Three-Tier Memory: PSRAM, Flash, and CAN FD

When you're building a sensor module that must capture high-resolution images,
store them reliably across power cycles, and ship them over a constrained CAN FD
bus — all at the same time — you run into a fundamental problem. No single
memory tier does all three jobs well. External PSRAM is fast but volatile. Flash
is persistent but slow to write. CAN FD is transport, not storage. The moment
one layer tries to carry the full load, something breaks: frames drop, storage
corrupts, or the capture pipeline stalls waiting for a transmission to finish.
This is the architecture problem we solved in our sensor modules — the
multi-modal camera and thermal imaging boards at the heart of Hoomanely's
physical intelligence platform.
The Problem: One Memory Tier Doesn't Cut It
The modules capture synchronized bursts of camera images — 517KB of raw
12-bit Bayer data at 640×400 — paired with thermal frames from a 32×24
array (768 float values). A typical burst sequence generates 3–10 of
these paired captures in rapid succession, triggered by a proximity event
detecting a pet at the monitoring station.
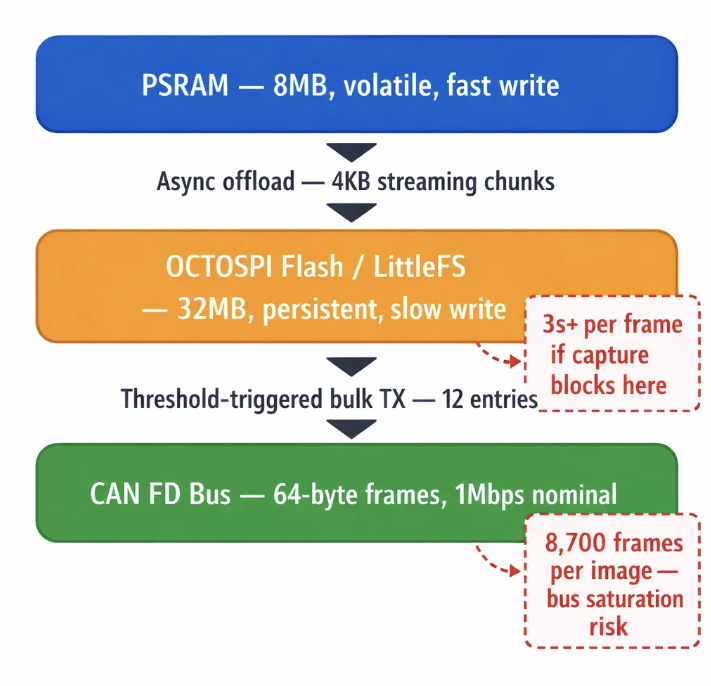
The naive approach — capture straight to flash, then transmit — hits a wall
immediately. Streaming a 517KB image to our 32MB OCTOSPI
flash in 4KB chunks, including LittleFS metadata commits, takes over three
seconds per camera frame. If the flash write blocks the capture thread, the
next burst window is missed entirely.
The inverse — skip flash, transmit over CAN FD immediately after capture — is
equally fragile. A 517KB raw image across 64-byte CAN FD frames means
approximately 8,700 individual frames on the bus. Any contention, retry, or
bus-off event during that transmission loses the data permanently with no
recovery path.
What the system needed was three tiers doing three distinct jobs, each handing
off to the next only when a threshold condition is met — never blocking, never
competing.
The Approach: One Tier, One Responsibility
The design principle we built the entire pipeline around is deliberately
simple: each memory tier owns exactly one job.
- PSRAM is the capture staging area. Every burst frame lands here first —
zero filesystem overhead, zero write latency. - LittleFS on OCTOSPI Flash is the persistence layer. Data migrates here
in streaming 4KB chunks, asynchronously, when PSRAM buffer slots fill up.
This is the safety net across power cycles and connectivity gaps. - CAN FD is the transport layer. Data only leaves the device when a
transmission threshold is met, ensuring the bus is used efficiently rather
than saturated one frame at a time.
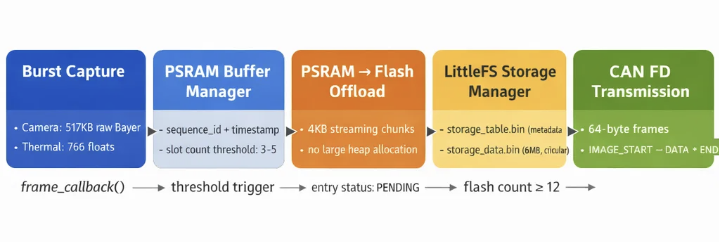
The PSRAM buffer manager holds a fixed set of slots. Each slot carries one
camera frame stored in PSRAM, its paired thermal buffer, a sequence ID, a UTC
timestamp, and the command ID of the proximity event that triggered the capture.
Slot occupancy is tracked continuously. When the count hits the configured
offload threshold, the PSRAM-to-Flash offload process begins — running
asynchronously so the next burst capture can start without waiting.
The Process: Data Moving Through Three Tiers
Tier 1 → Tier 2: PSRAM to Flash
The offload module streams each PSRAM buffer entry into the LittleFS data file
(/storage_data.bin) in 4KB chunks, avoiding any large heap allocation. At
the same time, a table entry is written to /storage_table.bin with full
metadata:
typedef struct {
uint32_t sequence_id;
uint32_t timestamp;
file_type_t file_type; // FILE_TYPE_THERMAL or FILE_TYPE_CAMERA
transmission_status_t status; // PENDING → SENDING → SENT / FAILED
uint32_t content_size;
uint32_t content_offset; // Byte offset in storage_data.bin
uint16_t command_id;
uint8_t retry_count;
} table_entry_t;
The table supports up to 5,000 entries and the data file is capped at
30MB in circular mode — space is reclaimed automatically after a successful
transmission. Every entry tracks its own status and retry count independently,
so a single failed transmission does not stall the rest of the queue.
Once the flash entry count reaches 12 (FLASH_TRANSMIT_THRESHOLD), the
storage manager signals the VBUS control layer to begin a transmission sweep.
Tier 2 → Tier 3: Flash to CAN FD
When the transmission sweep begins, the storage manager selects pending entries
in a deliberate order: thermal data first, then camera images. Thermal
frames are smaller and carry higher immediate diagnostic value for the Biosense
AI Engine — they reach the CM4 orchestrator faster even when camera data is
queued behind them.
Three distinct transmission strategies are applied based on file size, each
chosen to avoid the failure modes of the others:
| File Size | Strategy | Mechanism |
|---|---|---|
| < 32KB (small thermal) | Direct buffer | Single malloc → read full → TX → free |
| ≤ 1MB (large thermal) | Static stream | 2KB static chunks, zero heap allocation |
| Camera images (517KB+) | PSRAM-reload | Read flash back into PSRAM → TX from PSRAM |
Camera images use a PSRAM-reload path because transmitting 8,700 CAN FD
frames directly from flash — where each read has filesystem overhead — would
extend transmission time unpredictably. Loading the full image into PSRAM first
gives the CAN FD layer consistent, low-latency byte access for the entire
transmission window.
Every entry walks PENDING → SENDING → SENT, with up to 3 retry attempts
before being marked FAILED. Cleanup runs automatically after a successful
send, freeing the data file offset for reuse.
The Results: What the Production Logs Show
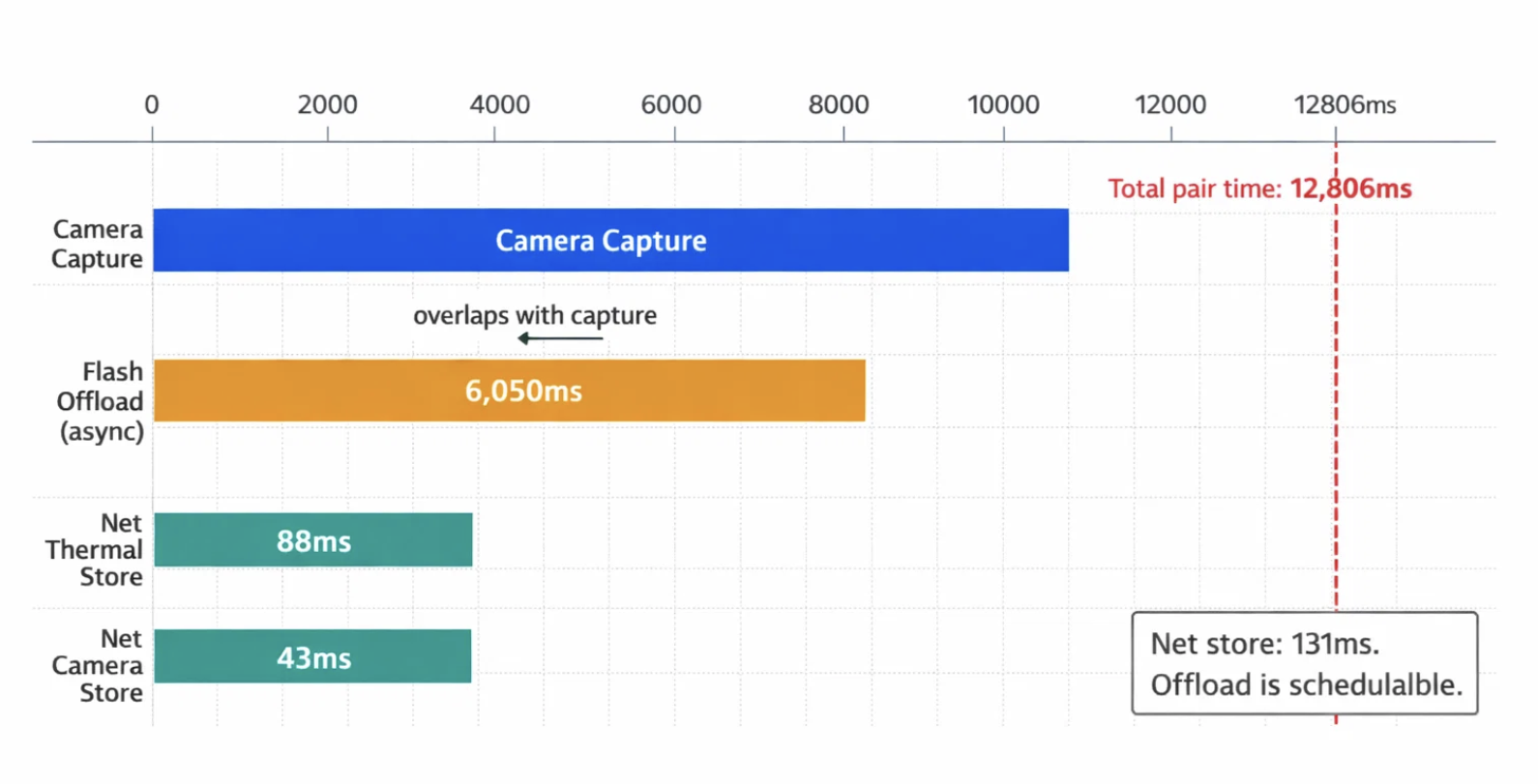
Timing data from Sequence 17 — a live device session where the PSRAM buffer
hit its 12-entry offload limit mid-burst — illustrates exactly where time goes
in the pipeline:
| Metric | Measured Value |
|---|---|
| Total burst pair time | 12,806ms |
| Flash offload duration | 6,050ms |
| Net thermal store (ex-offload) | 88ms |
| Net camera store | 43ms |
| Camera capture duration | 6,386ms |
The key insight is that the net store time is only 131ms (88ms thermal + 43ms
camera). The 6-second offload is not a fundamental bottleneck — it is a
scheduling problem. When the pipeline coordinator correctly overlaps the flash
offload with the next camera capture, that 6,050ms disappears from the critical
path entirely. The tiers were already fast enough; the work was in ensuring they
ran in parallel.
Hoomanely's mission is to reinvent pet healthcare — shifting from reactive vet
visits to continuous, AI-powered preventive monitoring that runs in the home.
Our Physical Intelligence devices generate multi-modal health data continuously:
visual body condition, thermal temperature signatures, weight trends, behavioral
patterns, and environmental quality readings. All of this is captured and
processed at the edge, with no cloud dependency on the critical capture path.
That constraint is intentional. A pet's health event does not wait for a strong
WiFi signal. The three-tier memory architecture is what makes our modules
genuinely resilient: data captured during a network outage is preserved in
flash, queued with full metadata, and transmitted the moment the CAN bus clears.
Nothing is silently dropped.
For the Biosense AI Engine to build accurate longitudinal health baselines,
it needs complete data with accurate timestamps. Every table entry carries asequence_id, timestamp, and command_id that trace back to the exact
proximity event that triggered the capture. The metadata chain is unbroken from
sensor edge to cloud inference. That traceability is not incidental — it is what
makes the difference between population-level health statistics and a
personalized health model for your specific pet.
This is not a clever engineering trick. It is the foundational infrastructure
that makes clinical-grade pet health monitoring possible outside a clinic.
Key Takeaways
- Isolate tier responsibilities ruthlessly. PSRAM captures, flash persists,
CAN FD transmits. The moment a tier tries to do two jobs, latency compounds
and data loss risk rises. - Threshold-based handoffs beat continuous streaming. Batching flash writes
in 4KB chunks and gating CAN transmissions at 12 entries reduces per-event
overhead by an order of magnitude compared to frame-by-frame approaches. - Metadata is not optional. A table entry with status, retry count, byte
offset, and command ID is what transforms a raw write into a recoverable,
auditable pipeline. Raw data without metadata is a liability, not an asset. - Async overlap is the real optimization. The 6-second flash offload is
nearly invisible when correctly scheduled alongside the next capture. The
architecture was always fast enough — the engineering work was in parallelism. - Transmission strategy must be size-aware. Three distinct TX paths (direct
buffer, static stream, PSRAM-reload) prevent the worst of both worlds: heap
exhaustion for large files, and unnecessary complexity for small ones.



