Field Data Poisoning Defense for ML Pipelines

Machine learning systems increasingly rely on data generated by devices operating in the real world - cameras capturing environments, sensors streaming telemetry, microphones collecting audio, and applications logging user interactions. These signals provide invaluable training data because they reflect the true conditions under which models must perform.
However, the moment a training pipeline begins ingesting field-generated data, a new security risk appears: data poisoning.
Unlike curated datasets collected under controlled conditions, field data arrives from thousands of distributed sources with varying levels of reliability. Devices may malfunction, sensors may drift, networks may replay stale packets, and in rare cases adversaries may attempt to influence model behavior through carefully crafted inputs. These manipulations rarely appear as obvious failures. Instead, they subtly alter the dataset distribution, allowing poisoned samples to quietly influence model training.
A compromised device might repeatedly upload a rare pattern associated with a particular label. A misconfigured sensor may generate extreme values that skew feature distributions. Over time, these signals can shape model decision boundaries in unexpected ways.
Preventing this requires a fundamental architectural change: device-collected data must be treated as untrusted input until proven otherwise.
This article presents a production-ready defense architecture for ML systems that rely on field-generated datasets. The approach combines three complementary layers:
- Quarantine-first data ingestion
- Sentinel holdout datasets
- Backdoor and trigger-pattern detection
Together, these mechanisms ensure that only validated, traceable data enters training pipelines while maintaining the scalability required for continuous device data ingestion.
The Unique Risks of Field-Collected Training Data
Field datasets differ fundamentally from traditional curated datasets. In most ML workflows, datasets originate from controlled labeling environments or research repositories where data provenance is clear.
In contrast, field-generated datasets are continuous, distributed, and partially observable.
A single training corpus may aggregate signals from:
- thousands of device installations
- multiple firmware versions
- diverse geographic environments
- varying sensor calibration states
This heterogeneity is valuable because it improves model robustness. But it also creates opportunities for hidden anomalies and adversarial patterns to propagate unnoticed.
Several common poisoning vectors appear in real-world pipelines:
Compromised devices
A device with modified firmware may intentionally generate manipulated signals that bias model training.
Automated scripted behavior
Bots or automated test environments can produce large volumes of repeated data patterns.
Label drift in semi-automated annotation
If labeling pipelines rely on heuristics or automated classifiers, incorrect labels may propagate through the dataset.
Trigger pattern injection
Small patterns intentionally correlated with labels can cause backdoor behaviors.
Environmental distribution shifts
Unexpected sensor behavior may mimic poisoning patterns.
The danger lies in how these signals accumulate gradually. A small number of poisoned samples can influence training outcomes without producing obvious anomalies. The defense strategy must therefore operate throughout the data lifecycle, not only during training.
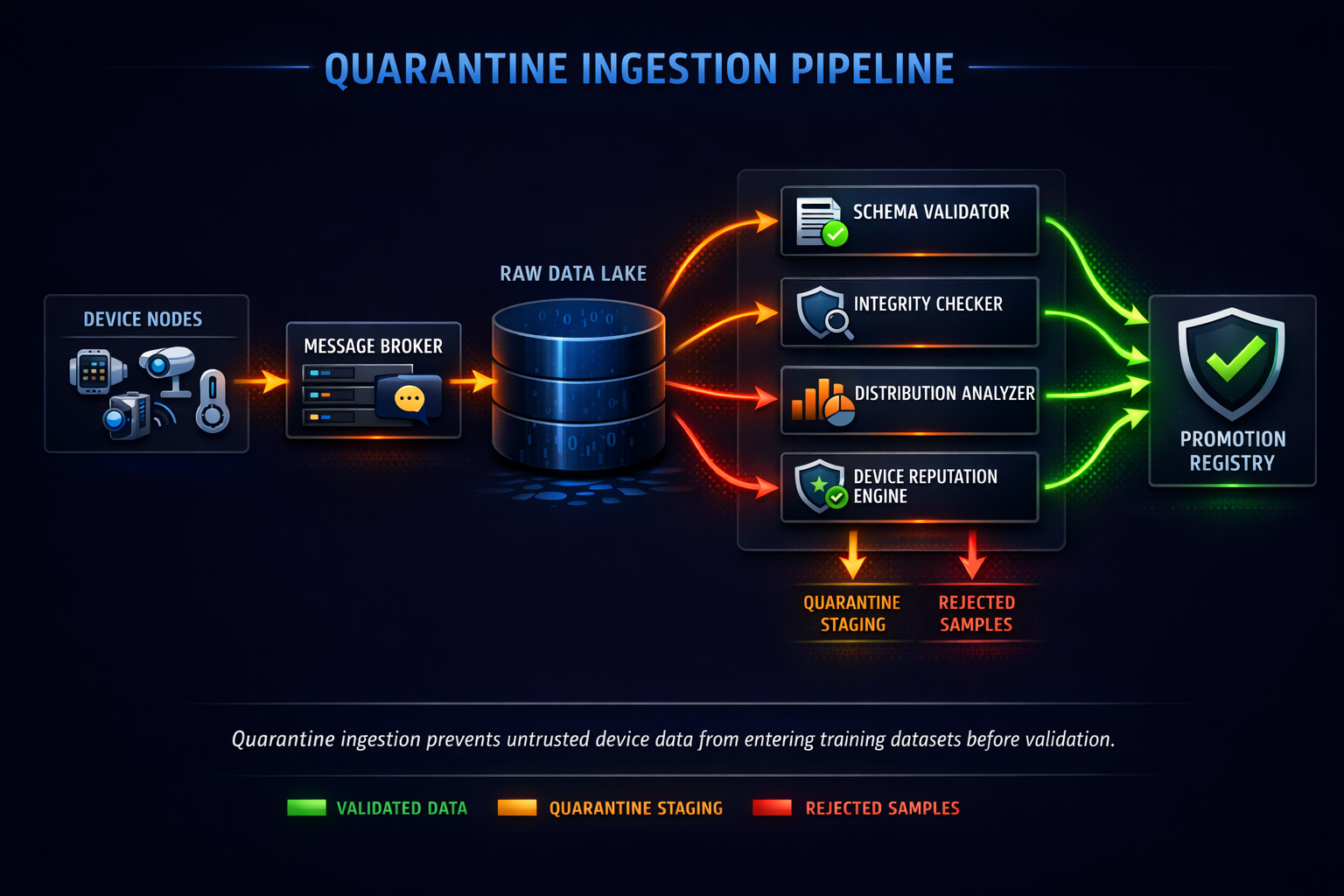
Quarantine-First Data Ingestion
The first line of defense is data quarantine. Instead of allowing field data to flow directly into training datasets, the pipeline introduces an intermediate staging environment where new data is treated as untrusted until validated.
Conceptually, the quarantine layer behaves like a security gateway for ML data pipelines. Incoming samples pass through a sequence of validation stages before being eligible for promotion into training datasets.
A typical architecture includes the following components:
- Raw ingestion storage
Object storage or streaming logs capturing device uploads. - Validation workers
Stateless jobs that evaluate structural and statistical properties. - Anomaly scoring service
Computes risk scores for samples or devices. - Promotion registry
Tracks which data has passed validation gates.
Practical Implementation
In production pipelines, quarantine layers are typically implemented with distributed processing frameworks.
Device Streams
↓
Message Broker (Kafka / Kinesis)
↓
Raw Object Storage (S3 / GCS)
↓
Validation Workers (Spark / Flink / Ray)
↓
Quarantine Dataset Store
↓
Promotion Gate
↓
Training Dataset Registry
Validation workers perform several checks before promoting data.
These include:
- schema validation
- payload integrity checks
- metadata verification
- statistical anomaly detection
If any validation fails, the sample remains in quarantine and is flagged for review.
Admission Criteria for Training Data
Quarantine pipelines require explicit admission criteria that define when data is considered safe for training. These criteria should combine structural validation, statistical checks, and provenance guarantees.
Structural Validation
Structural validation ensures that incoming data conforms to expected formats and metadata schemas.
Typical checks include:
- required fields present
- valid device identifiers
- timestamp monotonicity
- payload size limits
- correct sensor encoding
While simple, these checks prevent malformed or corrupted samples from entering downstream pipelines.
Distribution Sanity Checks
Statistical validation ensures the dataset remains consistent with historical distributions. For example, consider a sensor producing temperature readings. A sudden spike in extreme values may indicate:
- sensor malfunction
- firmware error
- adversarial input
Distribution monitoring often tracks metrics such as:
- mean and variance per feature
- histogram divergence from baseline
- rare feature frequency
Engineers typically compute divergence metrics such as KL divergence or Wasserstein distance between new data and baseline distributions.
Example monitoring pipeline:
baseline = historical_feature_distribution
current = incoming_batch_distribution
if KL_divergence(baseline, current) > threshold:
flag_anomaly()
Such checks catch subtle dataset drift early.
Provenance Tracking
Every data sample must be traceable to its origin. Provenance metadata typically includes:
- device identifier
- firmware version
- ingestion pipeline version
- preprocessing steps
- timestamp of capture
This information enables reproducibility and forensic analysis. Dataset lineage systems often store this metadata in dataset registries or experiment tracking systems.
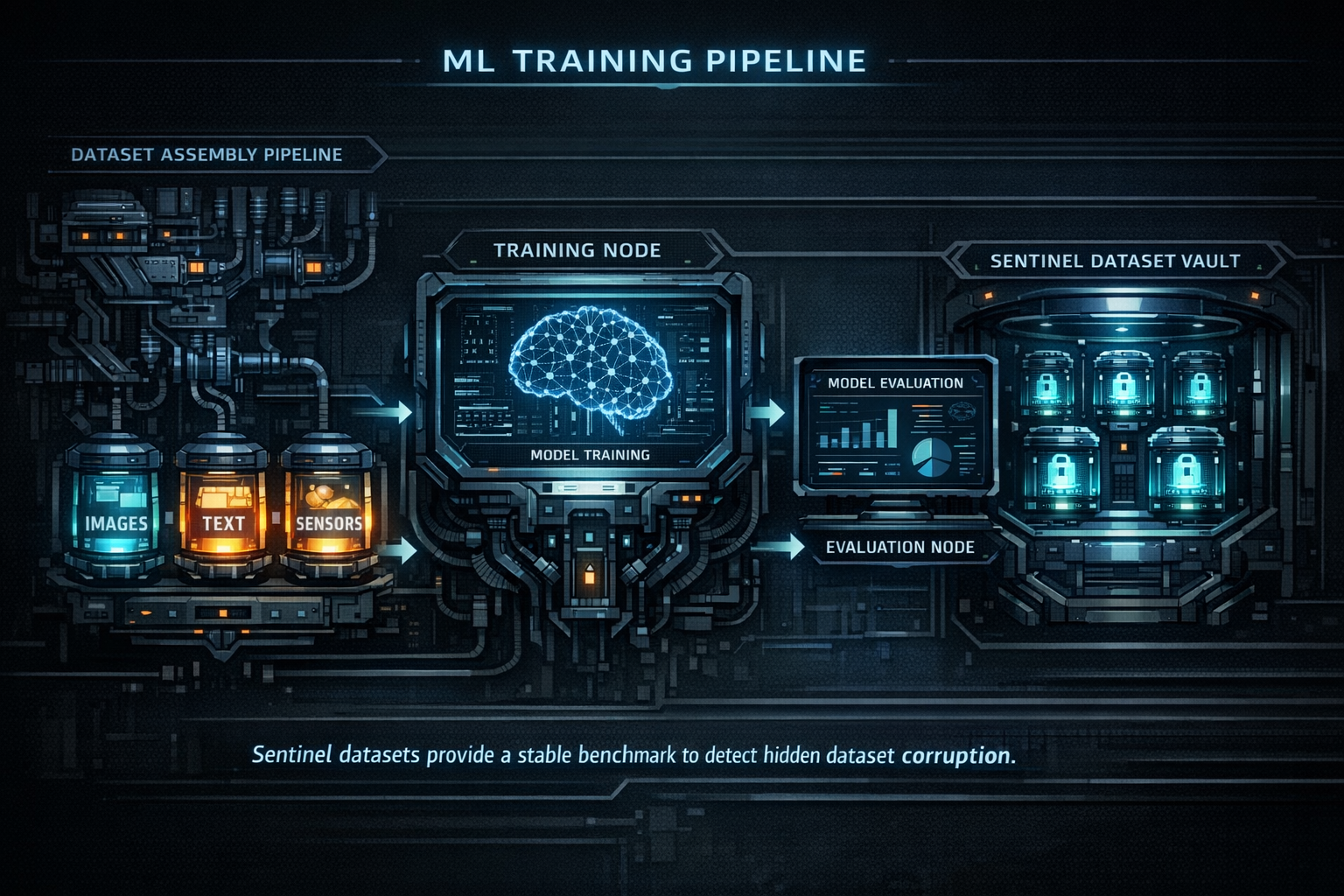
Sentinel Holdouts for Dataset Integrity
Even with strong ingestion checks, subtle poisoning patterns may still enter training datasets. To detect these issues, ML systems maintain sentinel holdout datasets. Sentinel datasets are clean, curated reference slices that remain isolated from new field data. They serve as stable benchmarks for evaluating model behavior. Unlike validation sets that evolve with training pipelines, sentinel datasets are frozen and versioned.
How Sentinel Holdouts Detect Poisoning
When a new dataset is assembled for training, the resulting model is evaluated against sentinel data.
Engineers track metrics such as:
- accuracy stability
- confidence distribution
- prediction entropy
- class-specific error rates
Unexpected regressions on sentinel data often indicate that the training dataset has introduced problematic patterns.
For example:
- accuracy remains stable on recent validation data
- accuracy drops significantly on sentinel holdouts
This pattern strongly suggests training dataset contamination.
Detecting Backdoor Triggers
One of the most dangerous poisoning strategies is backdoor injection.
In a backdoor attack, training data contains a hidden pattern correlated with a specific label. The model learns this shortcut and behaves incorrectly when the trigger appears.
Triggers may take many forms:
- specific pixel patterns
- rare audio tones
- sensor sequence combinations
- metadata signatures
Detecting these triggers requires deeper dataset analysis.
Rare Pattern Correlation Analysis
One effective technique is scanning for rare feature combinations strongly associated with labels.
Example approach:
- Extract features from training samples.
- Identify rare patterns appearing in few samples.
- Measure correlation between pattern presence and label.
Example pseudocode:
for pattern in rare_patterns:
correlation = compute_label_correlation(pattern)
if correlation > suspicious_threshold:
flag_trigger(pattern)
High correlation for rare patterns often indicates potential backdoor triggers.
Feature Attribution Monitoring
Another detection technique examines model feature attribution.
If a model heavily relies on small regions of input data, it may indicate trigger learning.
Common tools include:
- SHAP analysis
- integrated gradients
- saliency maps
These techniques highlight which features influence model predictions.
Unexpected high influence on rare patterns can signal backdoor risks.
Promotion Gates Before Training
Before data becomes part of the training dataset, it must pass promotion gates.
Promotion gates combine signals from multiple pipeline stages.
Typical promotion checks include:
- schema validation success
- anomaly score below threshold
- distribution drift within limits
- sentinel evaluation stable
- no trigger patterns detected
Only after passing these checks is the dataset registered as trainable.
This registry ensures training pipelines only consume validated datasets.
Observability for Data Integrity
A secure pipeline must also be observable. Engineers should continuously monitor signals indicating potential poisoning.
Examples include:
- sudden increases in anomaly scores
- device-level data spikes
- rare pattern frequency changes
- sentinel metric regressions
These signals should trigger alerts long before poisoned data reaches model training. Over time, observability dashboards help track dataset health trends.
In real-world systems such as Hoomanely’s connected device ecosystem, machine learning pipelines ingest signals from physical environments where pets interact naturally with sensors and cameras.
Because these signals originate outside controlled laboratory environments, the ingestion architecture must be resilient to unexpected inputs. Quarantine pipelines and sentinel evaluation layers ensure that field-collected signals improve model intelligence without introducing hidden biases or vulnerabilities.
This approach allows ML systems to scale alongside device deployments while maintaining data integrity and reproducibility.

Key Takeaways
Machine learning systems trained on device-collected datasets must assume that incoming data may contain anomalies, drift, or adversarial patterns. Building resilient pipelines requires multiple defense layers.
Key principles include:
- Treat field data as untrusted until validated
- Use quarantine ingestion pipelines
- Maintain sentinel holdout datasets
- Detect rare trigger correlations
- enforce promotion gates before training
- maintain dataset lineage and observability
With these guardrails in place, ML teams can safely leverage the power of real-world data while protecting models from hidden poisoning risks.