From Unstructured Documents to Actionable Records: Engineering Paw Vault

Pet healthcare records are unstructured by nature. Vaccination certificates arrive as photos taken at a clinic. Blood reports get shared as PDFs. Prescription records get forwarded through messaging apps. Over time, all of it ends up scattered across phones, inboxes, and folders, hard to search, track, or act on when it's actually needed.
At Hoomanely, the problem we wanted to solve was simple to state: how do we turn these disconnected documents into structured, searchable records while making sure important milestones, like vaccination renewals, never slip through? That led to Paw Vault, a document processing workflow that turns uploaded pet healthcare records into organized data and reminders that actually fire when they should.
The hard part was never document storage. It was building a workflow that could reliably handle inconsistent input, pull out meaningful information, and turn that information into future action. On the surface, the obvious solution is: upload a document, ask the user to fill out a form. In practice, that creates real friction. People usually upload these documents while multitasking, standing in a clinic, traveling, managing an appointment, and asking them to manually transcribe clinic names, vaccination dates, and expiry info adds effort and increases the odds they just give up partway through.
The problem breaks into three distinct engineering challenges: handling document uploads efficiently from mobile devices, extracting structured information from highly variable document formats, and turning that extracted information into reliable reminders. Each stage has its own reliability, performance, and UX considerations.
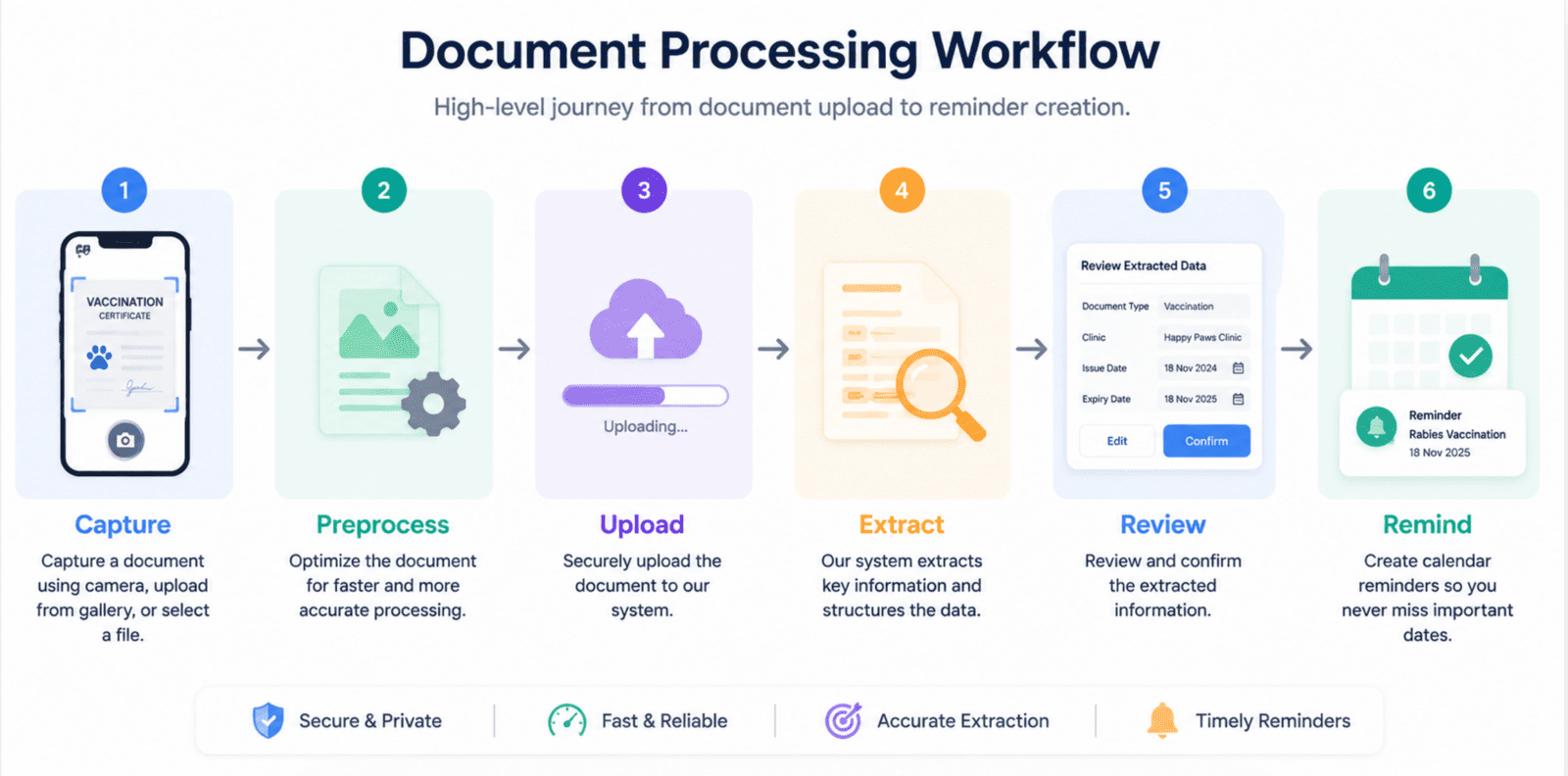
The overall flow runs: capture, preprocess, upload, extract, review, remind. A few principles guided the design throughout: cut manual data entry wherever possible, keep users in control of extracted information, optimize for mobile-first constraints, prefer recoverable failures over silent ones, and treat reminders as part of the document lifecycle rather than a bolted-on feature.
Processing documents efficiently
One of the first challenges was document size and format variability. Images from modern smartphones are often far larger than downstream processing actually needs, and uploading them directly costs bandwidth, processing time, and perceived latency. To handle that, image-based uploads get preprocessed before transmission, while PDFs get handled differently since aggressive transformation there could hurt quality or fidelity.
Responsiveness matters too. Image transformations are expensive enough to hurt the user experience if they run on the app's main thread, so preprocessing happens asynchronously, keeping upload progress and UI interactions smooth. Separating user interaction from processing work improves perceived performance meaningfully without changing what the app actually does.
Extracting structure from unstructured data
The core challenge in Paw Vault is turning unstructured healthcare documents into structured records. The extraction layer takes in a document and produces a compact set of fields that can drive search, filtering, categorization, and reminders. Rather than treating extraction as a transcription problem, the system treats it as data normalization: the goal isn't reproducing every word in the document, it's identifying the information users actually care about, document category, document title, issuing clinic, issue date, expiry date, and a short summary.
That distinction matters because users rarely search for entire documents. They search for specific pieces of information contained inside them.
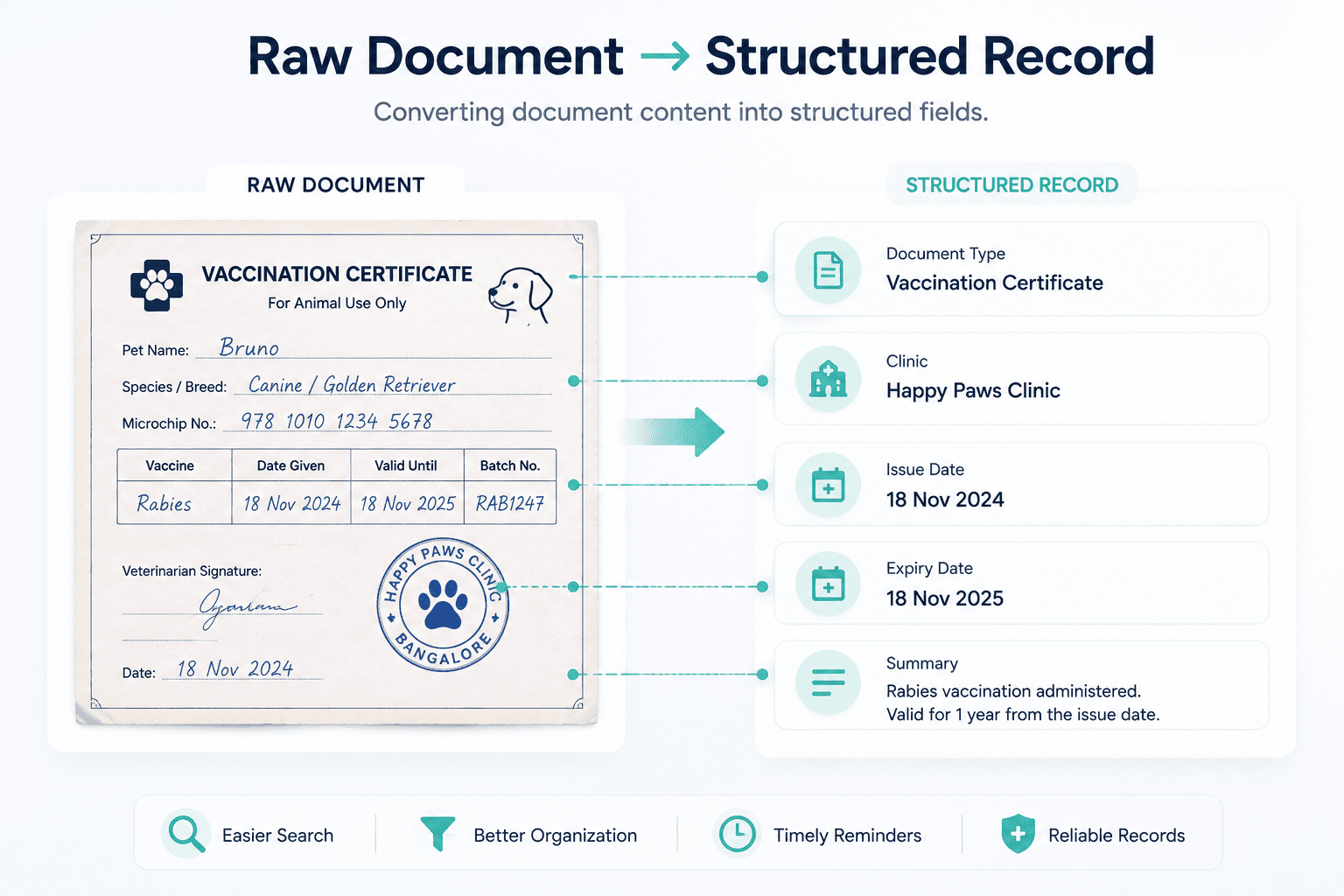
Designing for imperfect extraction
Document-processing systems rarely operate under ideal conditions. Documents show up with poor lighting, skewed framing, handwritten notes, mixed languages, missing sections, or low-quality scans, so extraction accuracy should never be treated as a given.
One of the more important design calls in Paw Vault was treating extracted data as a draft rather than a final answer. After extraction, users land on a review screen where every field stays editable. That gives two advantages: it cuts manual effort substantially when extraction works well, and it gives a graceful path to fix things when extraction is incomplete or partly wrong. Instead of forcing a restart, the system lets people make quick corrections before finalizing the document, and that balance between automation and user control has worked out better than either a fully automated or fully manual approach.
Building reliable reminder automation
A stored document only creates value if it leads to action. For vaccination records specifically, the expiry date often matters more than the document itself, and missing a booster appointment can create real complications for pet owners. So Paw Vault automatically creates reminder events once a user confirms the extracted expiry information.
Creating reminders sounds simple, but production throws up several edge cases: multiple calendars on one device, documents that are already expired, updated expiry dates, changed account configurations, and permission restrictions. So the reminder workflow focuses on consistency rather than just firing off events. When document information changes, reminders get updated rather than duplicated. Expired reminders get avoided entirely. Reminder schedules adjust to however much validity window is left on the document. The result behaves predictably across real-world usage instead of just working in the demo case.

Reliability considerations
A theme that runs through all of Paw Vault is graceful degradation. Most failures here are partial, not total: an upload succeeds but extraction is incomplete, extraction succeeds but a date needs verification, reminder creation succeeds but the user's permissions change later. Instead of treating these as failures outright, the workflow is built to recover from them, with every stage producing an outcome that can be reviewed, corrected, retried, or updated without forcing someone to start over from scratch. That approach improves reliability while cutting down on user frustration.
Results
The finished workflow delivers three things from a single uploaded document: a searchable digital record, structured metadata for filtering and categorization, and automated reminders tied to the document's actual validity window. More importantly, it minimizes manual input while keeping the user in control of the final record. The result feels simple from the user's side despite handling several stages of processing behind the scenes.
Connection to Hoomanely's mission
Hoomanely's broader goal is reducing the mental load that comes with pet care. A lot of pet-care problems are really information-management problems at heart: remembering vaccinations, tracking reports, managing prescriptions, planning renewals. Paw Vault contributes to that by turning static documents into structured information that can drive future action, so instead of asking pet parents to remember more, the system remembers on their behalf.
Key takeaways
- Unstructured documents become a lot more useful once they're converted into structured records.
- Mobile-first document workflows need real attention to bandwidth, responsiveness, and reliability.
- Extraction systems should assist users, not replace their verification.
- Reminder automation works best when it's built into the document lifecycle rather than added as a separate feature.
- Graceful recovery paths are often worth more than chasing perfect automation.
- Building a good document workflow means balancing accuracy, performance, and user experience together.