Continual YOLO Training on the Edge


Introduction
Most computer vision models begin with a clean, carefully curated dataset. But real-world systems rarely stay that way. They evolve. New environments appear, edge cases emerge, and model failures surface in ways that the original training data could never fully capture. This is especially true when deploying lightweight models like YOLO Nano (YOLOv8n) on edge devices.
At Hoomanely, we faced this head‑on while building reliable dog eye segmentation for our pet‑health sensing stack. A model that worked well in the lab would occasionally fail in a dim living room, or mis-segment an eye when a dog looked sideways. Instead of rebuilding a dataset from scratch each time, we designed a workflow where the model continually retrains on real errors - right on the edge or in small increments.
This post breaks down how incremental training works, why it matters, and how you can implement the same idea for any YOLO-based edge deployment.
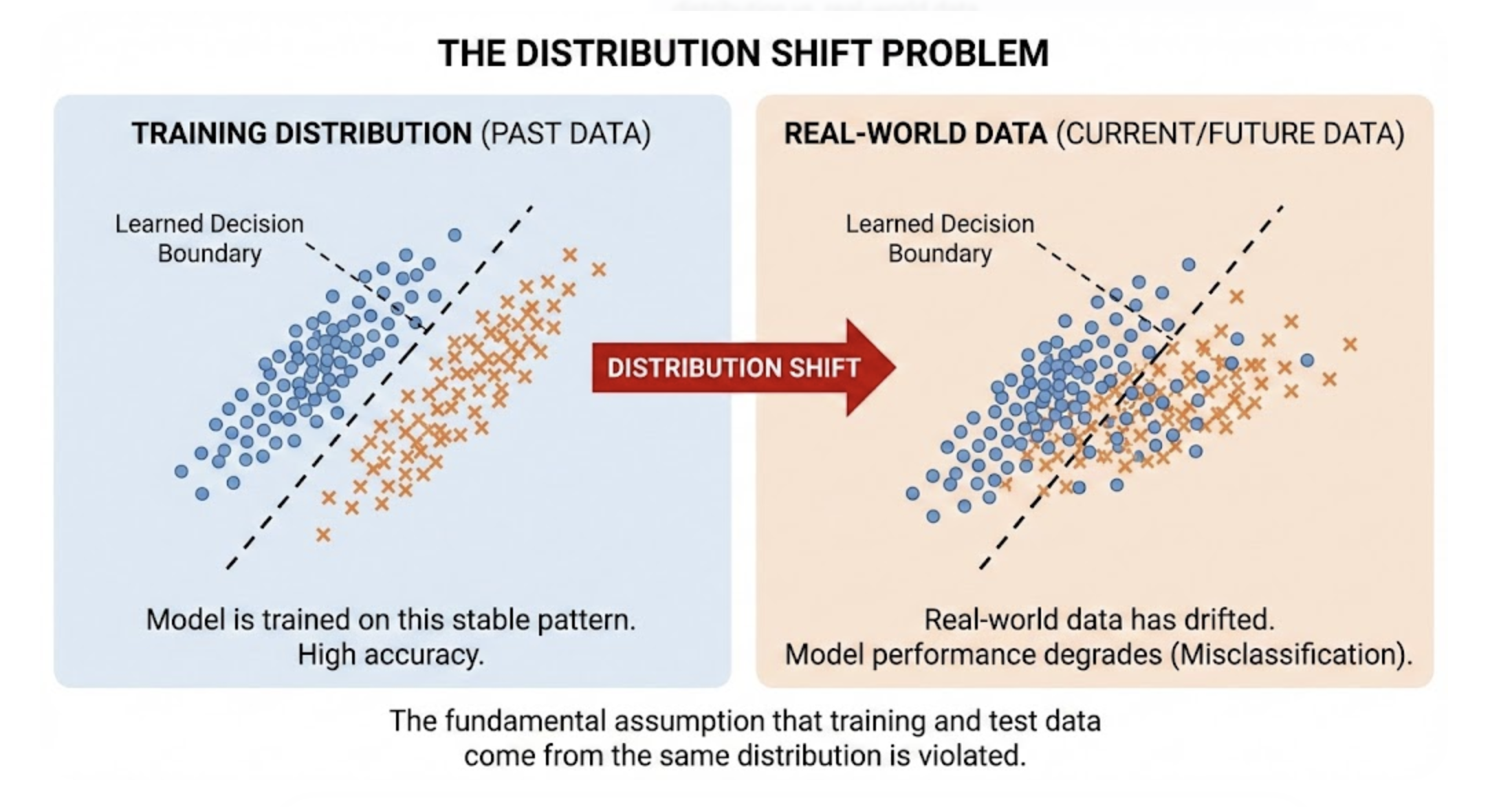
Problem: Static Models Don’t Survive Dynamic Environments
Edge vision models often struggle with:
- New lighting conditions (indoor lamps, sunlight streaks, reflective bowls)
- Individual differences (dog breeds, fur texture, eye shape)
- Camera placement variance between homes
- Rare edge cases that never appear in the original dataset
A one‑time training run can only capture a fraction of the real world. Over time, this leads to:
- False positives (predicting an eye where none exists)
- False negatives (missing the eye entirely)
- Unstable segmentation quality
These errors matter, especially when downstream systems - temperature estimation, anomaly detection, or health scoring - depend on reliable segmentation.
Why Continual Training Matters
Instead of treating the dataset as a static asset, we treat it as a living organism. Every new deployment environment generates:
- new photos,
- new edge cases,
- corrected annotations from human reviewers,
- and logs of model failures.
Using these, we can incrementally update the same YOLO Nano model:
- without losing previously learned knowledge,
- without re-training from scratch,
- and without needing huge GPUs.
This is particularly important for Hoomanely, where dogs vary wildly in appearance and behavior, and owners place the bowl in very different environments. Our ability to absorb real-world errors and improve continually is a core part of building reliable pet health systems.
Approach: Incremental Fine‑Tuning on Top of Learned Weights
Incremental training begins after the initial custom model is trained.
Step 1: Start from a Pretrained YOLO Model
Most teams start with YOLOv8n-seg.pt (segmentation variant). It’s lightweight, edge-friendly, and accurate enough for structured features like dog eyes.
Step 2: Fine-Tune Once on Your Custom Dataset
This creates your v1 model. Example:
from ultralytics import YOLO
model = YOLO("yolov8n-seg.pt")
model.train(data="dog_eye.yaml", epochs=40, imgsz=640)
This becomes your foundation.
Step 3: Collect Real-World False Positives and False Negatives
Every time the model misbehaves:
- capture the frame,
- annotate the correct segmentation,
- store it.
Over time, this dataset becomes far more valuable than the clean original dataset.
Step 4: Retrain the Model Using the Previous Weights + New Data
This creates your v2, v3, v4… generations.
model = YOLO("weights/v1/best.pt")
model.train(data="dog_eye.yaml", epochs=15, imgsz=640)
We keep training on old + new data combined to avoid catastrophic forgetting.
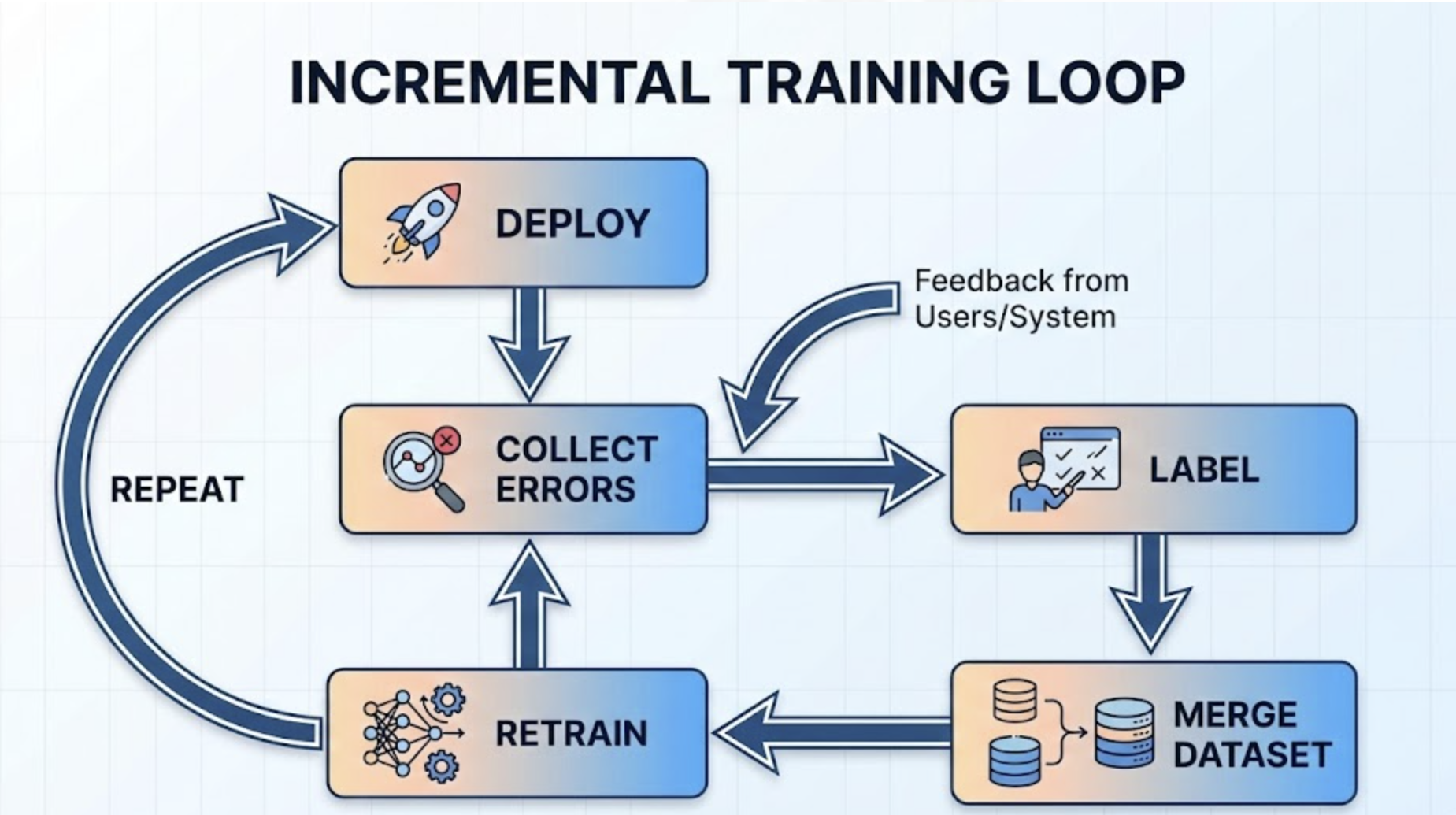
Process: Making Incremental YOLO Training Work Smoothly
Here’s a structured, engineering-friendly version you can adopt:
1. Maintain a Versioned Dataset
Example folder structure:
dataset/
images/
train/
val/
new_data_round_1/
new_data_round_2/
labels/
New rounds are periodically merged.
2. Build a Failures Pipeline
Your pipeline should auto-save:
- frames with poor segmentation masks
- low-confidence detections
- unexpected bounding boxes
These become training gold.
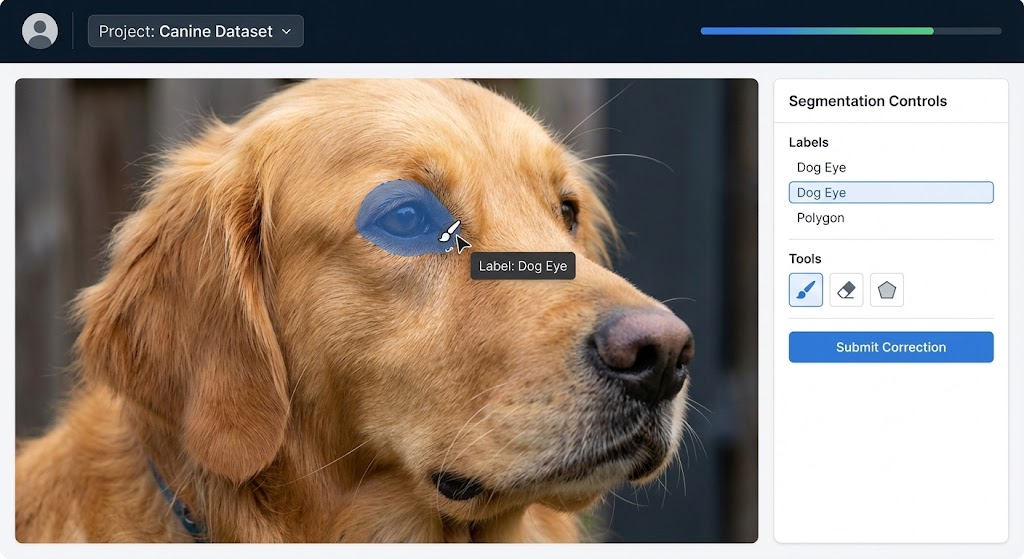
3. Add Human-in-the-Loop Review
A lightweight web UI or annotation tool ensures the corrected labels are consistently high-quality.
4. Retrain Using Prior Model Weights
This maintains continuity and preserves learned knowledge.
5. Validate Against a Fixed Validation Set
Never change the validation set when adding new training data - otherwise you lose the ability to measure progress.
Results: How Much Does Incremental Training Help?
In our internal testing at Hoomanely, continual fine‑tuning improved metrics even with small batches (~50–150 new images per round):
- mAP improved by 3–7 points per cycle in earlier rounds
- False positives reduced dramatically for indoor low-light scenes
- Segmentation stability improved across dog breeds
- Model size remained small (YOLO Nano remains <4–5 MB)
More importantly, accuracy improved exactly where it mattered: in real homes under real lighting with real pets.
This is the kind of tight feedback loop that production CV systems need but rarely implement early.
How It Works on the Edge
YOLO Nano is light enough to retrain on devices like:
- Raspberry Pi CM4
- Jetson Nano/Xavier NX
But due to memory constraints, we typically:
- Offload indexing and annotation to the cloud
- Train on a lightweight GPU backend
- Then push updated weights back to the device
For teams wanting true on-edge continual learning (no cloud), YOLO supports:
- batch=1 or batch=2
- reduced image sizes (512 or even 384)
- mixed precision where available
The workflow remains the same.
How This Helped Us
Our vision is to bring precision pet health monitoring into every home. Accurate sensing - whether audio, thermal, or vision - is the foundation.
Continual YOLO training helps us:
- adapt our models to thousands of different homes,
- learn from every correction,
- build pet-specific understanding instead of one-size-fits-all logic,
- and maintain reliability as the product scales.
It’s a quiet but decisive step toward building the world’s most intelligent pet health companion.
Key Takeaways
- YOLO models can be retrained incrementally - and should be, for real deployments.
- New data from real-world errors is more valuable than synthetic or curated training sets.
- Always retrain from previous weights to preserve knowledge.
- Mix old + new datasets to avoid catastrophic forgetting.
- Maintain a fixed validation set to measure improvements.
- Build a smooth fail-detection → annotation → retraining loop.
Continual training turns your CV pipeline from a static asset into a self-improving system.



