Inference Modules as Plugins: Architecting Swappable AI Features Without Rewrites

Most teams add AI the same way they add any new feature: ship a model, wire an endpoint, move on. A few months later, you’re juggling three versions of the “scoring service”, five subtly different summarizers, and a bundle of feature flags nobody fully trusts. Changing one model feels risky; changing two at once feels impossible. There’s a better way,
Instead of treating “AI” as a monolithic service, you can treat each inference task as a plugin: a small, self-contained module with its own routes, lifecycle, config, and tests. Need to try a new behavior scorer? Drop in a new module, register it, point a feature flag at it, and roll back in seconds if needed—without touching the rest of your backend.
This post lays out a practical blueprint for building swappable inference modules that keep your core system stable while you iterate fast on AI-driven features.
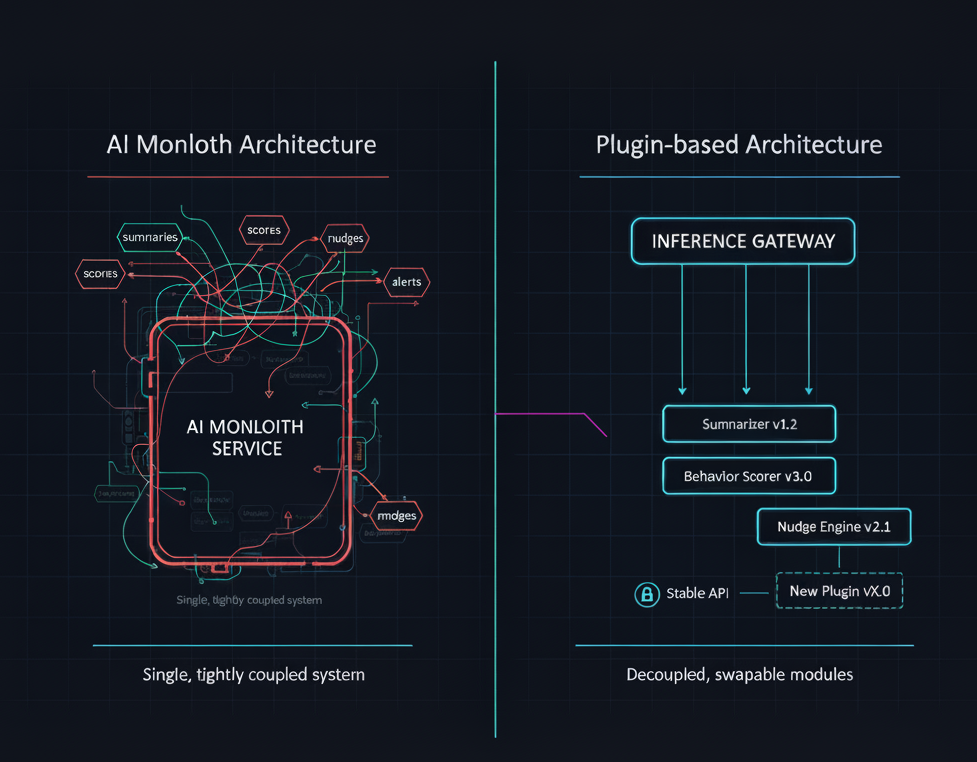
The Problem: Monolithic AI Services Don’t Scale
When teams first add AI to a system, the default pattern looks like this:
- One “model service” or
/inferenceendpoint. - Internal
if type == "summary"/if type == "score"branches. - Ad-hoc configs sprinkled across code, YAML, and dashboards.
- A few global clients (LLM SDK, vector store, feature store).
It’s fine for a prototype, but it falls apart as soon as you have:
- Multiple products sharing the same backend.
- Several AI tasks (summaries, rankings, nudges, anomaly detection, etc.).
- Multiple model versions per task.
- Regulatory or safety constraints that require auditability.
Typical failure modes:
- Tight coupling – Changing one task touches shared code used by others.
- Risky deployments – A new model for scoring breaks summarization because they shared a helper or client.
- No clean rollback – You can’t revert a single “task version”; you roll back the entire service.
- Weak test boundaries – It’s hard to test one inference behavior in isolation.
If your system uses signals from wearables, smart devices, or user-facing apps (like pet activity trackers or connected bowls), the risk compounds: one broken AI behavior can ripple through alerts, nudges, and dashboards.
What you want instead is task-level isolation: each inference capability behaves like a plugin that can be enabled, upgraded, or removed without surgery on the core service.
The Core Idea: Inference as a Plugin Contract
The key move is to define a contract for inference modules and treat every AI feature as an implementation of that contract.
Conceptually, a plugin is:
“A task-scoped module that owns its input/output schema, lifecycle, and configuration, and can be loaded, swapped, and torn down without changing the host service.”
Each plugin should be responsible for:
- Task contract
- e.g., “Given
session_events[], returnbehavior_score”. - Typed request/response schema.
- e.g., “Given
- Lifecycle hooks
load()for model weights / clients.warmup()for caches / JIT.teardown()for releasing resources.
- Routing identity
- A stable
task_name(e.g.,behavior_score) andversion(e.g.,3.1.0).
- A stable
- Config surface
- Hyperparameters, thresholds, prompt templates, safety settings.
- Tests
- Contract tests (schema, required fields).
- Golden tests (input → expected behavior).
- Basic load tests.
In Python, you might express the contract as an abstract base class:
from abc import ABC, abstractmethod
class InferenceModule(ABC):
task_name: str
version: str
@abstractmethod
def load(self, resources: dict) -> None:
...
@abstractmethod
def predict(self, request: dict) -> dict:
...
@abstractmethod
def teardown(self) -> None:
...
Everything else—model choice, prompt engineering, post-processing—stays inside the plugin. The host service only knows how to route, pass in a request, and receive a response.
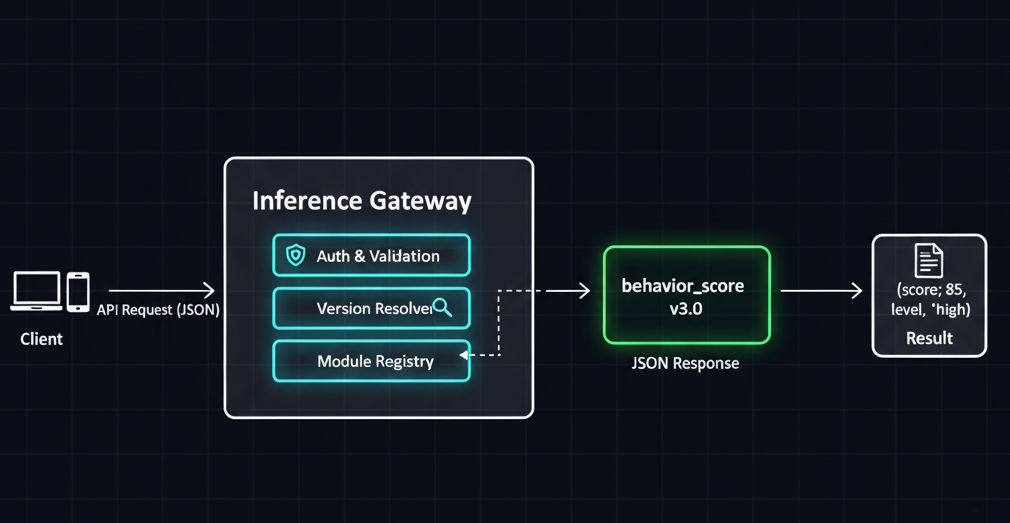
Architecture: The Inference Gateway + Module Registry
To make plugins work in production, you typically introduce two central pieces:
- Inference Gateway
- A single API surface where callers send requests like
POST /v1/inference/{task_name}with a JSON body. - Validates tasks, schemas, and auth.
- Dispatches to the correct plugin instance.
- A single API surface where callers send requests like
- Module Registry
- A mapping from
task_name+version→ plugin class/instance. - Knows how to load, cache, and teardown modules.
- Reads configuration to decide which version is “active” for a tenant or experiment.
- A mapping from
A minimal in-memory registry can be as simple as:
MODULES = {}
def register_module(module_cls):
key = (module_cls.task_name, module_cls.version)
MODULES[key] = module_cls()
return module_cls
def get_active_module(task_name, ctx) -> InferenceModule:
version = resolve_version_from_context(task_name, ctx)
module = MODULES.get((task_name, version))
if module is None:
raise LookupError(f"No module for {task_name=} {version=}")
return module
With this pattern:
- Adding a new AI behavior = implement a plugin + register it.
- Swapping behaviors = change version resolution logic (usually config-driven).
- Rolling back = flip config or feature flag, not code.
You can back this registry with DI frameworks, dynamic imports, or even per-module microservices, but the contract stays the same.
Lifecycle & Teardown: Making Modules Safe to Swap
To keep the system stable, plugins need to behave well over time. That means a disciplined lifecycle:
- Load
- Initialize heavy assets: model weights, tokenizer, vector index clients, GPU handles.
- Use shared resource pools where possible (e.g., shared HTTP clients).
- Warmup
- Run a dummy inference to JIT compile kernels, allocate tensors, or hydrate caches.
- Record latency/memory baselines for observability.
- Predict
- Pure function mindset:
response = f(request, config, resources). - No global state mutation beyond metrics/logs.
- Pure function mindset:
- Teardown
- Close file handles, DB connections, GPU sessions.
- Evict plugin-specific caches if you support live module reload.
Teardown is what makes hot-swapping and safe rollbacks possible in long-running processes. If you need to unload behavior_score v2.8.0 and load v3.0.0 at runtime, you must be confident that v2.8.0 doesn’t leave behind dangling resources.
You can enforce this with:
- A plugin harness in your test suite that runs
load → warmup → predict → teardownand asserts no resource leaks. - Runtime health checks that validate plugin readiness and log anomalies (latency spikes, error rates, memory growth).
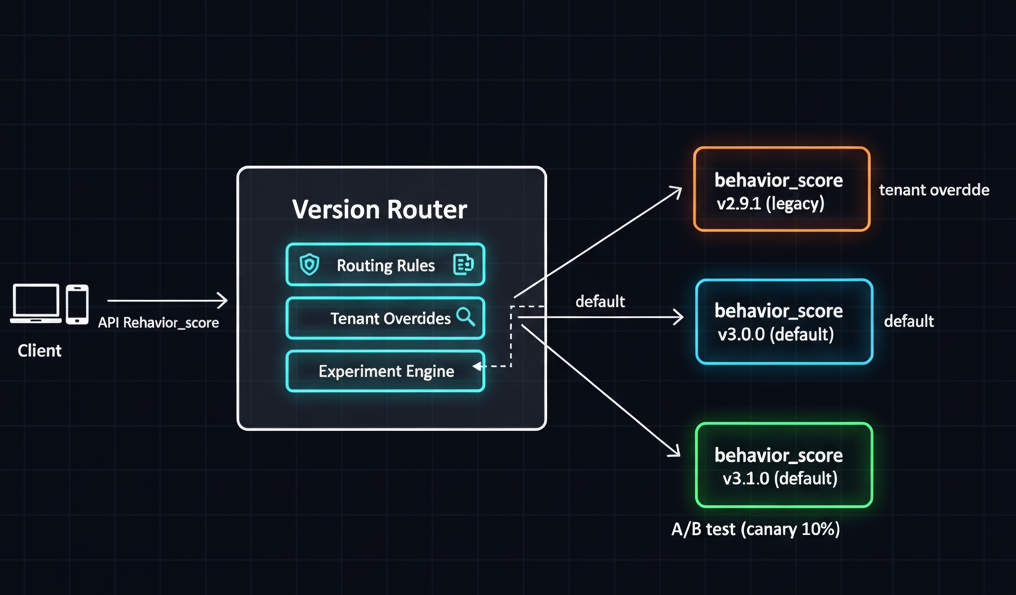
Configuration, Versioning, and Rollbacks
A plugin-based architecture works best when behavior changes are config-driven, not code-driven.
A simple pattern:
- Each plugin has a static version baked into its code:
version = "3.0.0". - A central config store (YAML, DB, or feature flag service) defines which version is active:
inference:
behavior_score:
default_version: "3.0.0"
experiments:
- name: "behavior-score-canary"
rollout: 10 # percentage
version: "3.1.0"
- name: "legacy-tenant"
tenants: ["tenant_a"]
version: "2.9.1"
Resolution logic:
- Check tenant-specific overrides.
- Check active experiments (e.g., random 10% canary).
- Fallback to default_version.
With this pattern:
- Rolling out a new model = add a version + update config.
- Rolling back = change
default_versionback to previous value. - Running comparison tests = route shadow traffic to multiple versions while only one response is user-visible.
This is where plugins shine for experimentation-heavy systems. You can explore multiple models for the same task without:
- Duplicating routes.
- Embedding experiment logic in business code.
- Rebuilding the entire service for small changes.
Testing Strategy: Making AI Modules CI-Friendly
AI behaviors can be fuzzy, but your inference surface should not be.
A solid testing strategy for plugins usually has four layers:
Contract Tests
Verify that each plugin:
- Accepts the expected request schema (required fields, types).
- Returns a response that matches the declared schema.
- Handles edge cases (empty arrays, missing optional fields) gracefully.
These tests run fast and should block any breaking schema changes.
Golden Tests
Golden tests give you stability when you change models, prompts, or post-processing.
- Maintain a curated set of inputs for each task:
- A few “typical” examples.
- A few edge cases.
- A few adversarial or noisy samples.
- For each plugin version:
- Store expected outputs or score ranges (e.g.,
0.7 ≤ score ≤ 0.9). - Ensure key invariants hold (e.g., higher activity → higher score).
- Store expected outputs or score ranges (e.g.,
When you upgrade from v3.0.0 to v3.1.0, these tests help you catch regressions early—before you ship.
Load & Resilience Tests
At least once per version:
- Run a short load test (thousands of requests).
- Measure p95/p99 latency, memory usage, and error rates.
- Validate that
load → warmup → predict → teardowncycles don’t leak.
You don’t need full-scale performance sweeps every time—but you do need to ensure it won’t blow up your infra.
Safety & Guardrail Tests
If your models can generate content, you want:
- Content safety checks (toxicity, PII, hallucination guards).
- Business-specific policy tests (no contradictory advice, no unsafe recommendations).
This can be implemented as:
- Additional plugins (e.g.,
content_safety). - Or as built-in validation inside each generative plugin.
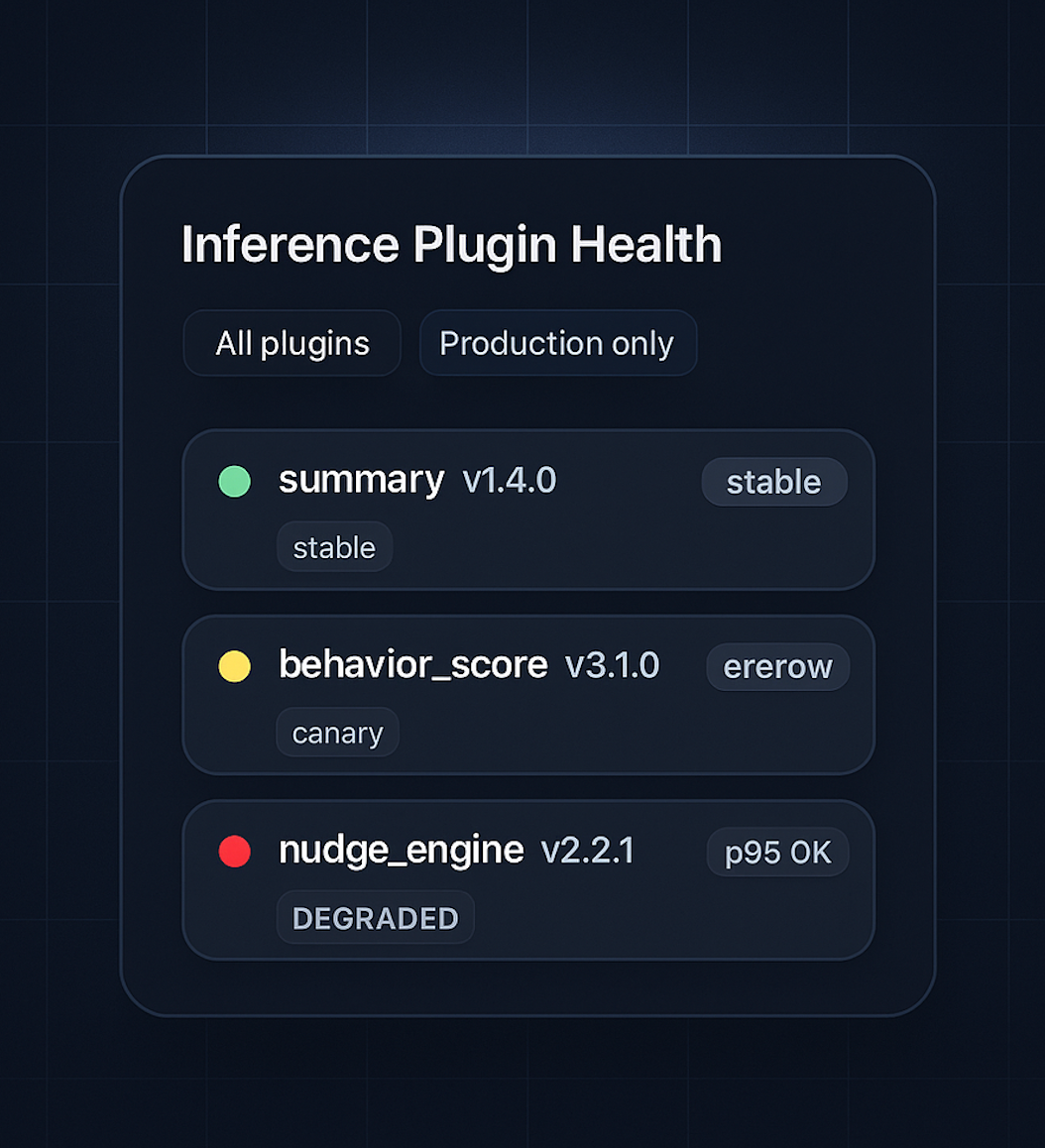
Observability: Metrics Per Module, Not Per Service
If you treat inference modules as plugins, your observability should follow the same shape.
At minimum, for each (task_name, version) pair, track:
- Traffic – Requests per second, error rate.
- Latency – p50, p95, p99, broken down by:
- Preprocessing
- Model call
- Post-processing
- Resource usage – CPU%, GPU utilization, memory.
- Outcome metrics (where possible) – e.g., acceptance rates for suggestions, click-through for nudges.
This lets you answer questions like:
- “Did
summary v1.4.0increase response time for high-traffic tenants?” - “Is
behavior_score v3.1.0spiking timeouts under load?” - “Which versions are safe to deprecate because nobody uses them?”
You can push these to your usual stack (Prometheus, CloudWatch, OpenTelemetry, etc.) but always tag by module version.
At Hoomanely, the mission is to help pet parents keep their companions healthier and happier—using data from devices and apps to power real insights, not just dashboards.
Inference plugins fit naturally into that mission:
- A behavior scoring plugin might combine sensor events and usage patterns to estimate how active or restless a pet’s day was.
- A feeding insight plugin might summarize patterns from a connected bowl and highlight when routines drift.
- A nudges plugin might turn both into gentle, actionable suggestions in the app.
By treating each of these as swappable plugins, Hoomanely’s teams can:
- Experiment with new models for a single capability (say, a better rest-score algorithm) without risking unrelated features.
- Run canaries for specific pet profiles or cohorts.
- Roll back quickly if something feels off—without any downtime or invasive deploys.
Even if you never work on pet tech, the same pattern applies to any product where AI-detected patterns flow into user-facing decisions.
Migration Pattern: From a Giant Endpoint to Plugins
If you already have a “big ball of inference” in production, you don’t have to stop the world to fix it. A pragmatic migration looks like this:
- Identify distinct tasks
- Read through your
/inferencelogic and tease out clear task boundaries:- e.g., session summarization, scoring, anomaly detection, alert generation.
- Read through your
- Define contracts per task
- For each task, define:
requestschema (what the module needs).responseschema (what it promises).
- Document this like you would an external API.
- For each task, define:
- Create the InferenceModule base class and registry
- Implement the abstract base and in-memory registry.
- Add a thin inference gateway endpoint that:
- Validates
task_name. - Resolves version from config.
- Delegates to the module.
- Validates
- Wrap existing logic as the first plugin
- Take the current production behavior for one task (say, summarization).
- Move it into a module implementing the new contract.
- Register it as
task_name="summary", version="1.0.0".
- Wire the gateway in “compatibility mode”
- Keep the old endpoint alive, but internally route through the gateway + plugin.
- This lets you test the plugin architecture without changing external clients.
- Add tests and observability
- Write contract + golden tests for the new plugin.
- Add per-module metrics and logging for that task.
- Introduce a new version as a second plugin
- Implement
summary v1.1.0with improvements. - Route only a small percentage or internal tenants to the new version.
- Compare results using golden tests and shadowing if needed.
- Implement
- Repeat for other tasks
- Gradually peel off
behavior_score,nudge_generation, etc. into plugins. - Decrease the responsibilities of the old monolithic inference code until it can be retired.
- Gradually peel off
This staged approach lets you ship value while refactoring, rather than pausing product work for a big-bang rewrite.
Key Takeaways
If you remember only a few things from this post, make it these:
- Inference plugins are just modules with a contract.
Each AI behavior gets its own request/response schema, lifecycle, config, and tests. - Centralize routing, decentralize behavior.
A single inference gateway + module registry handles dispatch; plugins own the logic. - Make changes config-driven, not code-driven.
Use config to control which version of a plugin serves which tenant or experiment; rollbacks become instant. - Test at the module boundary.
Contract tests, golden tests, and basic load/safety checks keep AI modules CI-friendly and predictable. - Instrument per
(task_name, version)pair.
Observability per module lets you see which models are healthy, noisy, or ready to deprecate.
This approach doesn’t require exotic tools. It’s mostly discipline and clear boundaries. But once you have it, you can integrate AI into your system the same way you integrate any other feature: as a well-behaved plugin that can evolve quickly without dragging the rest of your backend along with it.



