How We Built a Privacy-First LLM Backend: Enterprise Isolation, Bounded Memory & Zero-Content Logging

The Personalization vs Privacy Paradox in AI
Large language models power highly personalized experiences from conversational agents to contextaware recommendations. At Hoomanely, we use LLMs to help pet parents decode nuanced behavior, nutrition, and medical context for their pets. But this personalization requires context, which often includes sensitive user data like location, pet health history, and free-text input.
If we want the AI to say things like:
“Given your dog’s breed, weight, and current temperature in your city, watch out for dehydration,”
We must feed the model data that is inherently PII-rich.
This creates a fundamental trade-off:
Context increases usefulness but also raises privacy risks.
In this post, we explore how we architected a privacy first LLM backend using enterprise isolation, zero-content logging, and bounded memory without reducing the usefulness of the AI experience.
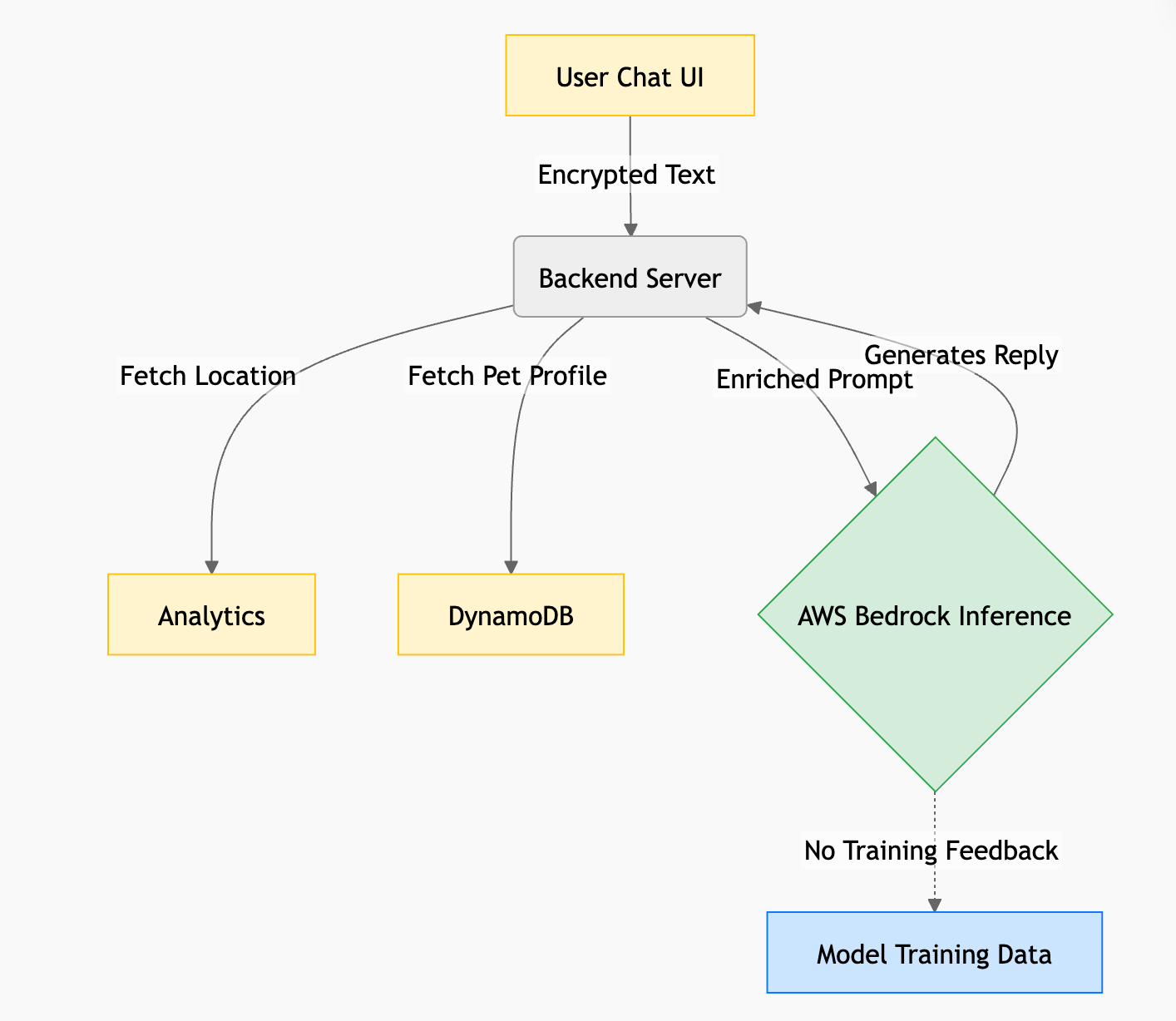
The Problem: LLM Context Enrichment Increases ExposureStateless LLMs produce generic, unhelpful responses. To fix that, our backend performs context enrichment before sending prompts to the inference provider. But that enrichment creates three privacy attack vectors:
Context Enrichment (Implicit Data)
We pull things like:
- GeoIP location data (e.g., city)
- Detailed pet medical history
- Behavioral metadata
These augment the prompt to give better personalization but they expand the amount of sensitive data sent to the model.
Free-Text Prompt Injection (Explicit Data):
Users type freely into chat boxes. They might include:
“My name is John Doe, phone number is 555-0199, and my dog ate chocolate.”
That raw PII ends up in our prompt builder unless explicitly blocked.
Conversational Memory (Persistent Context)
To maintain long-term continuity, we summarize past interactions into Level 1 and Level 2 summaries stored in DynamoDB. If the model erroneously treats PII as “important context,” it can end up in long-term memory and get sent in future prompts.
We needed an architecture that allowed rich personalization without turning the backend into a privacy liability.
The Approach: Enterprise Isolation, Zero-Content Logging, Bounded Memory
To mitigate these risks, we organize our design around three defensive pillars:
- Enterprise-Grade Inference Providers
- Zero-Content LLM Observability
- Strict Bounded Memory Windows
Enterprise-Grade Inference Providers
Why It Matters?
Instead of consumer LLM APIs, we chose enterprise inference via AWS Bedrock, hosting versions of Meta’s Llama 3.1 (8B, 11B, 17B variants).
Why? Enterprise cloud providers offer data processing guarantees that consumer APIs don’t:
Customer prompts and responses will NOT be used to train base foundation models.
This prevents your sensitive pet health data from being regurgitated in future public model updates.
Zero-Content LLM Observability
Logging is one of the most common privacy levers and one of the most dangerous.
If you log raw prompts like:
logger.info(f"Prompt: {prompt}")You’ve just deposited sensitive content into:
- CloudWatch
- Datadog
- ELK stacks
- Log archives
These logs persist for months and are accessible by many engineers.
Instead, we log only telemetry, never the actual text.
Example: Metrics-Only LLM Logging
def _log_llm_metrics(
self,
event_type: str,
input_tokens: int,
output_tokens: int,
latency_ms: float,
model_id: str,
prompt_type: str
):
"""
Log LLM metrics WITHOUT logging prompt or response.
Zero PII leakage into observability platforms.
"""
logging.info(json.dumps({
"event": "llm_inference",
"event_type": event_type,
"model_id": model_id,
"prompt_type": prompt_type,
"input_token_count": input_tokens,
"output_token_count": output_tokens,
"total_token_count": input_tokens + output_tokens,
"latency_ms": latency_ms,
"timestamp": time.time()
}))We capture:
- Token counts
- Latency
- Model ID
- Prompt type
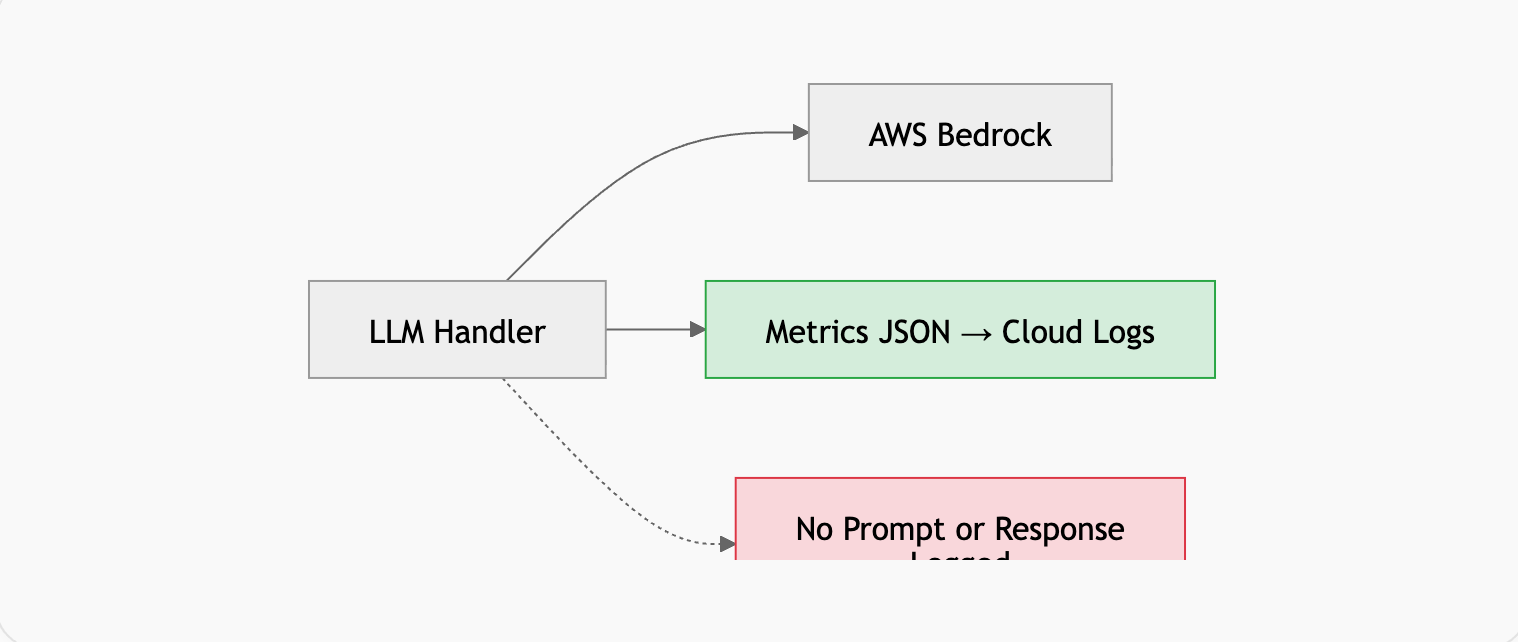
This gives us observability without ever storing PII in logs.
Bounded Memory Windows
Unbounded context increases both cost and privacy exposure.
To balance personalization with safety, we implemented:
- A rolling window of the last 9 conversational pairs sent to the LLM
- Two-level summaries (L1, L2) for older context
- Aggressive abstraction instead of verbatim history
This limits the raw PII that gets re-sent to the model.
Even if older chat contains explicit PII, it’s likely abstracted away or discarded.
However, LLMs are non-deterministic they might still inadvertently surface sensitive data in summaries. That’s unavoidable without an upstream PII scrubbing layer.
The Black Box: Where We Still Have Limitations
Even with these architectural defenses, three unavoidable realities remain:
Summarization Indeterminism
LLMs decide what’s “important” and might treat PII as relevant context unless a deterministic scrubber runs first.
Abuse Monitoring Retention
Enterprise providers may temporarily retain prompts for automated safety checks (e.g., 30 days), even if they’re not used for training.
Free Text Is Inherently Unpredictable
You can never perfectly filter every kind of PII with regex or NLP alone false positives and false negatives will occur.
This means design must contain risk rather than pretend to eliminate it.
Results: Privacy Without Sacrificing Personalization
After implementing these systems, we achieved:
- No internal PII leakage : raw prompts and replies never touch logs.
- Lower inference costs : bounded context reduces average token usage.
- Enterprise isolation : contractual protections against training data reuse.
- Developer insights : debugging performance without seeing sensitive text.



