Removing Human Speech from Pet Bowl Audio


Intro
In a connected pet product, microphones can capture exactly what we need and a lot of what we do not. We want chewing, lapping, barking, and other pet-health signals. We do not want intelligible human conversation in stored audio. That is both a privacy concern and a trust issue.
At Hoomanely, this is handled directly in the edge audio pipeline by producing a privacy-first dog-only audio stream before upload. The implementation uses speech activity detection plus spectral attenuation so human voice energy is reduced while non-speech acoustic structure is preserved. This post breaks down the practical design: what problem we solved, why we chose this approach, how the signal processing works frame-by-frame, and what engineering tradeoffs matter if you want to replicate it.
Problem
Microphones near bowls pick up mixed acoustic scenes:
- Pet sounds: chewing, gulping, lapping, occasional bark bursts
- Environmental noise: hum, fan noise, room reflections
- Human speech: nearby conversations, commands, background TV speech
From a machine-learning perspective, speech is also a confounder. Human voice can overlap with the same broad frequency region as some bark-like features, which can increase false positives or make downstream classification less stable.
So we need a method that does three things at once:
- Reduce speech intelligibility for privacy
- Keep non-speech transients useful for pet event detection
- Run in production without brittle dependencies or excessive latency
Simple filtering alone is not enough. A fixed band-stop on 250-3000 Hz removes too much useful content. Full source separation can be heavy and fragile in embedded conditions. The implemented solution sits in the middle: VAD-guided, frame-level spectral attenuation.
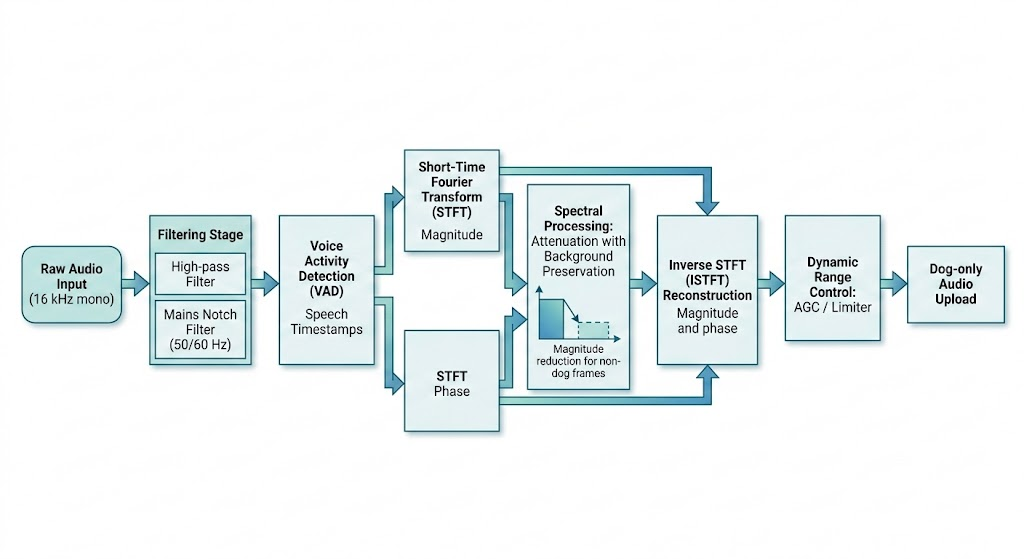
Approach
This design is intentionally conservative. It does not try to hallucinate clean pet-only stems. It attenuates speech energy above an estimated background profile and keeps the rest of the scene structure.
Process
- Front-end conditioning
Before speech suppression, the waveform is cleaned with deterministic filters:
- A 20 Hz high-pass removes very low-frequency drift
- Mains notch filtering removes 50/60 Hz hum and optional harmonics
- Optional auto-estimation (hum_auto) adjusts base hum frequency from early audio
This stage improves VAD stability and prevents low-frequency electrical noise from biasing spectral estimates.
- Speech detection with Silero VAD
Speech detection is done by Silero VAD (ONNX mode when available). The remover resamples to 16 kHz for VAD consistency, then receives timestamp segments from get_speech_timestamps(...).
Those timestamps are converted to STFT frame indices:
start_frame = ts['start'] // self.hop_length
end_frame = min(ts['end'] // self.hop_length + 1, num_stft_frames)
speech_frames[start_frame:end_frame] = True
If Silero is unavailable, the implementation safely falls back by disabling speech suppression in this path instead of risking unstable behavior.
- Spectral attenuation with background preservation
This is the core privacy mechanism.
First, the pipeline computes STFT and splits magnitude/phase. Then it estimates a background spectral profile:
- background_spectrum: 50th percentile of non-speech frames
- background_floor: 25th percentile of non-speech frames
If all frames are speech, it uses a lower percentile fallback from speech frames.
For each speech frame, it estimates the speech component as the excess above background:
speech_component = np.maximum(frame_mag - background_spectrum, 0)
attenuated_speech = speech_component * self.speech_attenuation
new_mag = background_spectrum + attenuated_speech
new_mag = np.maximum(new_mag, background_floor)
Two details matter for quality:
- Selective attenuation factor:
self.speech_attenuation = 10 ** (-speech_attenuation_db / 20)
This gives predictable dB control. - Transient protection outside core speech band:
Peaks outside roughly 200-3500 Hz are partially preserved (70% blend), so abrupt pet sounds are less likely to be over-smoothed.
After frame edits, a small time smoothing step (uniform_filter1d with size=2) reduces musical-noise artifacts, then ISTFT reconstructs the waveform.
- Loudness stabilization for downstream consistency
After suppression, the pipeline applies AGC + limiter:
- Target RMS near -19 dB
- Attack 100 ms, release 700 ms
- Peak limit around -1 dB
This matters because privacy suppression can change local energy. Normalizing dynamics helps downstream classifiers and event logic behave more consistently across rooms and hardware variation.
This is the privacy-preserving stream intended for storage/upload. Optional MelCNN inference metadata is saved in JSON (melcnn_top_label, melcnn_top_conf, class probabilities) when enabled.
Results
Because this is a production processing primitive, we evaluate outcomes in terms of privacy behavior, acoustic integrity, and operational reliability.
Privacy behavior
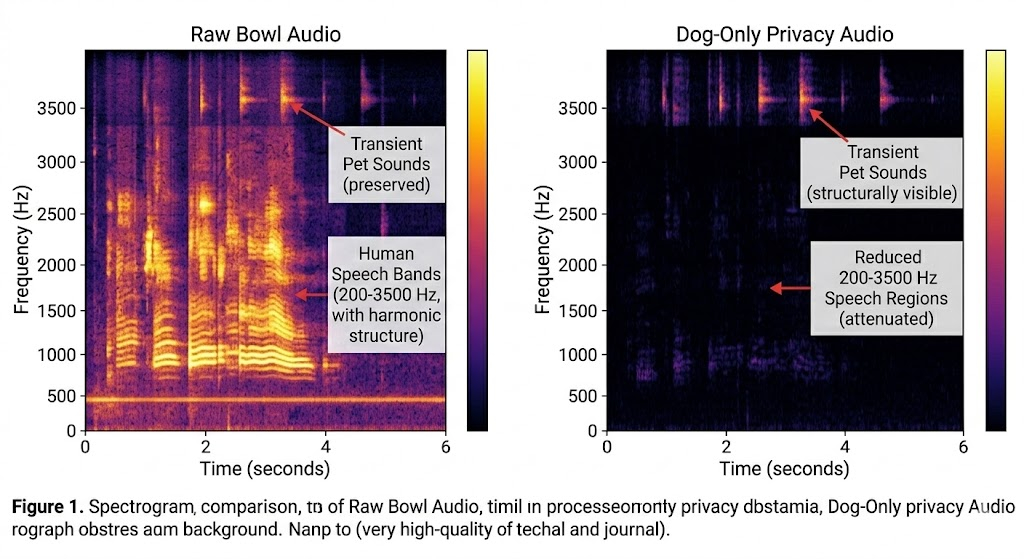
The implemented method reduces intelligible speech by targeting only detected speech frames and attenuating speech-dominant spectral excess. This is stronger than generic denoising and less destructive than always-on band-cut filters.
Acoustic integrity
The algorithm preserves background spectral floor and protects high/low-frequency transients outside the core speech region. In practice, this helps retain events like abrupt bowl interactions and bark energy edges that would otherwise be flattened.
Operational reliability
The implementation has explicit fallback behavior:
- If speech-removal dependencies fail, the pipeline avoids crashing
- Output length is forced to match input length after ISTFT
- CLI controls allow predictable tuning per deployment
What to tune first
If you adapt this in your own stack, these are the highest-impact knobs:
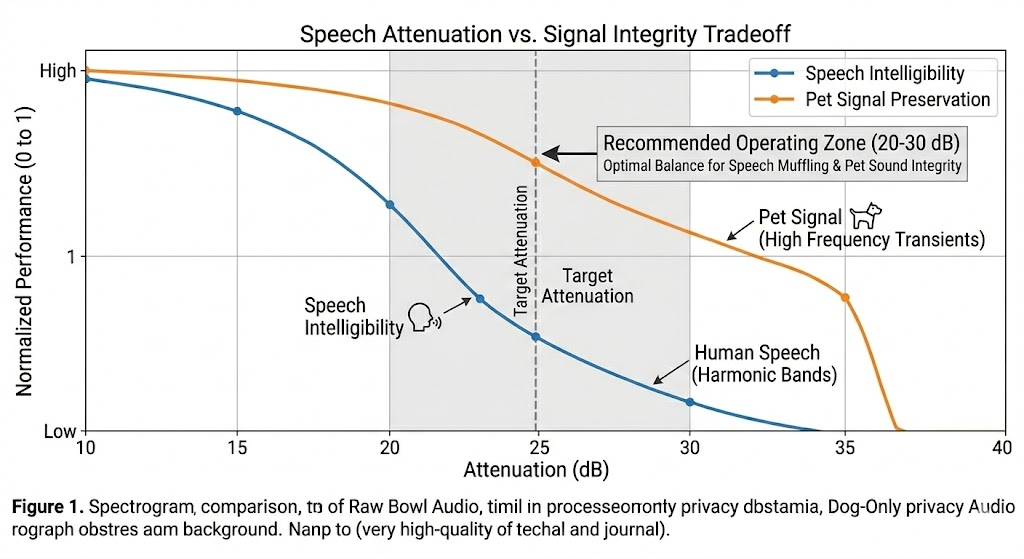
- speech_attenuation_db
Higher values increase privacy but may reduce non-speech detail during overlap. - vad_threshold
Lower values catch more speech but may over-trigger in noisy homes. - min_speech_duration_ms
Helps reduce flicker on micro-bursts. - n_fft and hop_length
Trade frequency detail vs temporal resolution and compute cost.
This method is intentionally transparent. Every stage has interpretable behavior and debuggable intermediate assumptions, which is useful for privacy-sensitive systems where engineers need confidence in what is being removed and what is being retained.
This approach strengthens that vision in two ways:
- It embeds privacy directly into the signal path rather than as an afterthought
- It keeps the audio useful for pet analytics, so privacy and model quality are improved together
Key Takeaways
- Privacy by design in audio pipelines should happen before upload/storage, not downstream
- VAD-guided spectral attenuation is a practical middle path between naive filters and heavy separation models
- Background-preserving reconstruction helps keep pet-relevant acoustic cues intact
- Small, explicit knobs (attenuation, VAD threshold, min duration) make deployment tuning manageable
- Reliable fallbacks and stable output contracts are as important as DSP quality in production systems



