Knowledge Graphs at Hoomanely: How We Built an Alpha Layer Over RAG Retrieval

When teams build their first Retrieval-Augmented Generation (RAG) chatbot, most of the engineering effort goes into chunking, embeddings, and vector search. That is exactly where we started at Hoomanely. But after months of iterating on a pet-health assistant grounded in veterinary books, nutrition manuals, and clinical PDFs, we hit a ceiling that pure vector retrieval simply could not break through.
Our RAG-only chatbot was passing roughly 60% of our internal generation accuracy evaluations. That number sounds reasonable on a slide, but in a domain where pet owners ask about dosages, symptoms, and feeding plans, 40% of answers being weak or ungrounded is not something we were willing to ship. The failure mode was very specific, and it pointed us toward knowledge graphs.
This article walks through what knowledge graphs are in our context, how we implemented one over our existing RAG pipeline at Hoomanely, and why we ended up calling our final retrieval layer the alpha layer - a system that consistently scored lower on generation when retrieved context was only somewhat relevant, but recovered cleanly when context was either strongly relevant or clearly irrelevant.
Why Pure RAG Was Not Enough
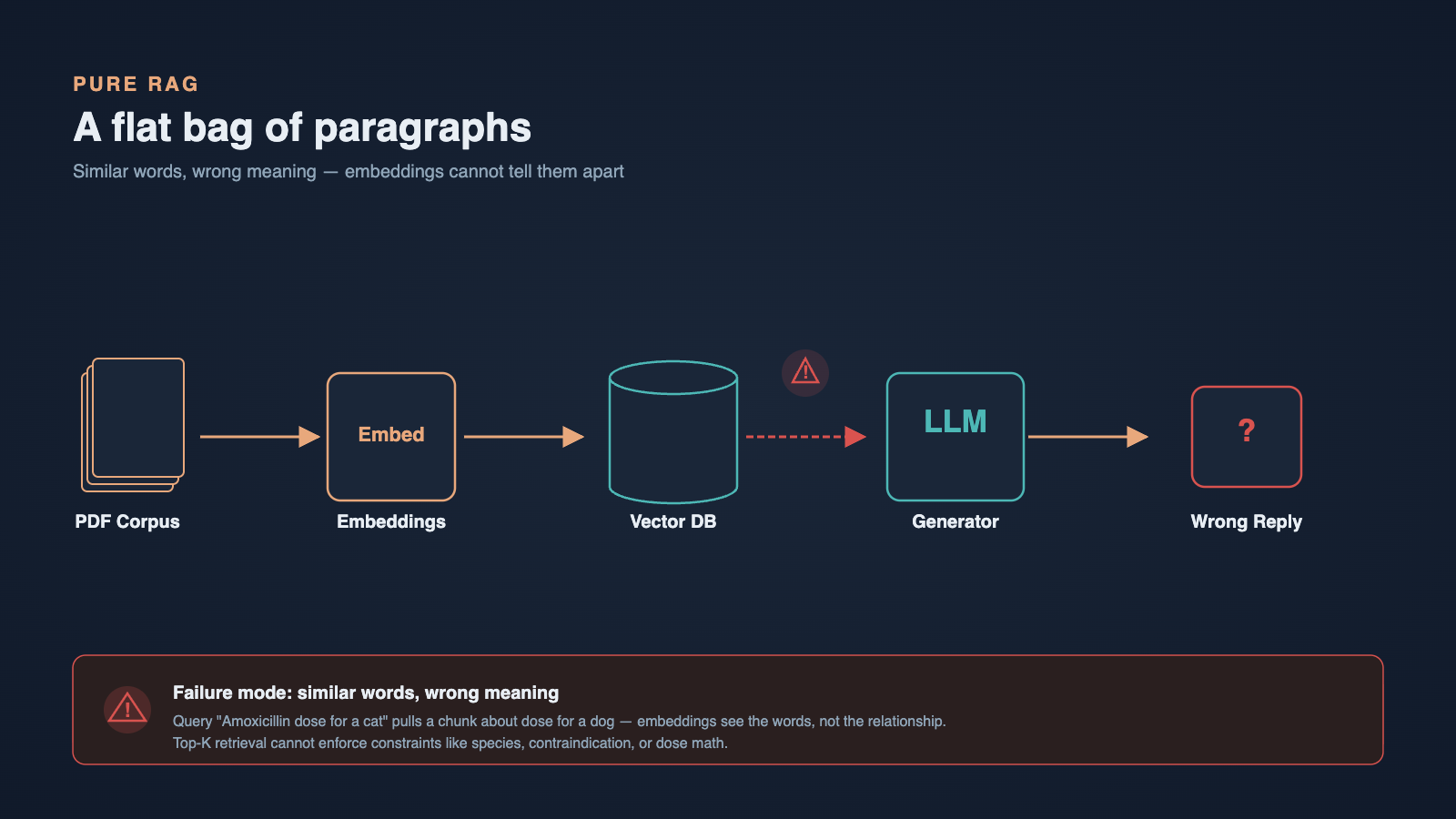
Vector retrieval is excellent at one thing: pulling chunks that look semantically similar to the query. In a long pet-health corpus, that turns out to be both a strength and a weakness.
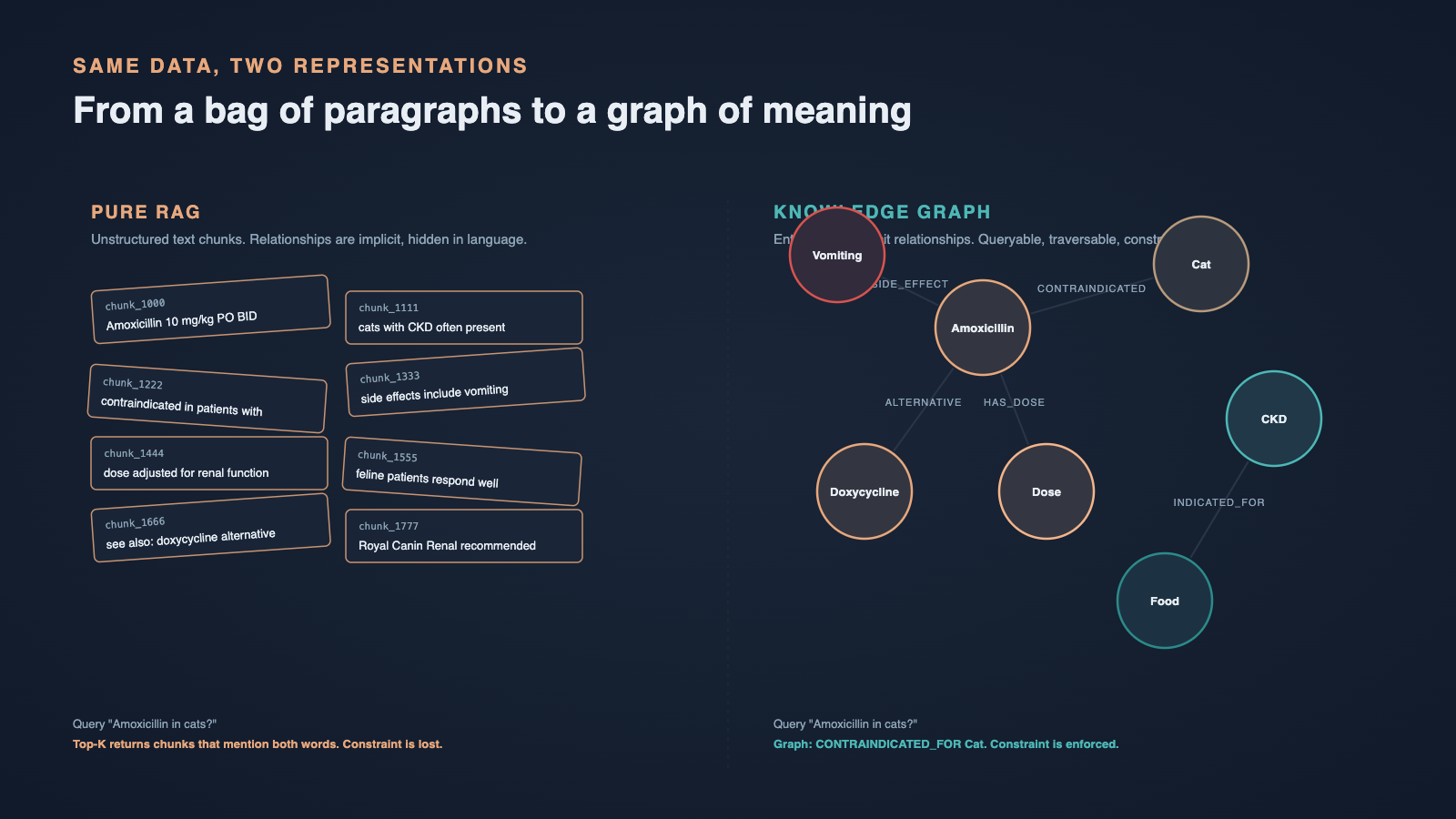
When a user asks something like "how much amoxicillin can I give my 12kg Labrador", the vector store happily returns chunks that mention amoxicillin, Labradors, and dosage tables - but rarely the exact intersection. The chunks are individually relevant, yet the relationships between entities (drug, weight, species, condition) are lost the moment the text is flattened into embeddings.
We observed three repeating failure patterns. First, partial-context drift, where the LLM had two or three loosely related chunks and confidently stitched them into an answer that read fluently but mixed dosages across species. Second, multi-hop collapse, where the question needed reasoning across two facts ("is this food safe for a dog with kidney disease") and the retriever returned either the food facts or the disease facts, never both. Third, entity confusion, where similar drug or breed names produced chunks that were near in vector space but clinically very different.
These are not bugs in the embedding model. They are structural limits of treating a domain corpus as a flat bag of paragraphs.
Enter Knowledge Graphs
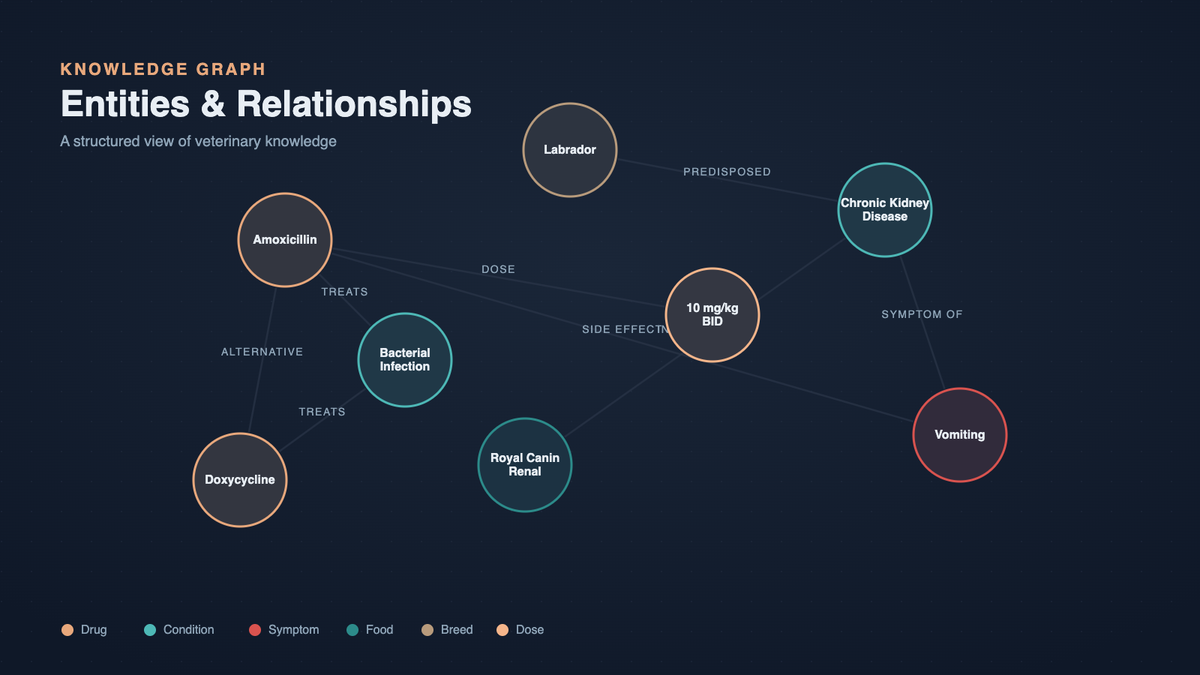
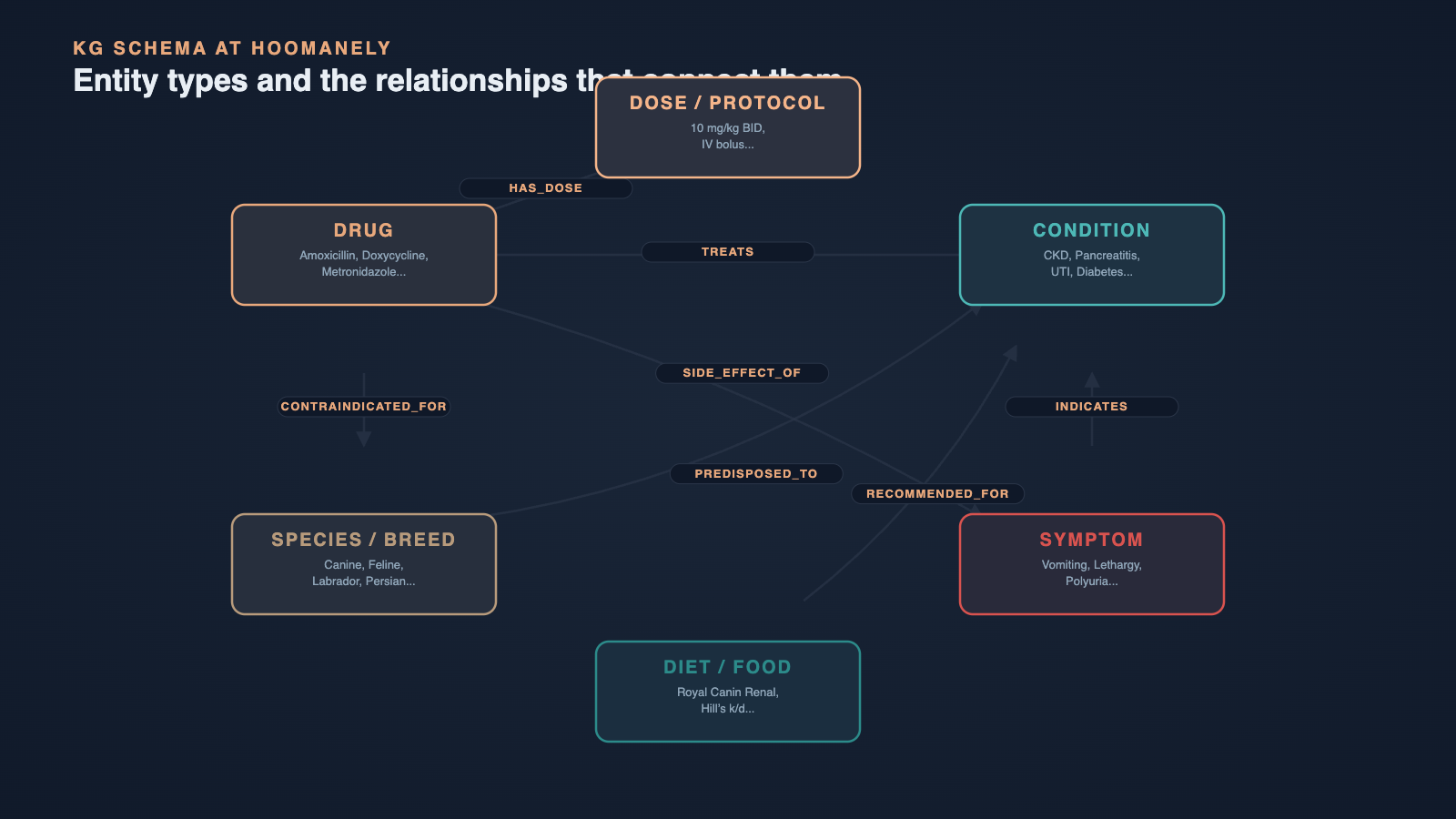
A knowledge graph stores information as entities and relationships rather than as paragraphs. In our domain, entities include things like "Amoxicillin", "Labrador Retriever", "Chronic Kidney Disease", "Royal Canin Renal Support", and "Vomiting". Relationships connect them with explicit verbs: TREATS, CONTRAINDICATED_FOR, RECOMMENDED_DOSAGE_FOR, SIDE_EFFECT_OF, ALTERNATIVE_TO.
The payoff is that a single hop in the graph can answer questions that pure vector search struggles with, because the structure is already aligned with how veterinary reasoning works. You do not need to read paragraphs to know that a drug is contraindicated for a condition - that edge either exists in the graph or it does not.
We never planned for the knowledge graph to replace RAG. The corpus is too rich and too narrative for that. Long explanations, edge cases, and clinical nuance belong in unstructured text. The graph was always meant to be a precision layer sitting beside the recall-heavy vector index.
How We Built the Knowledge Graph at Hoomanely
Our construction pipeline runs on top of the same OCR output that feeds our vector index. After Google Document AI returns clean, layout-aware text, we branch into two parallel paths: one path produces chunks for embedding, and the other extracts structured facts for the graph.
For extraction, we use an LLM-driven pass guided by a tightly scoped pet-health ontology. The ontology defines a small, controlled vocabulary of entity types (Species, Breed, Condition, Drug, Food, Symptom, Procedure, Nutrient) and an equally tight set of allowed relationships. Constraining the schema is the single most important decision we made - open-ended extraction produced messy graphs that looked impressive in demos but degraded retrieval.
Each extracted triple is tagged with its source: the document, the page, and the chunk it came from. This back-link is critical, because every graph answer in the final system can be traced back to the original veterinary text, which is what our reviewers need to validate clinical safety.
Entities are then resolved and merged. "Amoxicillin", "amoxicillin trihydrate", and "Amoxil" are normalized to a canonical node, with aliases preserved as properties. We rely on a mix of string similarity, embedding-based clustering, and curated synonym lists from veterinary references. Without this resolution step, the graph fragments and the precision advantage disappears.
Finally, the graph lives in a property-graph store with vector embeddings attached to each node. That dual representation lets us do classic graph traversals and embedding-based node lookups in the same query.
The Alpha Layer: Graph Over RAG
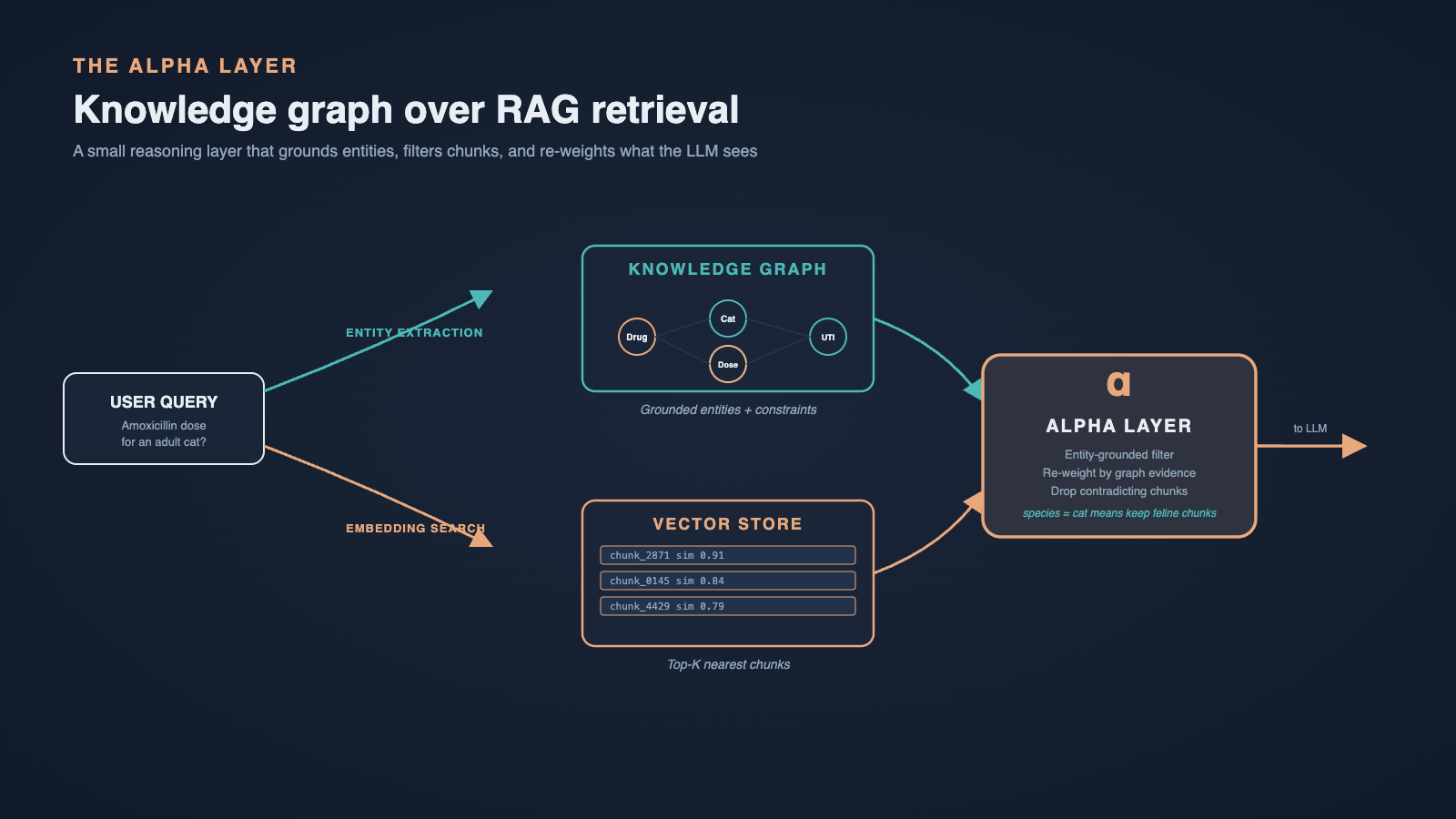
Once the graph was in place, the obvious next step was to wire it into retrieval. We did not want a parallel chatbot or a separate "graph mode" - we wanted one system that quietly used graph evidence when it helped and stepped aside when it did not. We called this layer the alpha layer, because it sits at the top of the retrieval stack and decides what context actually reaches the LLM.
The alpha layer runs in three stages. First, query understanding identifies candidate entities in the user question and links them to graph nodes. Second, graph expansion walks one or two hops from those nodes along permitted relationship types relevant to the question intent (treatment, dosage, contraindication, nutrition). Third, evidence fusion merges the graph-derived facts with the top-k vector chunks and produces a single, ranked context window for the LLM.
The rule of the alpha layer is simple: graph facts are treated as high-confidence anchors, and vector chunks provide the narrative around them. When the graph cannot find a confident match, we degrade gracefully to pure RAG. When the graph returns a strong match and the vector chunks agree, the LLM has both structured evidence and supporting text - exactly what grounding needs.
The Counterintuitive Result: Lower Scores in the Middle
The most interesting finding from our evaluation was not that the alpha layer raised our top-line accuracy. It did, but the more important pattern was how the failure curve changed shape.
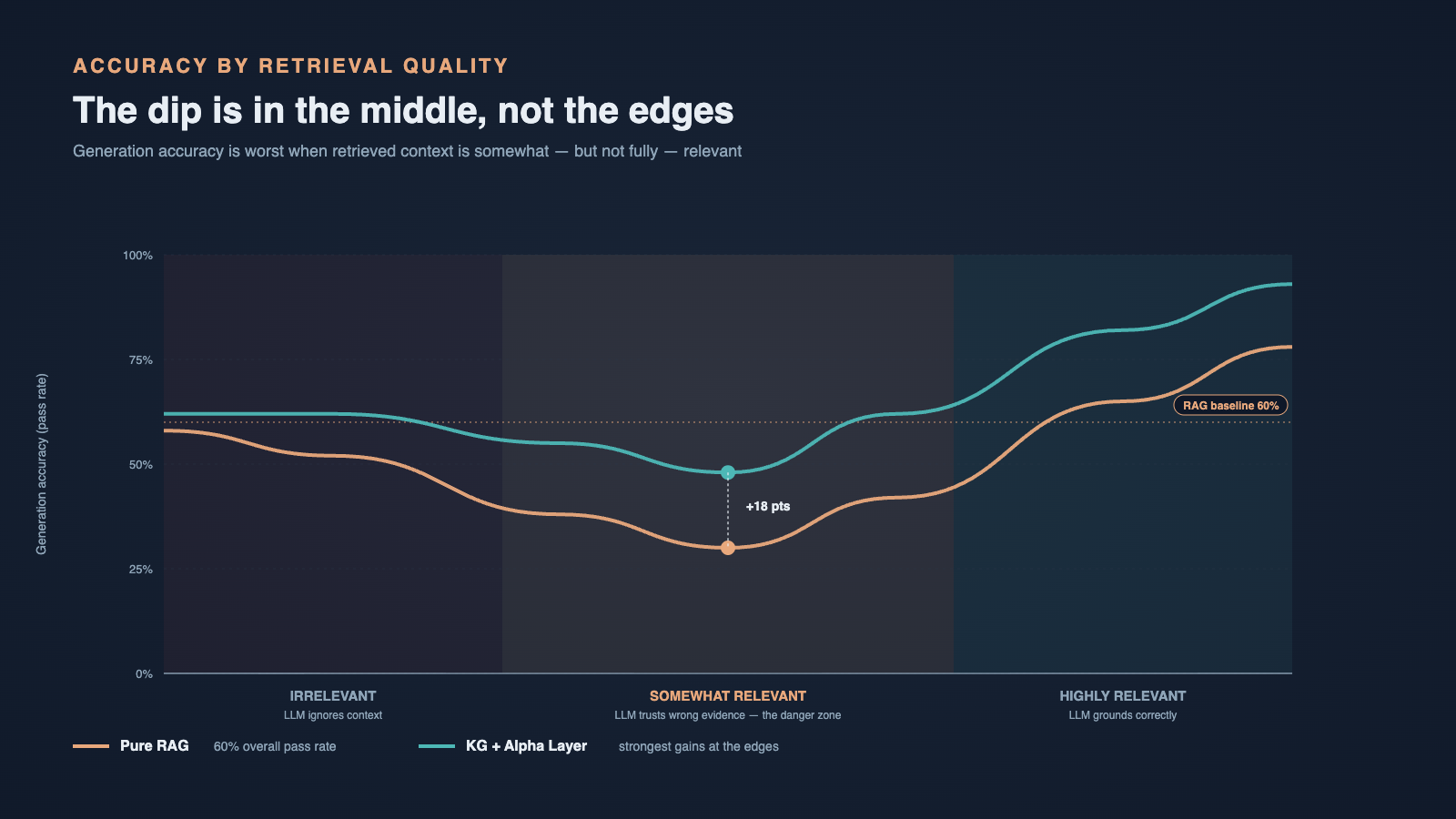
In the pure RAG baseline, the chatbot passed about 60% of generation accuracy checks. When we layered the knowledge graph on top, the system started behaving in a very specific way depending on retrieval quality.
When graph context was clearly relevant - a confident entity match, a clean traversal, agreeing vector chunks - the LLM produced precise, well-grounded answers, and our accuracy climbed sharply. When graph context was clearly irrelevant - no entity match, low-confidence edges - the LLM essentially ignored it and either fell back to RAG or answered cautiously. That graceful ignore behaviour was something we tuned deliberately by adjusting the prompt and the alpha layer's confidence thresholds.
The surprise was in the middle. When the retrieved graph context was only somewhat relevant - the right entity but a weak relationship, or a related-but-not-target node - generation accuracy actually dipped below the RAG baseline. The LLM took the partial graph signal seriously, anchored on it, and produced answers that were confidently off-target. Strong-but-wrong is worse than weak-but-honest.
This is what made us call it the alpha layer rather than a fix. It is an aggressive top-of-stack signal: when it is right, the answer is dramatically better; when it is loosely right, it can pull generation away from a safer RAG-only answer. The model trusts structure more than prose, and that trust cuts both ways.
How We Tuned for the Middle Zone
The middle-zone regression was not something we could prompt our way out of entirely. We had to make the alpha layer itself more honest about its own confidence.
We added a calibrated confidence score on every graph-derived fact, combining the strength of entity linking, the relationship type's reliability in our extraction logs, and the agreement between graph facts and the top vector chunks. Facts below a threshold are dropped before they ever reach the LLM, even if they are technically a match.
We also rewrote prompts so that the LLM treats graph facts as one source of evidence rather than as ground truth. When the graph is uncertain, the prompt explicitly tells the model to prefer the vector chunks and to acknowledge uncertainty if the two disagree.
Finally, our evaluation harness now stratifies test questions by retrieval quality - clear hit, partial hit, clear miss - so the middle zone is something we can watch directly instead of averaging it away.
What We Took Away
Knowledge graphs are not a drop-in upgrade for RAG. They are a different shape of evidence, and they interact with LLMs in ways that pure-text retrieval does not. At Hoomanely, the alpha layer we built over our RAG pipeline gave us sharper answers on the questions that matter most for pet health, while making it very clear where we still have work to do.
The 60% pure-RAG baseline was a useful number, but the more useful number turned out to be the shape of the accuracy curve across retrieval-quality bands. Highly relevant graph context produces our best answers. Clearly irrelevant graph context is safely ignored. The middle zone is where the real engineering lives, and it is the part we are still tuning.
If there is one lesson we would pass on to other teams adding knowledge graphs to a RAG system, it is this: build the graph small, build it strict, and trust it only as much as your confidence scores deserve. The alpha layer is powerful precisely because it is opinionated - and that is also why it must be calibrated with care.