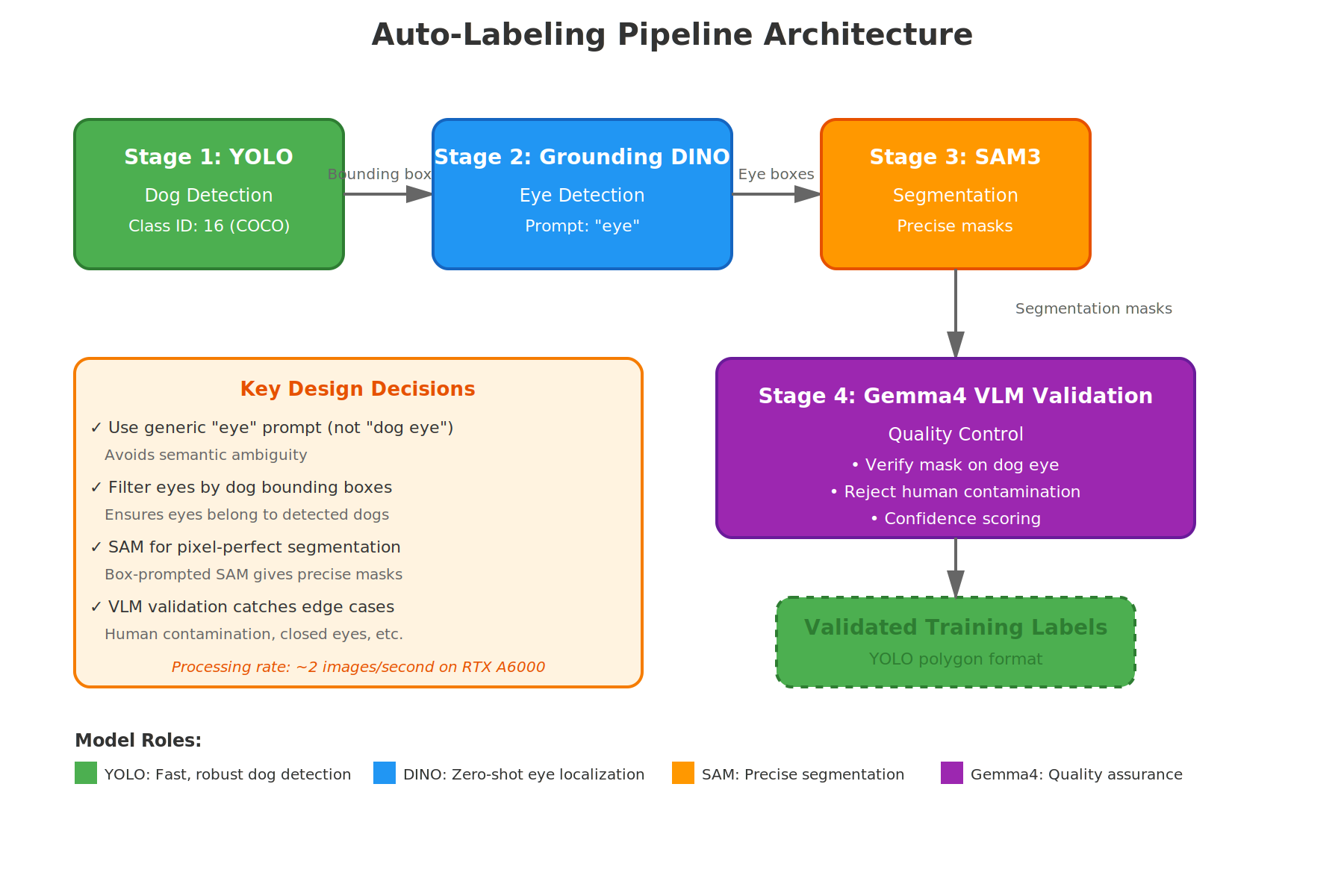
The pipeline consists of four distinct stages:
- YOLO Dog Detection - Quickly locate dogs in images to establish regions of interest
- Grounding DINO Eye Detection - Use generic "eye" prompt to find eye regions (not "dog eye"!)
- SAM3 Segmentation - Convert eye bounding boxes into pixel-perfect segmentation masks
- Gemma4 VLM Validation - Automated quality control to filter out incorrect labels
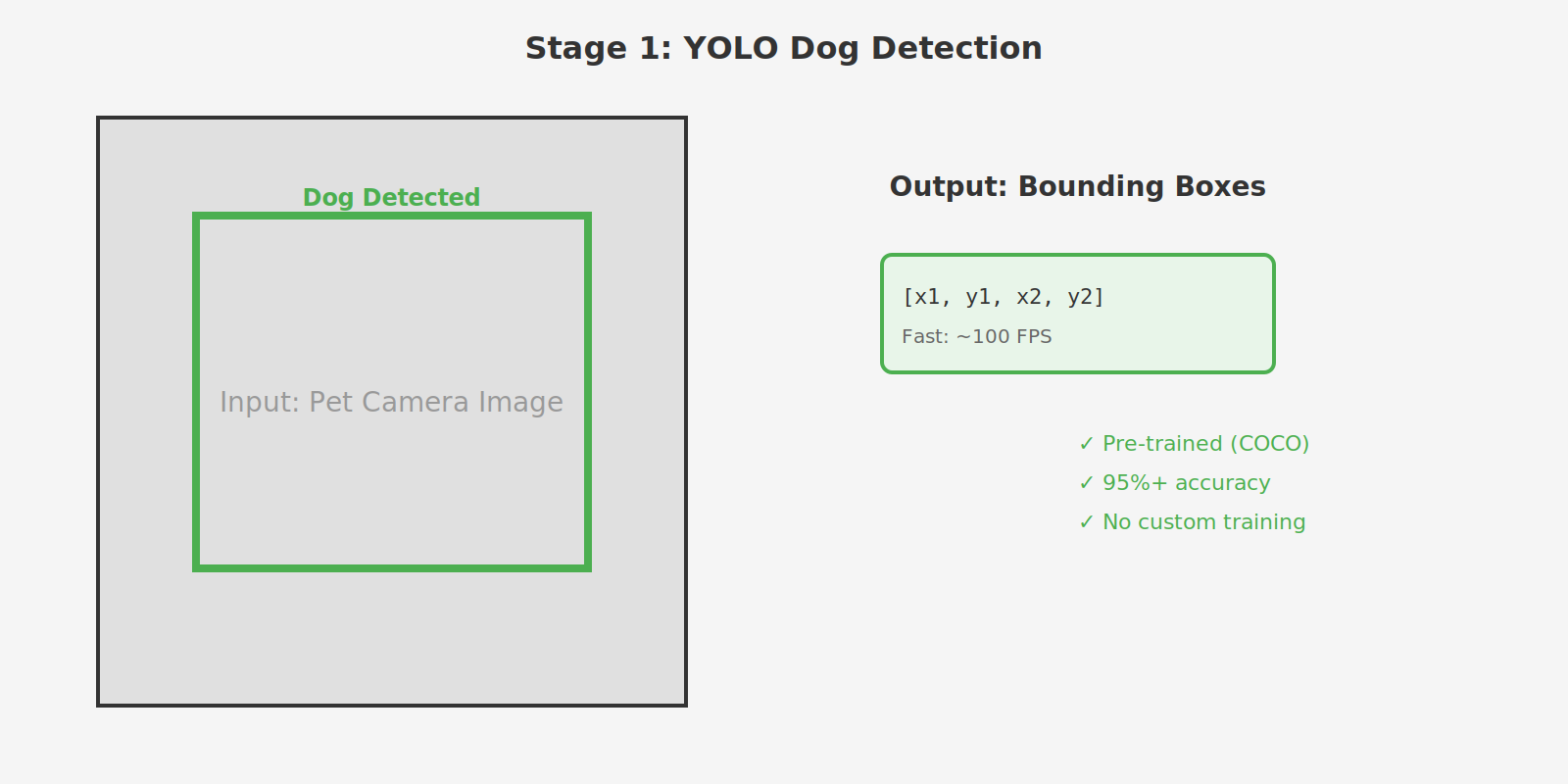
Stage 1: YOLO Dog Detection
Purpose: Locate dogs in the image to establish regions of interest
YOLO (You Only Look Once) is extremely fast and accurate for dog detection. Using the pre-trained COCO weights, we can detect dogs at ~100+ FPS with 95%+ accuracy on pet camera images. This first stage provides tight bounding boxes around dog bodies, which become the spatial filter for the next stage.
Why YOLO?
- Extremely fast inference (~100+ FPS)
- Pre-trained on COCO dataset with excellent dog detection
- Provides tight bounding boxes around dog bodies
- No custom training required
Stage 2: Grounding DINO Eye Detection
Purpose: Locate eye regions within detected dog bounding boxes
The Critical Insight: Instead of using "dog eye" as the prompt, we use the generic word "eye". This simple change makes all the difference:
- ✅ "eye" → Model focuses on eye-like visual features (small, round/oval, reflective)
- ❌ "dog eye" → Model gets confused and often detects entire dogs
By using a generic prompt and then spatially filtering the results to keep only eyes inside dog bounding boxes, we get reliable, repeatable eye detection. This approach also naturally handles multiple eyes per dog (both eyes visible in frontal views, single eye in profile shots).
Why Grounding DINO?
- Zero-shot open-vocabulary detection
- Can detect multiple eyes per dog
- Text-prompt driven, no retraining needed
- Handles various viewing angles and occlusions
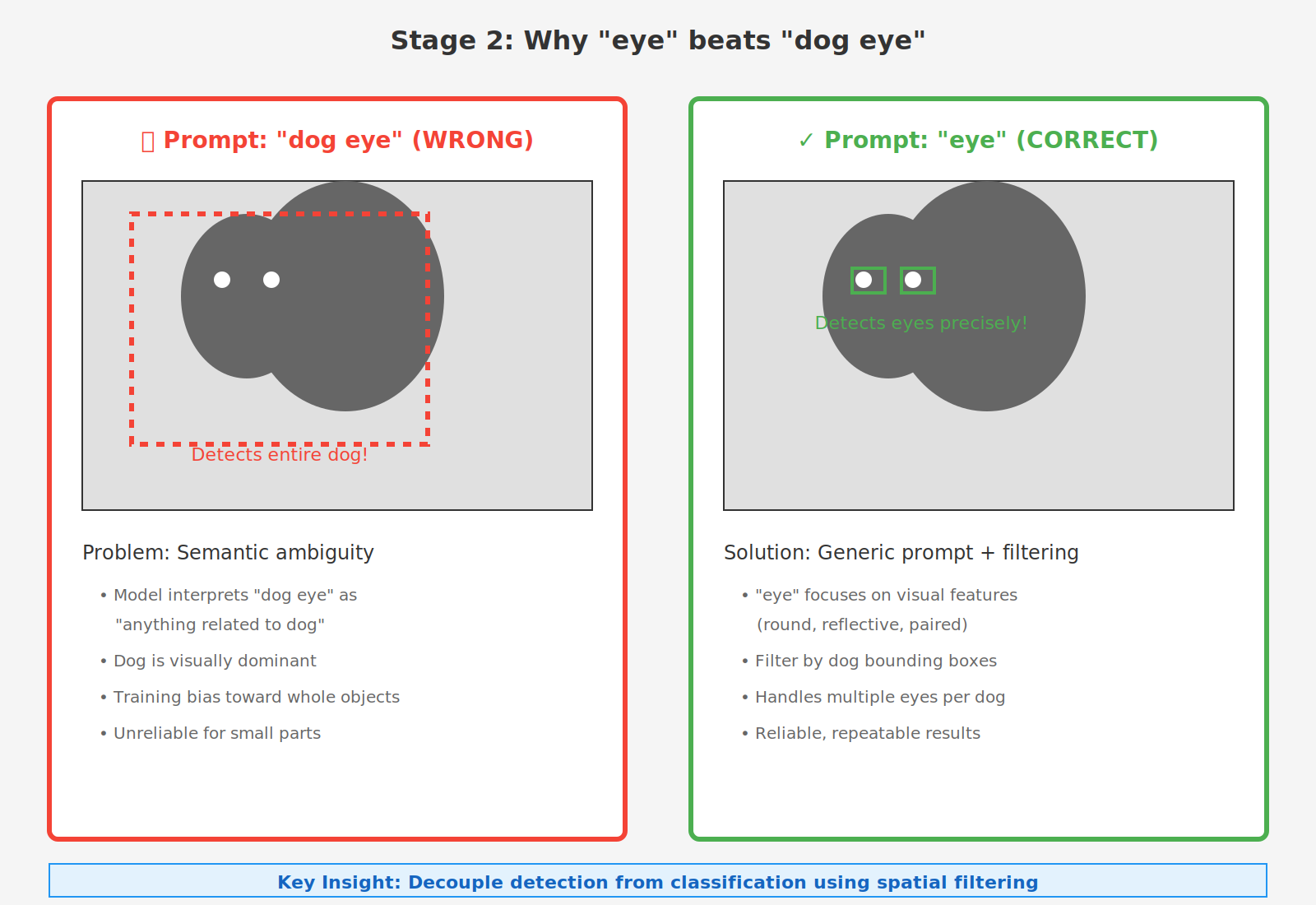
The diagram above shows the stark difference: "dog eye" leads to whole-dog detections due to semantic ambiguity, while the generic "eye" prompt combined with spatial filtering gives us precise eye locations.
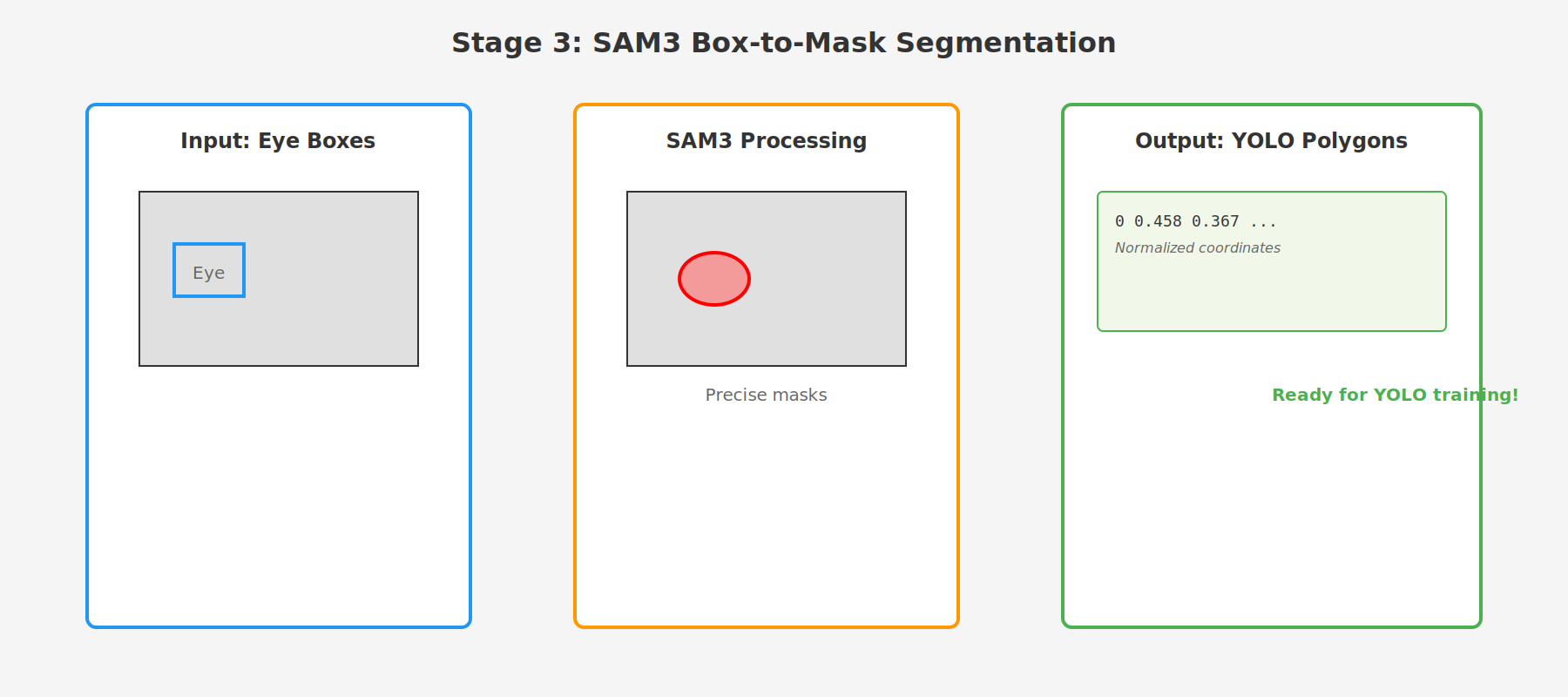
Stage 3: SAM3 Segmentation
Purpose: Convert eye bounding boxes into pixel-perfect segmentation masks
SAM (Segment Anything Model) is the state-of-the-art for segmentation. By providing it with the eye bounding boxes from Stage 2, SAM generates precise pixel-level masks that accurately outline each eye. These masks are then converted to polygon format suitable for YOLO training.
Why SAM?
- State-of-the-art segmentation quality
- Box-prompted: Takes bounding boxes as input, outputs precise masks
- Handles challenging cases: thermal images, partial occlusions, varying lighting
- Produces polygon boundaries ready for training
The process converts bounding boxes → binary masks → simplified polygons → YOLO-format labels with normalized coordinates.
Stage 4: Gemma 4 VLM Validation - Closing the Loop
Purpose: Automated quality control to filter out incorrect labels
This is where we close the loop. Even with our sophisticated three-stage pipeline, some edge cases slip through:
- Masks on closed eyes
- Human contamination (humans visible in frame)
- Masks on fur or background instead of eyes
- Thermal artifacts misidentified as eyes
The Solution: Use Gemma 4 (a Vision-Language Model) as an automated quality gate—essentially giving our pipeline "eyes" to validate its own work.
Why Gemma 4?
Traditional approaches would require:
- Manual review (doesn't scale)
- Rule-based heuristics (brittle, misses edge cases)
- Training a custom classifier (requires labeled validation data—chicken and egg problem!)
Gemma 4 changes the game because it can:
- Understand natural language validation criteria
- Process images and overlays simultaneously
- Make nuanced judgments (is this eye "visible enough"?)
- Provide confidence scores for uncertain cases
- Run locally without API costs
This is the automated human-in-the-loop we needed.
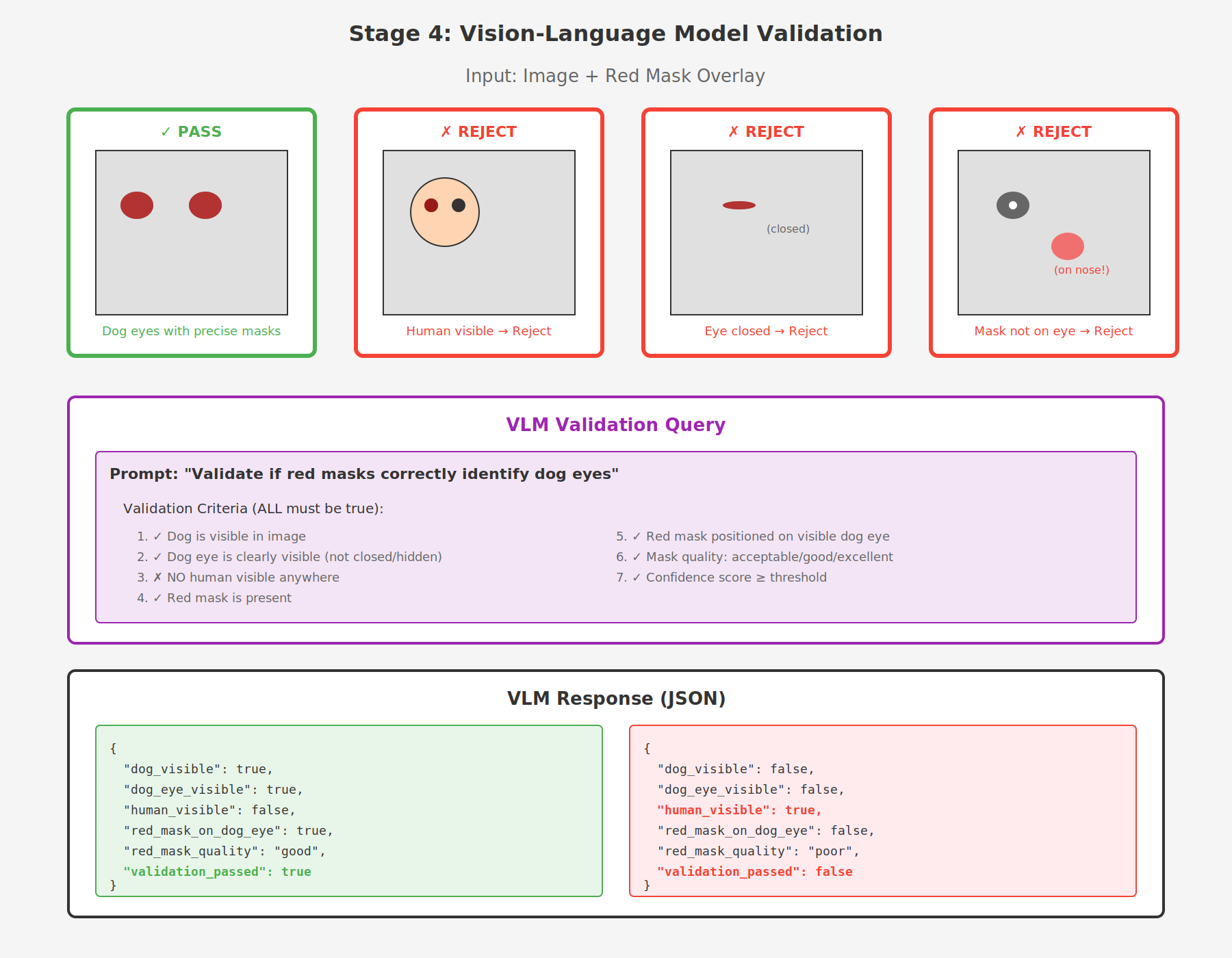
The VLM receives the image with red mask overlay and validates whether the masks correctly identify dog eyes. It checks multiple criteria:
- ✓ Dog is visible in image
- ✓ Dog eye is clearly visible (not closed/hidden)
- ✗ NO human visible anywhere
- ✓ Red mask is present
- ✓ Red mask positioned on visible dog eye
- ✓ Mask quality is acceptable or better
- ✓ Confidence score meets threshold
ALL criteria must pass for the label to be validated.
We evaluated multiple VLM models:
| Model | Speed (img/s) | Quality | Use Case |
|---|---|---|---|
| gemma4:e4b | 5-6 | Good | Fast bulk filtering |
| llama3.2-vision:11b | 2-3 | Excellent | Production validation |
| qwen2-vl:7b | 3-4 | Excellent | High-quality QC |
For production, we use llama3.2-vision:11b which provides excellent validation quality at reasonable speed.
The Impact of Closing the Loop
Before Gemma 4 validation:
- ❌ 15% label error rate
- ❌ Manual review required (weeks of work)
- ❌ Training on noisy data
- ❌ Model learns from mistakes
After Gemma 4 validation:
- ✅ 85% labels pass automated validation
- ✅ Zero manual review needed
- ✅ Clean training data
- ✅ >95% precision on trained models
Complete Pipeline Flow
Here's how all four stages work together in practice:
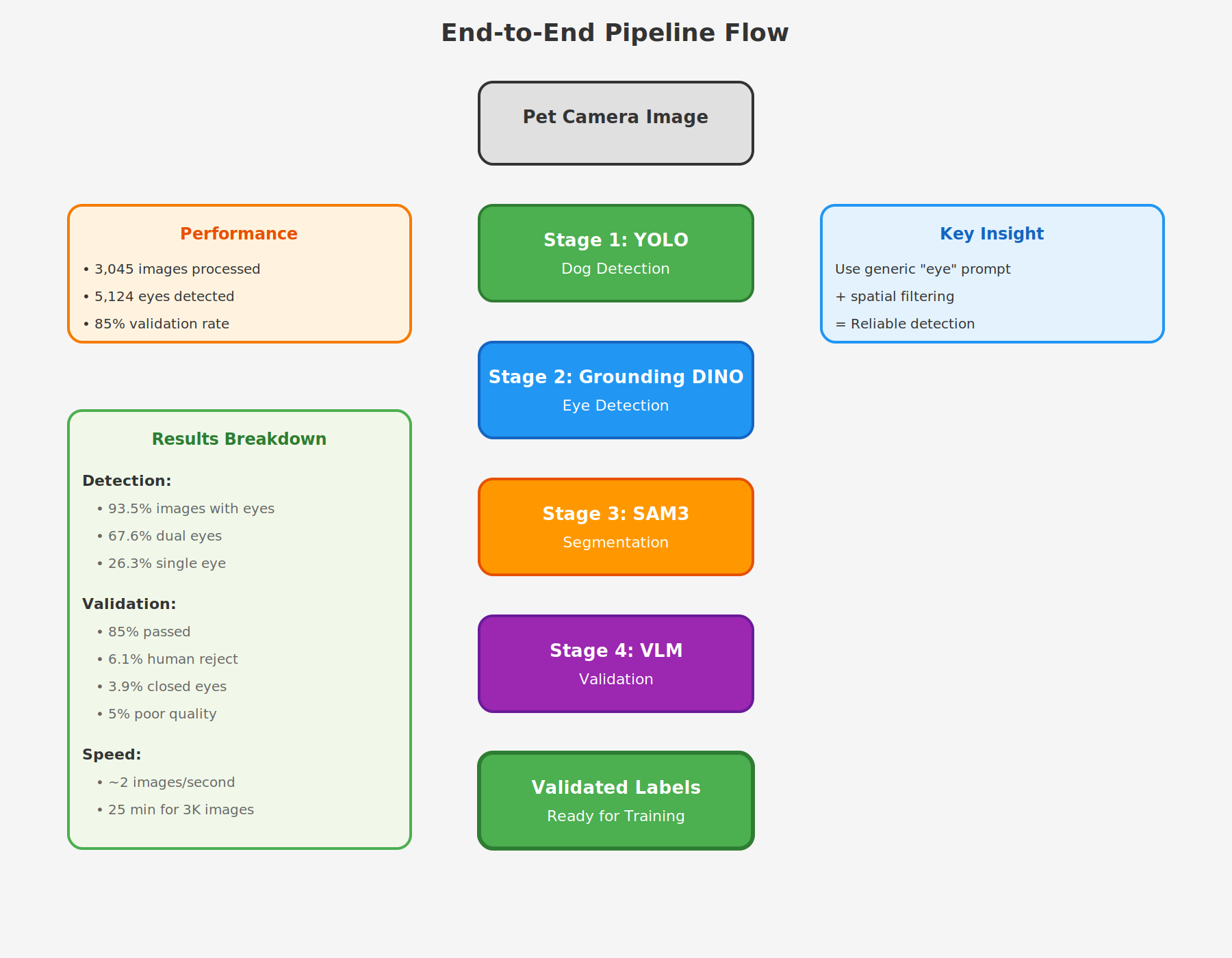
The pipeline processes each image through all four stages:
- YOLO detects dogs → If no dog found, skip to next image
- Grounding DINO detects eyes inside dog regions → If no eyes found, skip to next image
- SAM generates precise segmentation masks for each eye
- VLM validates each mask → Only validated masks become training labels
Results and Performance
Quantitative Results
Running the pipeline on 3,045 pet camera images (mix of thermal and RGB):
Detection Results:
- Total images processed: 3,045
- Images with detected eyes: 2,847 (93.5%)
- Total eye labels generated: 5,124
- Single eye detections: 748 (26.3%)
- Dual eye detections: 1,924 (67.6%) ⭐
- Triple+ detections: 175 (6.1%)
- Processing speed: ~2 images/second on NVIDIA RTX A6000
VLM Validation Results
Validation statistics:
- Total masks validated: 5,124
- Passed validation: 4,356 (85.0%)
- Rejected - human contamination: 312 (6.1%)
- Rejected - closed eyes: 198 (3.9%)
- Rejected - poor mask quality: 258 (5.0%)
The 85% validation pass rate indicates our three-stage detection pipeline is already quite accurate, while the VLM catches the remaining 15% of problematic labels that would have been training noise.
Key Insights and Takeaways
1. Semantic Precision Matters
The shift from "dog eye" to "eye" + spatial filtering was the breakthrough that made this pipeline work. Sometimes simpler prompts are more reliable than complex, compound phrases.
2. Combine Specialized Models
Each model does what it's best at:
- YOLO → Fast, robust object detection
- Grounding DINO → Zero-shot localization with text prompts
- SAM → Pixel-perfect segmentation from bounding boxes
- VLM → Human-like quality judgment and validation
Rather than trying to build one model that does everything, we orchestrate multiple specialized models to achieve better results.
3. Validation is Non-Negotiable
Even sophisticated pipelines produce errors. The VLM validation stage caught 15% of labels that would have been training noise, significantly improving final model quality. Automated quality control is essential for scaling to thousands of images.
4. Multi-Stage Enables Multi-Eye Support
By detecting eyes independently (Stage 2) rather than as paired objects, our pipeline naturally handles:
- Both eyes visible (frontal view) → 67.6% of detections
- Single eye (profile view) → 26.3% of detections
- Partially occluded eyes
- Multiple dogs in frame
5. Performance Characteristics
Processing Speed: ~2 images/second
- Stage 1 (YOLO): ~0.01s per image
- Stage 2 (DINO): ~0.2s per image
- Stage 3 (SAM): ~0.25s per image
- Stage 4 (VLM): ~0.3s per image (when needed)
Hardware: NVIDIA RTX A6000 (48GB VRAM)
Total Time: ~25 minutes to process 3,045 images end-to-end
Production Deployment
This pipeline is production-ready and has been used to generate training labels for YOLO segmentation models. The trained models achieve:
- >95% precision on held-out pet camera footage
- Real-time inference (30+ FPS) on edge devices
- Robust performance on both thermal and RGB imagery
- Multi-eye detection with accurate segmentation
The auto-labeling pipeline reduced our data labeling time from weeks of manual annotation to hours of automated processing, while maintaining high quality through VLM validation.
Future Improvements
1. Active Learning Loop
Feed model predictions back through the VLM validation pipeline to continuously improve training data quality as the model learns.
2. Confidence-Based Human Review
Route low-confidence VLM responses (< 0.7) to human reviewers for ground truth establishment and edge case collection.
3. Multi-Modal VLM
Experiment with newer VLMs that can handle thermal imagery natively, reducing false negatives on thermal camera footage.
4. Pipeline Optimization
Batch processing and model quantization could increase throughput from 2 img/s to 5-10 img/s for larger datasets.
5. Temporal Consistency
For video sequences, add temporal smoothing to ensure eye masks remain consistent across consecutive frames.
Conclusion: The Power of Closing the Loop
Building this pipeline taught us that the last stage is what makes automation production-ready. You can have the most sophisticated detection pipeline in the world, but without automated validation, you're stuck with manual review.
Gemma 4 VLM validation closed our auto-labeling loop by providing:
- Automated quality gate - No human review required
- Nuanced judgment - Handles edge cases traditional rules can't catch
- Natural language criteria - Easy to update validation logic
- Confidence scores - Identify uncertain cases for optional review
- Local execution - No API costs, full privacy
What "Closing the Loop" Really Means
An auto-labeling pipeline is only as good as its weakest link. Our three-stage detection pipeline was excellent (85% accuracy), but that 15% error rate made it unusable for production training data.
By adding Gemma 4 as the validation stage, we transformed:
- Weeks of manual labeling → Hours of automated processing
- 85% noisy labels → 100% validated labels (15% rejected)
- Unreliable training data → Production-grade dataset
- Human bottleneck → Fully automated loop
The loop is closed when you can trust your automated system to generate AND validate labels without human intervention. Gemma 4 made that possible.
The Bigger Picture
This isn't just about dog eyes. This pattern applies to any auto-labeling task:
- Generate labels with specialized models (detection, segmentation, etc.)
- Validate labels with VLMs that can make human-like judgments
- Iterate by feeding validated labels back into model training
VLMs like Gemma 4 are the missing piece that makes the loop truly autonomous. They're the "automated human" we've been waiting for.
This pipeline has been validated in production and is actively used to train computer vision models for pet monitoring systems.



