Policy-Driven Model Routing: Selecting the Right LLM Per Request
The first LLM integration is usually simple: you pick one provider, one model, one API key, and ship. The second and third are where things start to hurt.
Suddenly you have a “cheap” model for bulk tasks, a “smart” model for critical flows, maybe a vision model, maybe a provider change for one region. Routing logic leaks into handlers, feature flags, and tests. A simple “call the model” turns into nested if tenant == ... and feature == ... branches scattered across the codebase.
This post is about treating model choice as a first-class concern.
We’ll walk through how to build a policy-driven routing layer—an AI gateway that picks the right LLM per request based on feature, tenant tier, risk profile, latency budget, and cost constraints. Along the way, we’ll see how to keep it:
- Config-driven, not hardcoded
- Safe, with fallbacks and experiments
- Observable, so every routing decision is explainable
And we’ll ground it in a real product context, as used in Hoomanely’s AI stack powering pet wellness experiences.
The Problem: One “Default Model” Doesn’t Scale
At small scale, a single default model is fine. But as your AI surface area grows, three constraints collide:
Cost
- Draft emails vs. safety-critical health advice should not be billed at the same $/1K tokens.
- Some tenants can pay for premium quality; some can’t.
Latency
- A 2-second multi-turn assistant is acceptable.
- A 2-second autocomplete in a mobile app is not.
Risk profile
- A misphrased marketing tagline is annoying.
- A misworded escalation or health recommendation can be damaging.
If you route everything through a single “best” model, you either:
- Overpay, because you’re using an over-powered model for trivial tasks, or
- Underperform, because you’re using a cheap model where you really needed reliability, context handling, or better safety tooling.
This starts as a quick patch and ends as if–else spaghetti across services, with no single place to answer:
- Why did this request hit that model?
- What’s the cost distribution per feature and tenant?
- Can we turn on a canary for one segment?
We need a routing layer that centralizes these decisions.

Concept: What Is Policy-Driven Model Routing?
Policy-driven model routing means:
Given a request with known attributes (feature, user, risk, budget, etc.), choose which model to call using declarative policies instead of ad-hoc code.
You define policies like:
- “For free-tier users on bulk summarization, use
cheap-4kup to 512 tokens.” - “For enterprise incident reports, always use
premium-32kand enable safety filters.” - “During this canary experiment, 10% of
chat_supporttraffic goes tocandidate-8b.”
The routing layer becomes an AI gateway:
- Receives a typed, normalized inference request
- Evaluates policies over request attributes
- Picks a model (or chain of models)
- Executes with fallbacks and logs why that decision was made
This gives you:
- Separation of concerns – app code says what task it wants, policies decide which model.
- Easier evolution – changing routing rules is a config change, not a deploy.
- Better observability – you can answer “what policy fired?” in one place.
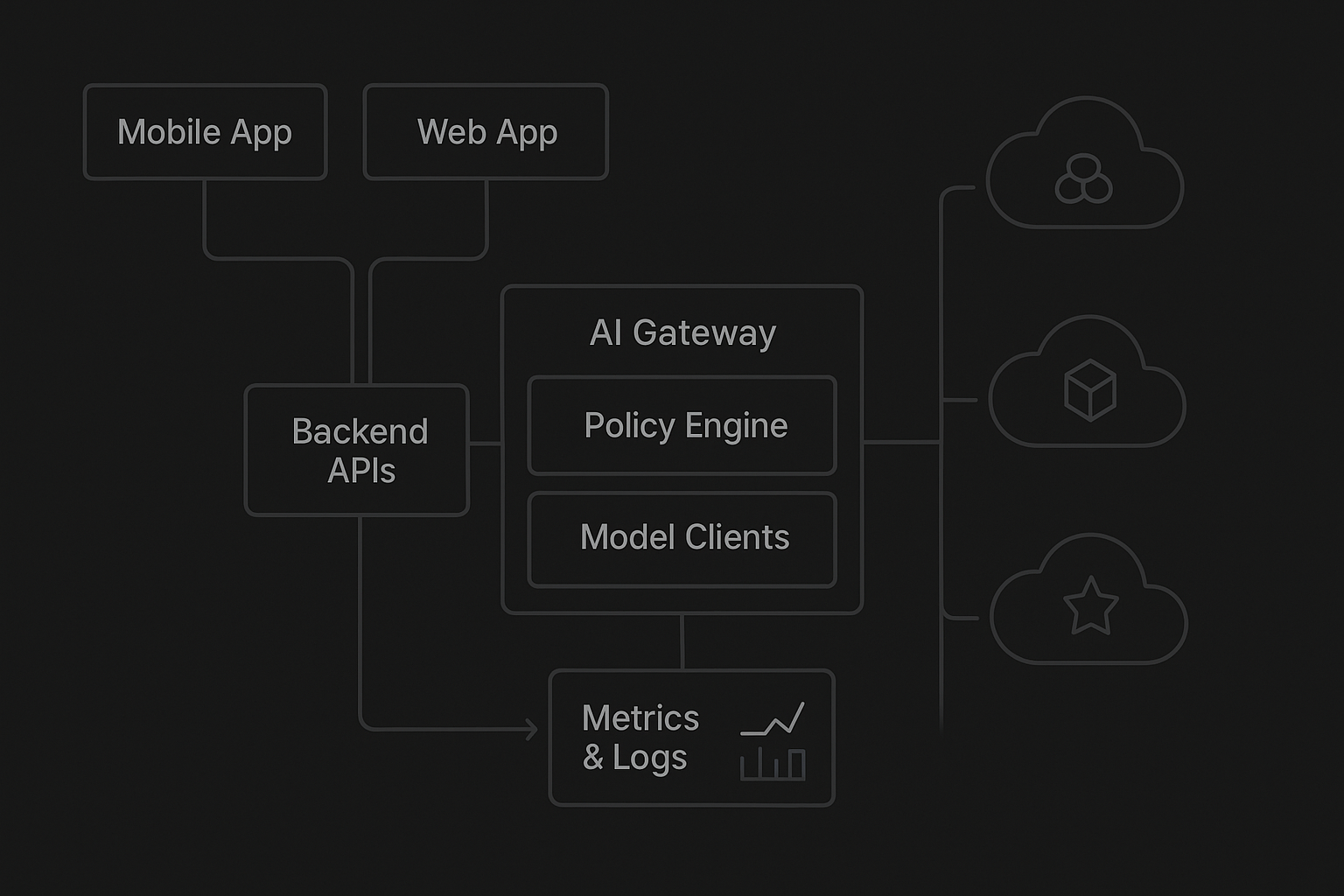
Architecture: A Python-Based AI Gateway with Routing
Let’s start from a high-level data flow. Imagine your stack:
- Mobile/web apps
- Backend APIs (Python / Node / Go, etc.)
- AI gateway service (Python-based)
- Multiple LLM providers (Bedrock, OpenAI, Anthropic, internal models, etc.)
The AI gateway owns:
- Request normalization
- Policy evaluation
- Model client abstraction
- Fallbacks & experiments
- Telemetry & audit log
At a high level:
Gateway normalizes and enriches with metadata:
- Tenant config
- User tier
- Region, platform
- Historical signals (e.g., spend YTD)
Policy engine runs:
- Evaluate rules -> pick model config:
model_id = "vendor_x::smart-16k"max_tokens = 1024safety_preset = "standard"
Model client executes:
- Call provider
- Handle retries / timeouts / fallbacks
Router logs decision:
- Policy ID, matched conditions, chosen model
- Latency, tokens, success/failure
App sends a logical request to the AI gateway:
{
"feature": "session_summary",
"tenant_id": "acme_inc",
"user_tier": "pro",
"risk_level": "medium",
"input_size": 2300,
"timeout_ms": 2500,
"payload": { "...": "..." }
}
Policy Design: Encoding Product Decisions as Config
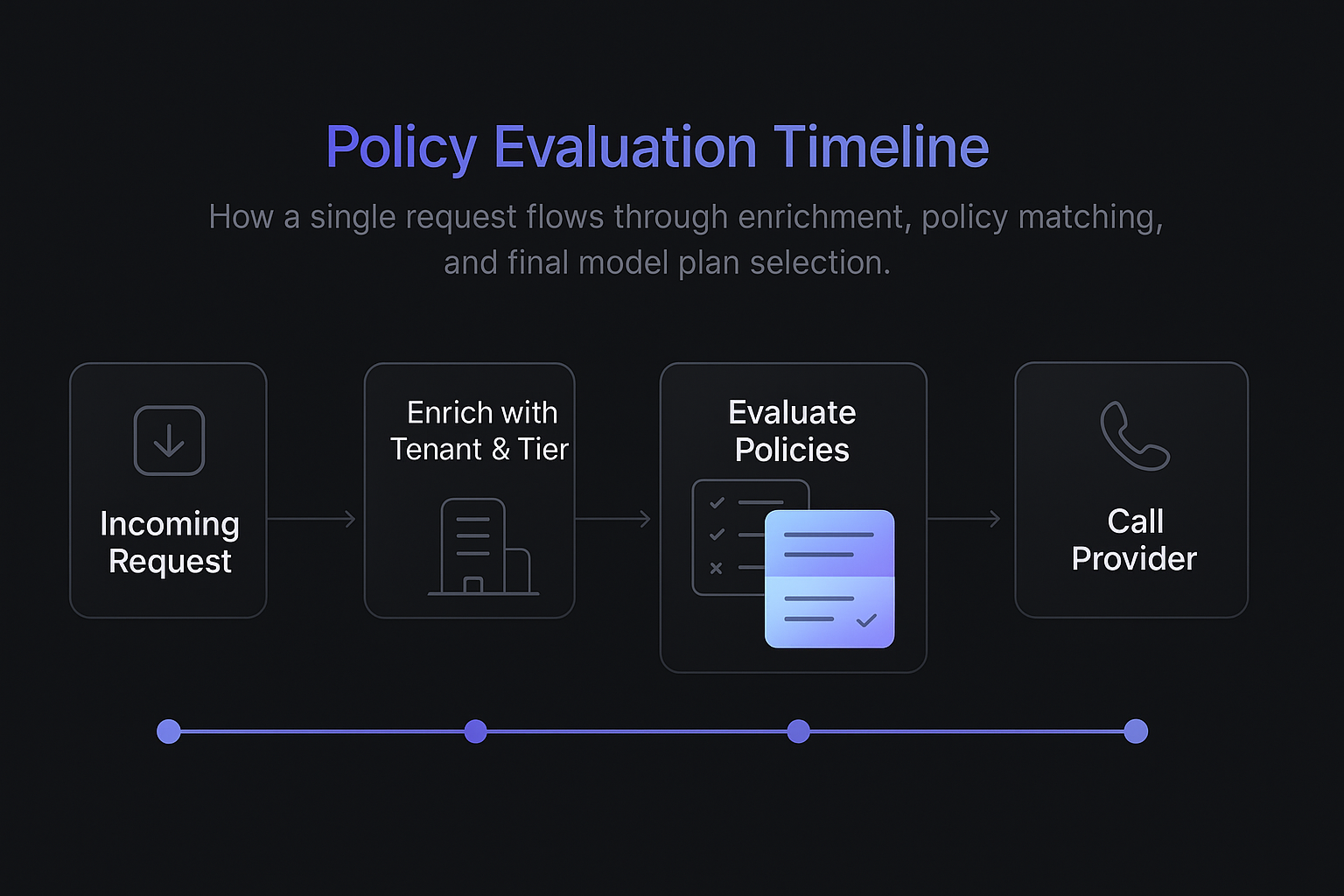
The heart of the system is the policy model: how you declare rules and resolve conflicts.
A practical approach is a tiered policy evaluation:
- Feature-level policy – what’s the default behavior for this feature?
- Tenant / tier overrides – what changes for paid plans or specific customers?
- Risk & SLA constraints – what if latency or safety must be prioritized?
- Experiment flags – A/B tests, canaries, or traffic splits.
A simple YAML/JSON structure might look like:
policies:
- id: "feature.chat.default"
when:
feature: "chat_assistant"
use_model: "vendor_a::chat-8k"
max_tokens: 1024
- id: "feature.chat.enterprise_upgrade"
when:
feature: "chat_assistant"
tenant_tier: "enterprise"
use_model: "vendor_b::chat-premium-32k"
max_tokens: 2048
- id: "feature.summary.low_risk_bulk"
when:
feature: "bulk_summary"
risk_level: "low"
use_model: "vendor_c::cheap-4k"
max_tokens: 512
You can extend this with conditional expressions:
- id: "latency_sensitive_fast_path"
when:
feature: "inline_assist"
max_latency_ms: "<=1500"
prefer_models:
- "vendor_a::fast-4k"
- "vendor_a::fast-1k"
The engine should:
- Match all applicable policies
- Resolve with priority or specificity rules (e.g., most specific
whenwins) - Attach metadata (like max tokens, safety preset, temperature, etc.)
Tenants, Tiers, and SLAs
In multi-tenant products, routing is a powerful way to encode SLAs:
- Free tier: low-cost model, stricter rate limits, lower max tokens.
- Pro tier: balanced model, moderate context window.
- Enterprise: premium models, longer context, higher timeouts, better fallbacks.
Those decisions stay outside your app handlers; the handler just says:
router.infer(
feature="coach_answer",
tenant_id=current_tenant.id,
payload=...
)
At Hoomanely, we build AI features around pet health, nutrition, and daily routines. Downstream, this includes:
- Light-weight explanations (“What does this step count mean today?”)
- Deeper, multi-signal insights (“How is activity + food + temperature trending?”)
- User-facing guidance (“What should I adjust in my dog’s feeding schedule?”)
Here, policy-driven routing helps us:
- Use cost-efficient models for bulk summarization of sensor events.
- Reserve stronger models for flows where wording and nuance matter more (e.g., health-related nudges, long-form explanations).
- Gradually introduce new model families (e.g., better at time-series reasoning) via canaries for specific segments before rolling out broadly.
We rarely want to hardcode “use Model X for EverBowl and Model Y for EverSense”. Instead, we route by feature category (e.g. “daily insight”, “trend explanation”, “setup assistant”) and risk level, so new devices and features can plug in without rewriting routing logic.
Implementing the Policy Engine (Python Sketch)
You don’t need a full rule engine to get started. A structured, testable approach is:
Request Envelope
Create a typed request object that every caller uses:
from dataclasses import dataclass
from typing import Dict, Any
@dataclass
class InferenceRequest:
feature: str
tenant_id: str
user_tier: str
risk_level: str
input_size: int
timeout_ms: int
payload: Dict[str, Any]
metadata: Dict[str, Any] = None
All routing decisions must be derivable from this plus static config.
Policy Representation
Load your YAML/JSON into normalized in-memory rules:
@dataclass
class Policy:
id: str
conditions: Dict[str, Any] # e.g. {"feature": "chat_assistant", "user_tier": "enterprise"}
config: Dict[str, Any] # e.g. {"use_model": "vendor_a::chat-8k"}
priority: int = 0
Matching Logic
Simple matching can be “all key-value pairs equal” plus some helpers for ranges:
def matches(policy: Policy, req: InferenceRequest) -> bool:
for key, expected in policy.conditions.items():
actual = getattr(req, key, None)
if isinstance(expected, dict) and "lte" in expected:
if not (actual <= expected["lte"]):
return False
elif actual != expected:
return False
return True
Then evaluation:
def select_policy(policies, req: InferenceRequest) -> Policy:
candidates = [p for p in policies if matches(p, req)]
if not candidates:
raise RuntimeError("No matching policy")
# pick highest priority, then most specific (more conditions)
candidates.sort(key=lambda p: (p.priority, len(p.conditions)), reverse=True)
return candidates[0]
The output of the policy engine is a model invocation plan, not just a string:
@dataclass
class ModelPlan:
model_id: str
max_tokens: int
temperature: float
safety_preset: str
fallbacks: list # list of model_ids
This keeps everything explicit and testable.
Fallbacks, Canaries, and A/B Tests
Routing isn’t just “pick one model”. It’s also about what happens when things go wrong and how to introduce change safely.
Fallback Strategies
Common fallbacks:
- Same provider, smaller context – if
premium-32ktimes out, retry withsmart-8k. - Different provider, similar spec – if vendor X has an outage, switch to vendor Y.
- Heuristic fallback – degrade to simpler behavior (e.g., shorter summary) instead of full feature.
Policies can include fallback chains:
- id: "session_summary_pro"
when:
feature: "session_summary"
user_tier: "pro"
use_model: "vendor_a::smart-16k"
fallbacks:
- "vendor_a::smart-8k"
- "vendor_b::chat-16k"
The router’s execution path:
- Try
smart-16kwith given timeout. - If timeout or specific error class, try
smart-8k. - If provider unavailable, try
vendor_b::chat-16k. - Log which step succeeded.
Canaries and A/B Testing
You’ll often want to compare two models on real traffic:
- New, cheaper model vs current expensive one
- New provider vs existing one
- Different safety tuning or system prompts
Introduce a traffic split policy:
- id: "chat_candidate_canary"
when:
feature: "chat_assistant"
user_tier: "pro"
experiment:
name: "chat_model_v2_canary"
variants:
- model_id: "vendor_a::chat-8k"
weight: 0.8
- model_id: "vendor_c::candidate-12b"
weight: 0.2
The router:
- Deterministically assigns a user or session to a variant (e.g., hash of
tenant_id + user_id). - Logs variant name, chosen model, and metrics.
- Lets you compare cost, latency, and user outcomes.
Because this is config, not code, product and infra teams can collaborate without stepping on each other.
Observability: Making Routing Decisions Explainable
Routing is only useful if you can inspect it when something breaks.
At minimum, every request should emit a structured decision log:
{
"trace_id": "abc-123",
"feature": "session_summary",
"tenant_id": "acme_inc",
"user_tier": "pro",
"policy_id": "session_summary_pro",
"chosen_model": "vendor_a::smart-16k",
"fallback_used": false,
"experiment": null,
"latency_ms": 842,
"prompt_tokens": 1800,
"completion_tokens": 400,
"cost_usd": 0.011,
"timestamp": "2025-11-26T13:05:45Z"
}
From this, you can build dashboards answering:
- Which policies fire most often?
- How is traffic distributed across models?
- Where do fallbacks trigger?
- Which experiments are succeeding?
In more advanced setups, you can:
- Capture input shape metrics (e.g., input length, language, device type) to see where a model struggles.
- Attach user outcomes (clicks, likes, follow-up actions) for offline analysis.
- Run offline replays: “How would this week’s traffic look if routed to Model Z?”
Avoiding Anti-Patterns
Policy Explosion
If every small nuance becomes its own policy, you’ll drown in config.
Guardrails:
- Start with feature-level policies.
- Introduce tenant or tier overrides only when truly needed.
- Define defaults (e.g., default latency budgets per feature).
Hidden Routing in App Code
Once you introduce the router, don’t keep sprinkling extra if conditions in handlers:
Better:
router.infer(feature="session_summary", tenant_id=tenant.id, payload=...)
Bad:
if feature == "session_summary" and user_tier == "enterprise":
router.infer(..., model_override="premium")
Use overrides sparingly, and always in a structured way (e.g., debug_force_model for QA-only workflows).
No Tests for Policies
Policies are part of your behavior contract. Treat them like code:
- Unit tests for policy matching (given request → expect model plan).
- Snapshot tests for “golden” scenarios.
- Validations on startup (no dangling model IDs, no overlapping rules without priority).
A simple testing pattern:
def test_enterprise_chat_uses_premium():
req = InferenceRequest(
feature="chat_assistant",
tenant_id="bigco",
user_tier="enterprise",
risk_level="medium",
input_size=800,
timeout_ms=3000,
payload={}
)
policy = select_policy(ALL_POLICIES, req)
assert policy.config["use_model"] == "vendor_b::chat-premium-32k"
This keeps your routing layer from silently drifting.
Wrap existing calls behind a router interface
router.infer(...)that currently just calls your old default model.- No behavior change yet.
Introduce a simple policy file
- Start with 1–2 features (e.g., bulk summarization and chat).
- Add policies that reproduce existing behavior.
Add one new routing dimension
- For example: user tier → use different models for free vs enterprise.
- Roll out to a small subset of tenants.
Add fallbacks and experiments
- Configure fallback chains for the most critical features.
- Start one canary experiment with clear monitoring.
Gradually migrate remaining features
- Over time, require all new features to define a
featurecode and routing policy before they ship.
Within a few iterations, you’ll find that “Which model should we use?” becomes a conversation about policies and SLAs, not copy-pasted API keys.
Takeaways
Policy-driven model routing is less about fancy rule engines and more about good boundaries:
- Treat model choice as a platform concern, not a local optimization.
- Express routing logic as config and policies, not scattered conditionals.
- Support fallbacks, canaries, and A/B tests as first-class features.
- Invest early in observability, so every decision is explainable.
- Tie routing to product decisions—features, tiers, risk profiles—so your AI stack naturally reflects your business and UX priorities.
AI touches multiple surfaces—from device-driven insights to in-app coaching—this approach keeps the system adaptable. New models and providers can be introduced safely, different experiences can coexist under one gateway, and you can reason about cost, latency, and safety with clarity.



