Edge Compression of Telemetry: Delta, Varint, LZ4 & MessagePack

A technical guide to shrinking IoT telemetry without breaking edge systems or cloud pipelines.
Introduction
IoT and embedded systems generate telemetry that overwhelms traditional networks. Sensor readings, actuator states, health logs, diagnostics, and event traces strain:
- Wireless bandwidth
- MCU flash wear from local buffering
- Cloud ingestion pipelines
At Hoomanely, telemetry is the backbone of our distributed pet-care IoT fleet- device health, feeding analytics, motor performance, battery behavior, and environmental context depend on continuous data flow.
Raw telemetry is expensive to transmit and store. We engineered a compression strategy that's lightweight enough for MCUs, scalable enough for gateways, and simple enough for cloud recovery pipelines.
This guide breaks down four compression techniques Delta encoding, Varint, MessagePack, and LZ4 - how they complement each other, where they should run, and why they form a reliable, maintainable telemetry pipeline.
Why Telemetry Compression Matters
Telemetry from IoT devices is typically:
- Predictable - temperature changes gradually per second
- Structured - key-value records, protobufs, TLV formats
- Repetitive - same fields across messages
- Numeric-heavy - integers, floats, timestamps
This makes it ideal for compression. But embedded systems have strict limits:
- MCU RAM measured in kilobytes
- Limited flash for program and buffer space
- CPU budgets shared with real-time tasks
- Power constraints on battery-driven nodes
This rules out heavyweight codecs like gzip, zstd, or brotli. Requirements:
- Predictable runtime behavior
- Low memory footprint
- Streaming-friendly
- Deterministic and recoverable
This leads to a layered, edge-suitable approach.
Delta Encoding - The First Layer
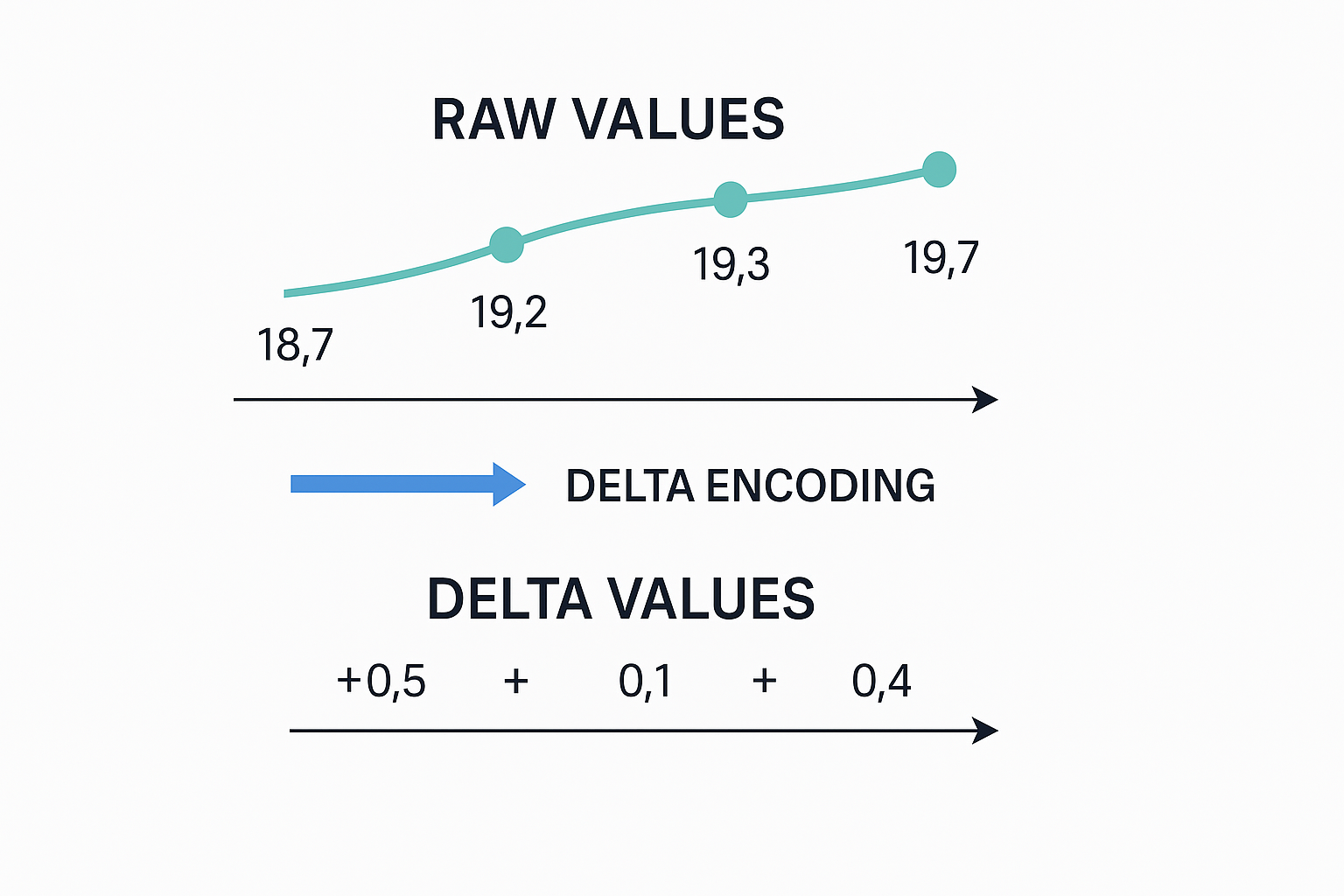
Delta encoding replaces absolute values with differences between consecutive samples.
Instead of transmitting:
temp: 24.2°C, 24.3°C, 24.4°CTransmit:
temp: 24.2°C (baseline), +0.1°C, +0.1°CWhy It Works
Most telemetry evolves slowly:
- Temperature moves gradually
- Battery voltage changes in small increments
- Motor current varies within predictable windows
- Timestamps increase monotonically
Deltas fall into smaller numeric ranges, compressing more efficiently in subsequent layers.
Key Properties
- Very low CPU cost (simple subtraction)
- Works with integers and floats
- Minimal state requirement (just the previous value)
- Bidirectionally deterministic (fully lossless)
- No dynamic memory allocation
Implementation
typedef struct {
float last_value;
bool initialized;
} DeltaEncoder;
float encode_delta(DeltaEncoder* enc, float current) {
if (!enc->initialized) {
enc->initialized = true;
enc->last_value = current;
return current; // First value is baseline
}
float delta = current - enc->last_value;
enc->last_value = current;
return delta;
}
float decode_delta(DeltaEncoder* dec, float delta) {
if (!dec->initialized) {
dec->initialized = true;
dec->last_value = delta; // First value restores baseline
return delta;
}
dec->last_value += delta;
return dec->last_value;
}
```
Critical Design Consideration
Delta encoding requires correct ordering. If packets arrive out-of-order, reconstruction fails. Solutions:
- Use sequence numbers in packet headers
- Apply delta encoding only on reliable transport layers
- Use monotonic timestamps as implicit sequence markers
Varint Encoding — Squeezing Numbers Further
After Delta, you often end up with small integers — especially with quantized floats or integer sensors (ADC values, counters, state machines).
Varint (variable-length integer) encodes small values in fewer bytes:
- Values near zero → single byte
- Larger values → more bytes as needed
This fits perfectly with delta values, which cluster around zero when telemetry is stable.
Why Varint is Ideal for Embedded Devices
- Branch-light implementation (minimal conditional logic)
- No heap allocation required
- Streaming-friendly (byte-by-byte processing)
- Simple to decode on cloud pipelines
- Naturally pairs with protobuf/MessagePack formats
Encoding Mechanism
Varint uses the high bit of each byte as a continuation flag:
- If bit 7 is set → more bytes follow
- If bit 7 is clear → this is the final byte
- Lower 7 bits of each byte carry actual data
Example encoding:
Value: 300 (decimal)
Binary: 0000_0001_0010_1100
Split into 7-bit chunks (right to left):
0000010 0101100
Encode with continuation bits:
1010_1100 0000_0010
(continue) (final)
Result: [0xAC, 0x02] — 2 bytes instead of 4Implementation
size_t encode_varint(uint32_t value, uint8_t* buffer) {
size_t index = 0;
while (value >= 0x80) {
buffer[index++] = (value & 0x7F) | 0x80; // Set continuation bit
value >>= 7;
}
buffer[index++] = value & 0x7F; // Final byte, no continuation bit
return index;
}
uint32_t decode_varint(const uint8_t* buffer, size_t* bytes_consumed) {
uint32_t result = 0;
uint32_t shift = 0;
size_t index = 0;
while (true) {
uint8_t byte = buffer[index++];
result |= ((uint32_t)(byte & 0x7F)) << shift;
if ((byte & 0x80) == 0) { // No continuation bit
*bytes_consumed = index;
return result;
}
shift += 7;
}
}Compression Effectiveness
| Value Range | Standard 32-bit | Varint Size |
|---|---|---|
| 0 to 127 | 4 bytes | 1 byte |
| 128 to 16,383 | 4 bytes | 2 bytes |
| 16,384 to 2,097,151 | 4 bytes | 3 bytes |
For delta-encoded telemetry where most values are small, this provides significant savings.
Varint aims for predictable performance with deterministic worst-case behavior, critical for MCUs running real-time workloads.
MessagePack - Binary Serialization with Built-In Efficiency
MessagePack is a binary serialization format that's significantly more compact than JSON while maintaining similar expressiveness and schema flexibility.
Why MessagePack Matters for IoT
Before applying delta/varint/LZ4, you need to serialize structured data. The format choice fundamentally impacts final payload size and processing efficiency.
JSON:
{"temp": 24.2, "humidity": 65, "battery": 3.7, "timestamp": 1732550400}
Size: Approximately 70 bytes
MessagePack equivalent: Approximately 35 bytes — roughly 50% reduction before any additional compression.
Key Advantages Over JSON
- Type preservation: Integers encoded as integers, not strings
- Compact encoding: Single-byte type tags for common types
- Schema-free: Self-describing like JSON, unlike protobuf
- Wide language support: C, Python, JavaScript, Go, Rust, Java
- Streaming-capable: Can encode/decode incrementally
- No parsing overhead: Direct binary mapping to native types
MessagePack Type Encoding Efficiency
| Data Type | JSON | MessagePack |
|---|---|---|
| Small positive int (0-127) | ASCII digits | Single byte (value itself) |
| String (≤31 chars) | Quotes + escaping | 1-byte tag + raw bytes |
| 32-bit float | ASCII representation | 1-byte tag + 4 bytes |
| Null | "null" keyword | Single 0xc0 byte |
| Boolean | "true" or "false" | Single byte (0xc2 or 0xc3) |
Format Structure
MessagePack uses a type-tag system where each value begins with a tag byte indicating both type and (sometimes) value:
Positive fixint: 0x00 - 0x7f (value is in tag itself)
fixstr: 0xa0 - 0xbf (length in tag, string follows)
fixarray: 0x90 - 0x9f (count in tag, elements follow)
fixmap: 0x80 - 0x8f (pair count in tag, keys/values follow)
float 32: 0xca + 4 bytes
uint 8: 0xcc + 1 byte
int 8: 0xd0 + 1 byteThis minimizes overhead for common small values - a value like 42 is literally a single byte: 0x2a.
Practical Example (Python)
python
import msgpack
# Encoding telemetry
telemetry = {
"temp": 24.2,
"humidity": 65,
"battery": 3.7,
"timestamp": 1732550400
}
packed = msgpack.packb(telemetry)
# MessagePack size is roughly half of JSON
# Decoding
unpacked = msgpack.unpackb(packed)
assert unpacked == telemetryEmbedded C Example
#include <msgpack.h>
void encode_telemetry_sample(uint8_t* output, size_t* output_len,
float temp, uint8_t humidity, uint32_t timestamp) {
msgpack_sbuffer sbuf;
msgpack_packer pk;
msgpack_sbuffer_init(&sbuf);
msgpack_packer_init(&pk, &sbuf, msgpack_sbuffer_write);
// Encode as map with 3 key-value pairs
msgpack_pack_map(&pk, 3);
// Key: "temp", Value: float
msgpack_pack_str(&pk, 4);
msgpack_pack_str_body(&pk, "temp", 4);
msgpack_pack_float(&pk, temp);
// Key: "humidity", Value: uint8
msgpack_pack_str(&pk, 8);
msgpack_pack_str_body(&pk, "humidity", 8);
msgpack_pack_uint8(&pk, humidity);
// Key: "timestamp", Value: uint32
msgpack_pack_str(&pk, 9);
msgpack_pack_str_body(&pk, "timestamp", 9);
msgpack_pack_uint32(&pk, timestamp);
memcpy(output, sbuf.data, sbuf.size);
*output_len = sbuf.size;
msgpack_sbuffer_destroy(&sbuf);
}
Where MessagePack Fits
MessagePack should be the first serialization step, applied BEFORE delta/varint, because:
- Reduces structural overhead (field names, type indicators, delimiters)
- Normalizes numeric types (preserves integer vs float distinction)
- Creates denser input for downstream compression layers
- Maintains self-describing capability for debugging and recovery
- Eliminates text parsing on both encode and decode paths
MessagePack vs Protobuf Trade-offs
| Aspect | MessagePack | Protobuf |
|---|---|---|
| Schema requirement | None (self-describing) | Required (.proto files) |
| Flexibility | High (arbitrary structures) | Low (strict schema) |
| Size efficiency | Good | Better (field number encoding) |
| Development speed | Fast (no code generation) | Slower (schema compilation) |
| Debugging | Easier (field names preserved) | Harder (field numbers only) |
For IoT telemetry, MessagePack offers the best balance when:
- Schema evolution is frequent
- Debugging on constrained devices is important
- Development velocity matters
- Overhead difference vs protobuf is acceptable given other compression layers
LZ4 — Dictionary-Based Compression for Gateways
LZ4 is a high-speed lossless compression algorithm optimized for scenarios where decompression speed matters as much as compression ratio.
It's not suitable for tiny MCUs but excels on:
- Edge gateways with ARM Cortex-A CPUs
- Linux-class hubs (Raspberry Pi, industrial computers)
- SoMs and modules (CM4, AM62, i.MX series)
Why LZ4 for Telemetry Gateways
- Extremely fast (GHz-class ARM cores compress at hundreds of MB/s)
- Low memory overhead (dictionary fits in L1/L2 cache)
- Streaming mode optimized for continuous log-like data
- Deterministic output (same input always produces same output)
- Frame format with checksums for integrity verification
How LZ4 Works
LZ4 uses dictionary-based compression with backward references:
- Scans input for repeated sequences
- Encodes repetitions as (offset, length) pairs
- Maintains a sliding window of recent data
- Uses simple, fast matching heuristics (not exhaustive search)
Example:
Input: "temperature: 24.2°C, temperature: 24.3°C, temperature: 24.4°C"
Output: "temperature: 24.2°C, <copy 17 bytes from -20>, 3°C, <copy 17 bytes from -20>, 4°C"The repeated string "temperature: 24." is encoded as a backreference instead of literal bytes.
Why LZ4 Shines on Pre-Processed Telemetry
LZ4 is most effective when fed structured, repetitive data:
- Repeated field names (even in MessagePack binary)
- Similar message structures across time intervals
- Batch processing (multiple messages compressed together)
- Delta-encoded values that cluster around zero
This makes it ideal as the final compression layer before network transmission or cloud storage.
Implementation Example (Python)
import lz4.frame
# Compression (at gateway)
def compress_telemetry_batch(messages: list[bytes]) -> bytes:
batch = b''.join(messages)
compressed = lz4.frame.compress(batch)
return compressed
# Decompression (in cloud)
def decompress_telemetry_batch(compressed: bytes) -> bytes:
decompressed = lz4.frame.decompress(compressed)
return decompressed
LZ4 Frame Format
LZ4 frame format adds important metadata:
[Magic Number: 4 bytes]
[Frame Descriptor: flags, block size, content size]
[Data Blocks: compressed chunks]
[End Mark: 4 bytes]
[Optional: Content Checksum]
This provides:
- Format identification (magic number detection)
- Integrity verification (checksums)
- Independent block decompression (parallel processing)
- Streaming support (process before entire frame arrives)
When NOT to Use LZ4 on Edge
Don't use LZ4 directly on MCUs when:
- CPU runs below 100 MHz
- RAM is under 64 KB
- Real-time guarantees are critical
- Single messages are being compressed (poor ratio)
Use LZ4 at gateway layer when:
- Batching multiple messages
- CPU has cycles to spare
- Network bandwidth is constrained
- Cloud ingestion costs are significant
The Complete Pipeline: Layered Compression Architecture
A production-ready, fault-tolerant telemetry pipeline combines all techniques in a carefully ordered sequence:
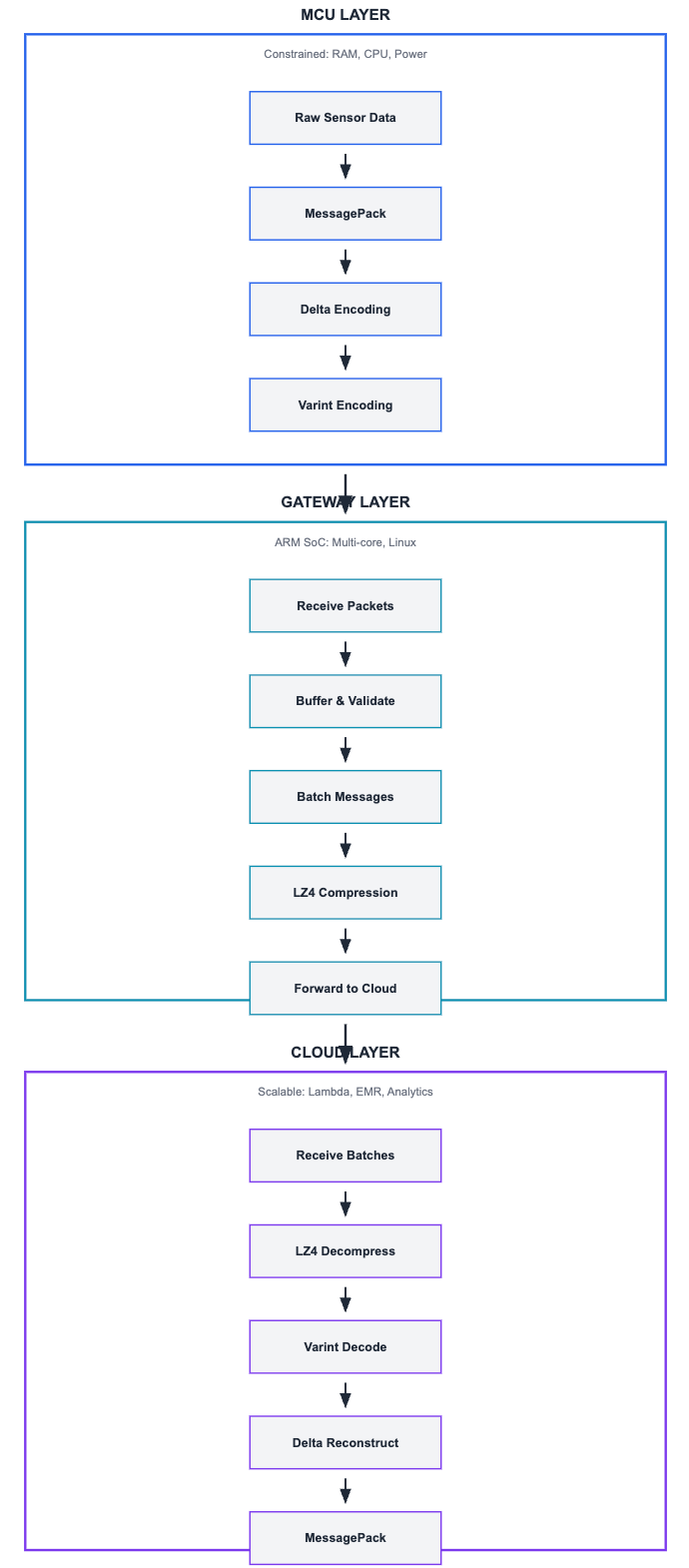
Why This Ordering Matters
The layer sequence is not arbitrary — each stage prepares data optimally for the next:
MessagePack first:
- Eliminates ASCII overhead before numeric processing
- Creates binary structure that delta/varint can work with
- Preserves type information for correct reconstruction
Delta after MessagePack:
- Operates on already-compact binary representations
- Reduces numeric magnitude, making varint more effective
- Works on individual numeric fields within structures
Varint after Delta:
- Compresses the now-small delta values efficiently
- Maintains byte-stream compatibility for transport
- Keeps MCU CPU cost minimal
LZ4 last (at gateway):
- Exploits repetition across entire batched messages
- Handles structural patterns MessagePack leaves
- Only runs where CPU and memory are abundant
Effective Compression Ratios
Measured on typical IoT telemetry (temperature, humidity, battery, timestamps, state flags):
| Stage | Technique | Typical Gain | Rationale |
|---|---|---|---|
| Baseline | JSON | Reference | Human-readable, inefficient |
| After MessagePack | Binary serialization | 2× | Removes text overhead |
| After Delta | Difference encoding | 2-3× | Most telemetry values change slowly |
| After Varint | Variable-length integers | 1.5-2× | Small deltas compress to few bytes |
| After LZ4 (batched) | Dictionary compression | 2-4× | Repeated structure across messages |
Combined effective ratio: 12-48× vs raw JSON
Layered Benefits Beyond Size
This architecture provides more than compression:
- Fault isolation — Corruption in one layer doesn't cascade
- Incremental optimization — Each layer can be tuned independently
- Testability — Clear interfaces between stages
- Debuggability — Can decode up to any stage for inspection
- Flexibility — Layers can be selectively disabled for debugging
- Predictability — Each stage has known worst-case behavior
Failure Modes & Recovery Design
Compression adds complexity. Without careful design, a single corrupt byte can break reconstruction of entire data streams.
The Problem: Cascading Failures
Consider what happens if a bit flips in transit:
Without block boundaries:
[MessagePack][Delta][Varint] → [MessagePack][Delta][Varint] → [MessagePack][Delta][Varint]
↑ corruption here
↓
All subsequent messages become undecodable
The corruption propagates because:
- Delta encoding maintains state (last value)
- Varint parsing depends on continuation bits
- MessagePack structure assumes valid type tags
Solution: Block-Based Architecture
Divide the stream into self-contained, independently decodable blocks:
[Block Header][Payload][Checksum] | [Block Header][Payload][Checksum] | ...
↑ corruption here
↓
Only this block is lost — next block decodes normallyBlock Header Design
Each telemetry block should carry metadata that enables recovery:
c
typedef struct {
uint32_t magic; // Format identifier (e.g., 0xABCD1234)
uint8_t version; // Compression pipeline version
uint8_t flags; // Compression flags (which layers active)
uint16_t payload_length; // Compressed payload size in bytes
uint32_t sequence_num; // Monotonically increasing counter
uint32_t timestamp_ms; // Unix epoch milliseconds
uint32_t crc32; // CRC-32 of payload
} TelemetryBlockHeader;What Each Field Enables
Magic number:
- Detects block boundaries in byte streams
- Allows resynchronization after corruption
- Guards against format confusion
Version field:
- Handles pipeline evolution (algorithm changes)
- Allows gradual rollout of new compression schemes
- Enables backward compatibility in cloud decoder
Flags:
- Indicates which compression layers are active
- Supports debugging (selectively disable stages)
- Allows adaptive compression based on device capabilities
Payload length:
- Enables skipping corrupted blocks
- Supports parallel processing in cloud
- Validates buffer boundaries
Sequence number:
- Detects missing blocks (gaps in sequence)
- Enables out-of-order detection
- Supports retransmission requests
Timestamp:
- Provides temporal ordering independent of sequence
- Enables time-based deduplication
- Supports interpolation across gaps
CRC32:
- Detects corruption with high probability
- Fast to compute on both MCU and cloud
- Standard, well-tested algorithm
Recovery Pipeline Logic (Cloud Side)
def process_telemetry_stream(stream: bytes) -> list[Record]:
records = []
offset = 0
expected_sequence = None
while offset < len(stream):
# Scan for magic number if not aligned
if not at_block_boundary(stream, offset):
offset = find_next_magic(stream, offset)
if offset == -1:
break
header = parse_block_header(stream[offset:offset+24])
offset += 24
payload = stream[offset:offset+header.payload_length]
offset += header.payload_length
# Validate CRC
computed_crc = crc32(payload)
if computed_crc != header.crc32:
log_error(f"CRC mismatch in block {header.sequence_num}")
continue # Skip corrupted block
# Detect missing blocks
if expected_sequence is not None:
if header.sequence_num != expected_sequence:
log_warning(f"Gap detected: {expected_sequence} to {header.sequence_num-1}")
expected_sequence = header.sequence_num + 1
# Decompress based on version and flags
try:
if header.flags & FLAG_LZ4:
payload = lz4_decompress(payload)
varint_values = decode_varint_stream(payload)
absolute_values = reconstruct_deltas(varint_values)
record = msgpack.unpackb(absolute_values)
records.append(record)
except Exception as e:
log_error(f"Failed to decode block {header.sequence_num}: {e}")
continue
return recordsDelta State Management Across Blocks
Problem: Delta encoding maintains state (last value). If a block is lost, how do we reconstruct subsequent deltas?
Solutions:
Option A: Periodic baseline resets
// MCU side: Send absolute value every N samples
if (sample_count % BASELINE_INTERVAL == 0) {
encode_absolute(value); // Full value, not delta
reset_delta_state();
} else {
encode_delta(value);
}Option B: Include baseline in block header
typedef struct {
// ... standard fields ...
float temp_baseline; // Last known absolute value
uint16_t battery_baseline;
} TelemetryBlockHeader;Option C: Request retransmission
# Cloud side: Detect gap and request missing data
if detected_sequence_gap(current_seq, last_seq):
request_retransmit(device_id, last_seq+1, current_seq-1)
buffer_current_block() # Hold until gap filledRecommended approach: Combine A and B
- Periodic baselines limit error propagation
- Header baselines enable immediate recovery
- Small overhead per block
Design Principle
Error isolation > maximum compression ratio.
A pipeline that achieves 50× compression but fails catastrophically on single-bit errors is worse than one achieving 30× compression with graceful degradation.
Key guidelines:
- Keep blocks small (sub-1KB typically)
- Always include integrity checks (CRC minimum)
- Design for missing data, not just corrupted data
- Test recovery logic as thoroughly as compression logic
- Monitor block loss rates in production
Why This Matters at Hoomanely
Hoomanely builds systems where reliability matters more than raw throughput.
Our devices operate in challenging environments:
- Intermittent connectivity - Wi-Fi signal varies
- Power constraints - battery-operated, must last weeks
- Real-time requirements - session mapping can't be delayed
- Diverse deployment - homes, clinics, shelters with different networks
- Fleet scale - thousands of devices generating continuous telemetry
Telemetry Use Cases
Device health monitoring:
- MCU temperature, voltage rails, current draw
- Flash wear levels, RAM usage patterns
- Wireless signal strength, packet loss rates
Behavioral analytics:
- Feeding patterns (when, how much, how fast)
- Activity levels (motion sensor data)
- Environmental context (ambient temperature, humidity)
Predictive maintenance:
- Battery discharge curves (capacity degradation)
- Component failure precursors
Operational intelligence:
- Fleet-wide firmware version distribution
- Feature usage patterns
- Performance benchmarking across hardware revisions
All telemetry must be:
- Transmitted efficiently (minimize bandwidth costs)
- Stored economically (cloud storage at scale)
- Queryable quickly (real-time dashboards)
- Recoverable reliably (no silent data loss)
Impact of Compression Strategy
A well-engineered compression pipeline provides:
Economic benefits:
- Reduced cloud storage costs
- Lower network egress fees
- Decreased cellular data usage
- Smaller infrastructure footprint
Technical benefits:
- Improved battery life (less radio-on time)
- Reduced flash wear (fewer write cycles)
- Better real-time performance (less CPU spent on I/O)
- Enhanced debuggability (structured, recoverable data)
Operational benefits:
- Faster analytics queries
- Smoother dashboards
- Easier troubleshooting
- Confident scaling
Compression strategy reinforces core engineering values:
- Efficiency - Do more with less (power, bandwidth, storage)
- Introspectability - Preserve ability to debug and understand system behavior
- Resilience - Gracefully handle failure modes without cascading issues
- Predictability - Known performance characteristics under all conditions
- Scalability - Linear cost growth as fleet expands
Thoughtful telemetry compression is a fundamental enabler of reliable, maintainable, cost-effective IoT systems at scale.
Key Takeaways
MessagePack replaces JSON with compact binary serialization apply it first to eliminate text encoding overhead and preserve type information.
Delta encoding shrinks numeric variation ideal for time-series telemetry where consecutive values differ slightly.
Varint compresses integers efficiently variable-length encoding optimized for small values without heavy CPU requirements.
LZ4 provides dictionary-based compression best deployed at gateways where CPU and memory are available.
Layered compression outperforms single techniques each stage prepares data optimally for the next.
Recovery-friendly block design prevents cascading failures self-contained blocks with headers, checksums, and sequence numbers enable graceful degradation.
Design for failure isolation, not maximum compression slightly lower ratio with robust error handling beats maximum compression that fails catastrophically.
Apply techniques at appropriate system tiers MCUs handle MessagePack/delta/varint, gateways add LZ4 batching, cloud focuses on efficient decompression.



